Публикую здесь некоторые отрывки из моей книги "Диалог о словах и языке". Полный текст книги см. по ссылке: https://vk.com/etimvk.
М.К. У меня возник вопрос к датировкам праязыков. Вот у археологов хотя бы имеется нечто материальное, какой-то артефакт, который можно подвергнуть радиоуглеродному анализу и понять, к какому времени он относится. Но язык – это не вещь какая-то. Как в принципе можно понять, когда существовал тот или иной праязык? Как лингвисты определили, что праиндоевропейский существовал в IV тысячелетии до нашей эры, а не раньше или позже?
А.М. Чтобы ответить на этот вопрос, мне необходимо будет ввести два новых термина: метод лексикостатистики и метод глоттохронологии. Если не вдаваться в детали, то можно считать оба метода идентичными, то есть это, по сути, синонимы. По названиям понятно, что речь идёт о некотором подсчёте слов для определения степени родства между исследуемыми языками и времени расхождения этих языков. Можно сказать, что это некий аналог радиоуглеродного анализа, только здесь определяется возраст языков, а роль радиоуглерода играют слова.
В середине 1950-х годов американский лингвист Моррис Сводеш предложил гипотезу, в соответствии с которой в любом языке существует так называемая «базисная лексика», обладающая относительной устойчивостью, то есть она может долго не вытесняться заимствованиями или родными словами с другими корнями. Это, например, существительные, связанные с природой (небо, земля, камень, ветер, вода, дерево, солнце, звезда, день, ночь), человеком (мужчина, женщина, сердце, голова, нога, глаз), родством (мать, отец, брат, сестра), всякой живностью (зверь, рыба, птица), а также простые местоимения (я, ты, мы), прилагательные (тёплый, холодный, старый, новый), глаголы (есть, пить, дышать, видеть, слышать, знать), числительные (один, два, три, четыре, пять), без которых нам трудно обойтись в обычной жизни. Заметь, что эти слова не связаны с какой-то конкретной культурой или особенностями местной жизни, то есть они известны всем людям (за редкими исключениями). Во многих близкородственных языках такие слова похожи. В тех коротеньких таблицах, которые я приводил, когда рассказывал об индоевропейских языках, были именно такие слова.
Если базовая лексика и вытесняется со временем (а мы знаем, что ничто не вечно), то происходит это крайне редко. По мысли Сводеша, такие слова должны вытесняться за определённый отрезок времени равномерно во всех языках – примерно по 14 слов из 100-словного списка за одну тысячу лет. Если эта гипотеза верна, то легко выяснить, сколько тысяч лет прошло с момента распада той или иной языковой общности, просто подсчитав количество выбывших слов из такого списка для пары языков.
Казалось бы, метод прекрасный, можно взять и построить точную генеалогическую классификацию языков и указать все датировки распада. Но не всё так просто. Сводеш сделал гениальное открытие, попытавшись применить математический аппарат радиоуглеродного анализа в лингвистике, однако его постулат о постоянности выбытия слов совсем не подтверждается. Если мы сравним скорость выбытия слов в исландском и норвежском (риксмол) языках, то обнаружится, что в исландском за тысячу лет выбыло всего 4 слова из 100-словного списка, а в норвежском – целых 20. Это означает, что исландский должен был выделиться где-то 200-300 лет назад, а норвежский – 1400 лет назад. Это явно противоречит тому, что мы знаем из истории: оба языка разделились примерно в одно время. Но такому расхождению есть своё логичное объяснение. Выше я уже говорил, что исландский язык консервативен, он не любит заимствовать, а вот норвежский подвергался колоссальному влиянию датского языка, поэтому 11 из 20 выбывших слов – это датские заимствования. Можно провести ряд других сравнений по выбытию слов и убедиться, что скорость выбытия различается от языка к языку. А если так, то модель не может считаться точной.
Увлечение глоттохронологией быстро сошло на нет, появилось много критиков Сводеша, которые справедливо отмечали недостатки его модели. Были на Западе лингвисты, которые пытались модифицировать метод Сводеша, но в целом безуспешно. Однако нашёлся в рядах советских лингвистов такой человек, который сумел просто и изящно разрешить большинство противоречий и построить обновлённую модель, демонстрирующую лучшие результаты. Этим человеком был Сергей Анатольевич Старостин, гениальный советский и российский лингвист, знаток большого числа языков. Его имя я уже называл, когда рассказывал о Московской школе компаративистики.
Во-первых, Старостин предложил исключить из вычислений заимствования и учитывать только подмены из того же языка; это позволило уменьшить скорость выбытия с 14 слов до 5-6 слов за тысячу лет. Во-вторых, он обратил внимание на то, что различные слова из 100-словного списка Сводеша обладают разной устойчивостью, то есть одни слова выбывают быстрее (например, качественные прилагательные, глаголы, некоторые названия природных явлений), другие – медленнее (например, личные местоимения, числительные). Эти и некоторые другие дополнения к принципам глоттохронологии Сводеша позволили Старостину произвести корректировку первоначальных формул расчёта и построить более точную (хотя и более сложную) модель. В дополнение ко всему этому Старостин предложил методику «корневой глоттохронологии», в соответствии с которой анализироваться должны не слова классического списка с общим значением, а общие корни.
Если тебе захочется получше узнать о методе глоттохронологии и наработках Сергея Старостина, то советую прочитать его статью «Сравнительно-историческое языкознание и лексикостатистика» в книге «Труды по языкознанию» (издательство «Языки славянских культур», 2007).
М.К. Если я всё правильно поняла, существует такой универсальный 100-словный список слов для всех языков, из которого очень медленно выбывают слова. Если для пары языков процент совпадений слов по этому списку высокий, то языки ближе друг к другу, а если невысокий, то они, соответственно, дальше друг от друга. Всё верно?
А.М. В целом всё верно. Только список не совсем универсален. Существуют списки, включающие разное количество слов: 30, 50, 100, 200. Некоторые учёные составляют свои списки (например, лингвист Сергей Евгеньевич Яхонтов пользовался 35-словными списками). Каждый из таких списков включает все те же базовые слова, но чем меньше список, тем более устойчивыми они должны быть.
М.К. Ты выше приводил коротенькие списки, включавшие следующие слова: я, ты, один, два, три, мать, отец, голова, сердце, вода, солнце. Они являются самыми «базовыми»?
А.М. Нет, эти слова я приводил просто для примера. На самом деле есть такие языки, в которых система числительных включает только понятия «один», «два» и «много», то есть число «три» есть не во всех языках. И этот, казалось бы, маленький факт уже не делает список универсальным. Хотя в целом именно такие и некоторые другие слова входят в число наиболее устойчивых.
М.К. А можешь привести список других базовых слов для языков разной степени родства, чтобы я смогла увидеть принцип лексикостатистики и глоттохронологии в действии? Ну, скажем, для русского, польского (славянского), литовского (балтийского), немецкого (германского) и французского (романского) языков. Если славянские и балтийские языки более близки, то я предполагаю, что между ними я увижу больше совпадений, но с немецким и французским их будет чуть меньше.
А.М. Всё правильно. Причём, с польским языком будет наибольший процент совпадений, с литовским – чуть меньше, с немецким – ещё меньше, с французским – самый маленький.
Посмотри на следующую таблицу. В ней даны соответствия для 20 русских слов, которые относятся к перечню базовых, и их переводы на те языки, которые ты назвала. Попробуй посчитать, сколько совпадений с русским в каждой колонке.
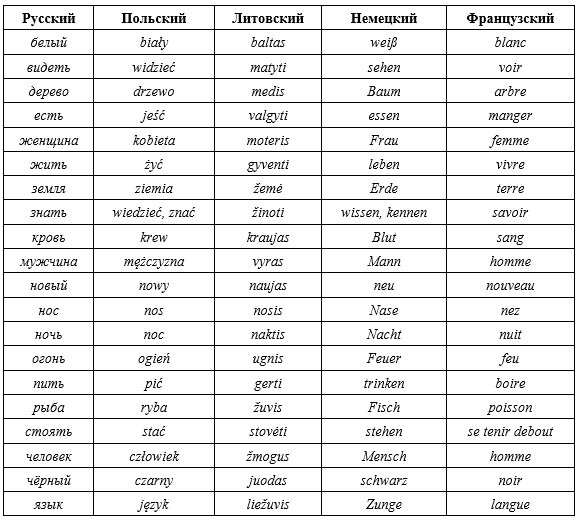
М.К. Ох, трудную ты мне задачку задал. Я мозг перегрела, кажется. Для русского и польского я насчитала 19 совпадений, для русского и литовского – 10, для русского и немецкого – 5, для русского и французского – 3. Всё правильно?
А.М. Молодец, почти справилась. Давай теперь разбираться. Я соглашусь с твоими подсчётами для русского и польского, там, действительно, 19 совпадений. Какое слово в польском явно отличается от русского аналога?
М.К. Это слово kobieta «женщина». Также отличается польское слово wiedzieć «знать» (вероятно, родственно русскому ведать). Остальные слова очень похожи, поэтому в них я ошибиться не могла.
А.М. Всё верно. Вот только с остальным ты немного ошиблась. Какие совпадения ты отыскала для оставшихся языков?
М.К. Совпадения с литовским: белый и baltas, жить и gyventi, земля и žemė, знать и žinoti, кровь и kraujas, новый и naujas, нос и nosis, ночь и naktis, огонь и ugnis, стоять и stovėti. Половина совпадений – это, думаю, довольно много, хотя сам литовский язык я бы вряд ли поняла.
С немецким совпадения следующие: есть и essen, новый и neu, нос и Nase, ночь и Nacht, стоять и stehen. С французским: новый и nouveau, нос и nez, ночь и nuit. Может быть, французское blanc как-то связано с русским белый, но в этом у меня нет уверенности.
А.М. Большинство совпадений ты обнаружила, но есть в этом списке такие родственные слова, которые без специальной подготовки вряд ли тебе бы удалось найти. Со временем сходства между ними практически исчезли.
Некоторые похожие слова тебя могут ввести в заблуждение. Например, русское белый не связано с французским blanc. Последнее унаследовано французским из народной латыни, куда оно было заимствовано из германского франкского языка. В конечном счёте это слово происходит из прагерманского *blankaz «светлый, яркий», которое родственно праславянскому *blěskъ, откуда русское блеск.
Родственными являются в этом списке русское видеть и французское voir (от латинского videō «видеть»); сюда же немецкое wissen «знать» и русское ведать. Родственны русское жить и французское vivre (от латинского vīvō «жить»); русское знать и немецкое kennen; русское мужчина и немецкое Mann; русское пить и французское boire. Наконец, родственны все четыре последних слова в списке: русское язык, польское język, литовское liežuvis, немецкое Zunge и французское langue.
Если мы заново пересчитаем наши совпадения с учётом всего этого, то получается, что между русским и литовским будет 11 совпадений, между русским и немецким – 8, между русским и французским – 7.
М.К. Вот это да! То есть многие соответствия я просто не смогла разглядеть из-за того, что со временем слова сильно изменились! Я как-то не учла этого. Стало быть, тут нам пригодились бы эти самые таинственные фонетические закономерности, которые ты всё никак не хочешь раскрывать?
А.М. Да, здесь ты недосчиталась именно потому, что тебе не известны эти самые пресловутые фонетические закономерности (в случае с соответствиями для русского слова язык всё ещё интереснее и сложнее). Но я обещал, что мы их обязательно рассмотрим отдельно и, наверное, вернёмся к некоторым примерам из таблицы. А пока продолжим как-нибудь без погружения в дебри исторической фонетики.
М.К. Знаешь, я очень удивлена и поражена. Мне кажется, я прикоснулась к чему-то очень магическому и сложному, чего я ещё не могу понять. Все эти похожести и непохожести – это очень привлекает в сравнительно-историческом языкознании. Наверное, многие пришли в эту науку, поддавшись такой магии слов.
А.М. Возможно, ты права. Не так интересно иногда было учить языки, как отыскивать совпадения в лексике, удивляясь тому, насколько всё-таки похожи многие из них, если получше приглядеться. А если вооружиться научным знанием, то можно заглянуть ещё глубже в историю слов, понять, почему они изменяются, исчезают, появляются. Нам ещё о многом предстоит поговорить.
М.К. И современные компаративисты, надо полагать, целыми днями исследуют такие списки, считают эти совпадения и кайфуют от этой магии?
А.М. И да и нет. На самом деле, компаративисты сравнивают языки и определяют время расхождения языков несколько иначе. Они задействуют сложный математический аппарат, а не просто считают, сколько слов похожих, а сколько – различных. Мы лишь «пощупали» принцип, поняли суть, но не касались самой математики.
Конечно, многие компаративисты кайфуют от своей работы, особенно когда им удаётся отыскать что-то новое, сравнить малоизвестные языки и определить их родство лексикостатистическим методом. Но это очень напряжённая работа.