Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео.
Парсинг страниц html с помощью модуля html.parser
Для парсинга web-страниц есть разные библиотеки. И мы будем к ним обращаться. Но есть и совершенно замечательный стандартный модуль html.parser. Вот сегодня мы им и займёмся.
Чтобы разбирать html-страницу, необходимо создать объект класса HTMLParser. У него есть целый набор методов, часть из которых запускается автоматически при отправке объекту текста html-страницы. Лишний раз подчеркнём, что парсинг с помощью данных инструментов прост и незамысловат.
Методы класса HTMLParser
- HTMLParser.feed() — передать объекту текст html.
- HTMLParser.close() — закрыть и обработать текст, содержащийся в буферах.
- HTMLParser.reset() — перевести объект HTMLParser в исходное состояние.
- HTMLParser.getpos() — возвращает номер текущей строки и смещение.
- HTMLParser.get_starttag_text() — возвращает текст последнего открытого тэга.
Переопределяемые методы класса HTMLParser
Переопределяемые методы вызываются автоматически при обработке текста html.
- HTMLParser.handle_starttag() — вызывается при встрече открывающего тэга.
- HTMLParser.handle_endtag() — вызывается при встрече закрывающего тэга.
- HTMLParser.handle_startendtag() — вызывается при встрече не закрывающегося тэга.
- HTMLParser.handle_data() — вызывается для текста внутри тэга.
- HTMLParser.handle_entityref() — вызывается для html мнемоник (начинаются с амперсанда &).
- HTMLParser.handle_charref() — вызывается для обработок юникод-символов.
- HTMLParser.handle_comment() — вызываются для обработки комментариев.
- HTMLParser.handle_decl() — вызывается для обработки DOCTYPE.
- HTMLParser.handle_pi() — обрабатывает инструкции по обработке.
- HTMLParser.unknown_decl() — обработка неизвестного объекта.
Переопределив указанные методы можно обрабатывать все объекты html.
Ниже представлен пример программы, осуществляющей простой парсинг html-страницы. Страница считывается из файла. Обращаю внимание, что если вы будете использовать конструктор то должны обязательно вызвать конструктор родительского класса HTMLParser.__init__(self). Переменная fl указывает методу handle_data() необходимость вывода содержимого тэга. В нашем случае мы хотим получить содержимое тэга с javascript-кодом.
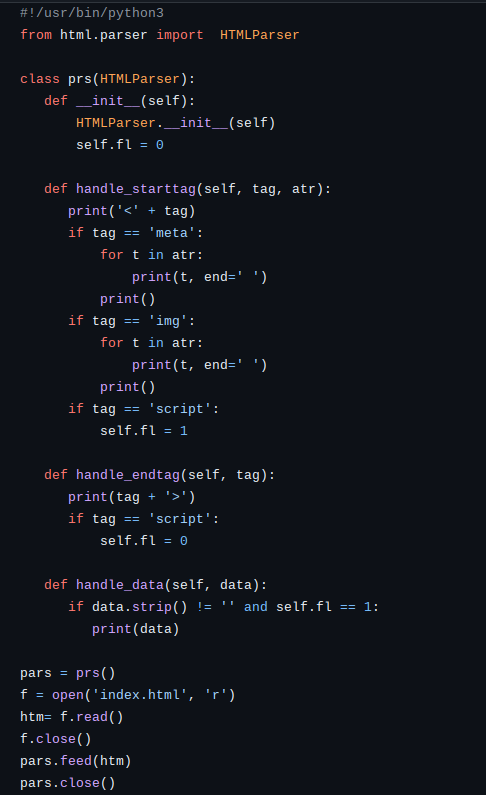
Результат разбора моей страницы, согласно представленной выше программы, таков
<html
<head
<title
title>
<meta
('http-equiv', 'Content-Type') ('content', 'text/html; charset=utf-8').
<link
head>
<body
<div
div>
<div
div>
<div
div>
<p
<img
('src', '1.jpg') ('width', '400') ('height', '450') ('alt', 'альтернативный текст').
img>
p>
<form
<input
<input
body>
<script
function fun(p)
{
window.location=p.value;
}
script>
html>
При желании анализ html-текста можно сколь угодно усилить. Согласитесь, что класс HTMLParser предоставляет хорошие возможности, гораздо лучше попыток использовать для этой цели регулярных выражений. В одной из следующих статей постараюсь привести пример парсинга реальной страницы.
См. также
Пишите свои предложения и замечания и занимайтесь программированием, хотя бы для поддержания уровня интеллекта.
