Java интересен не каким-нибудь необычным синтаксисом, а своим изначальным подходом.
Предыдущая часть:
Во-первых, Java работает в виртуальной машине. Он не пионер в этой области, но первый, кто популяризовал технологию.
В чём суть? Виртуальная машина это программный комплекс, который программным же способом моделирует некий процессор и его команды. Работа виртуального процессора конечно же всё равно выливается в работу реального процессора. Можно сказать, что мы имеем дело с интерпретатором, который читает некие абстрактные машинные коды и переводит их в коды конкретного железного процессора.
Так что, в зависимости от терминологии и нашей точки зрения, интерпретатор Бейсика тоже в некотором роде виртуальная машина,

но разница в том, что Бейсик интерпретирует из языка высокого уровня, а виртуальная машина – из низкоуровневневых псевдо-машинных кодов. Таким образом, она эффективнее обычного интерпретатора.
Поэтому у Java есть компилятор. Он переводит файлы, написанные на высокоуровневом языке, в так называемый байт-код, который приближен к машинному коду. И вот этот байт-код уже исполняется в виртуальной машине.
Выгода тут простая: переносимость. Программы на C или Паскале надо перекомпилировать и зачастую дополнительно адаптировать под другие архитектуры процессоров или операционные системы. А однажды скомпилированный байт-код будет работать везде, где может работать виртуальная Java-машина. Конечно, это требует установки Java-машины в систему.
JIT
Со временем разработчики виртуальной машины заметили, что некоторые части байт-кода исполняются (то есть переводятся в настоящий машинный код) очень часто. И подумали: а почему бы эти части не оставить уже переведёнными в настоящий машинный код, пока работает программа? Так появились компиляторы JIT (Just In Time, или Прямо Когда Надо). В общем, виртуальная машина после запуска программы следит за тем, какие куски кода вызывают наибольшую нагрузку, и когда вычислит такие куски, то прямо на лету компилирует их, чтобы в дальнейшем они уже не интерпретировались, а работали как родные. Таким образом достигается существенный рост производительности и программы начинают работать практически с максимально возможной скоростью.
ООП
Java создавался как строго ООП-ориентированный язык. Если новичок при изучении языка C видит вот такие непонятные вещи:
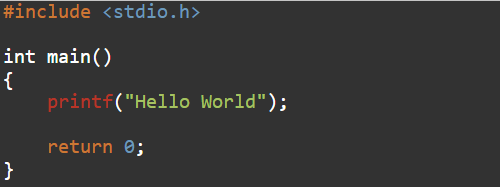
То при изучении языка Java он увидит ещё более непонятные вещи:
Хотя по структуре подозрительно похоже, и да, Java кое-что позаимствовал у C. Если в C функция main() это точка вызова главной программы, то у Java main() это статический метод класса Main, который также является точкой вызова главной программы.
Если вы привыкли к процедурному стилю программирования, то с Java вам придётся его полностью забыть. Здесь есть только классы и методы классов. Вы не можете написать какую-нибудь функцию просто так, вы должны поместить её в какой-то класс.
В Java, можно сказать, эталонная реализация принципов ООП. В других языках, таких как Бейсик, Си, Паскаль, PHP, внедрение ООП происходило в уже существующую базу, и поэтому местами выглядит как кособокая пристройка на костылях. В Java же всё сразу было стройно и красиво. Однако именно это привело к избыточности многих конструкций. К примеру, тот же
System.out.println("Hello World");
Что такое println(), мы вроде как понимаем. Но эту функцию нельзя вызвать из ниоткуда, так как всё находится в классах. Поэтому имеем класс System, в котором статическое поле out это объект класса PrintStream, в котором уже есть метод println().
Аналогично будут обёрнуты, скажем, методы работы с файлами.
Здесь вначале создаётся FileReader, который затем обёртывается в BufferedReader, у которого затем вызывается метод readLine(). Обратим внимание, что очень многие методы в Java бросают исключения и поэтому обязывают вас (да, именно обязывают) заключать их в блок try..catch.
Сборщик мусора
При всём своём C-подобном синтаксисе Java напрочь оторвался от корней, потому что имеет встроенный менеджер памяти со сборщиком мусора. Это позволяет программисту забыть о проблемах выделения и освобождения памяти. Нужно сложить две строки – нет проблем, бери и складывай. Однако именно поэтому в вышеприведённом примере чтения из файла присутствует класс StringBuilder. Дело в том, что если просто читать строки из файла и складывать, работать это будет очень медленно, так как строка при складывании пересоздаётся. А это значит, старая память освобождается, новая выделяется, и т.д. Класс StringBuilder позволяет накапливать в себе строки, а затем, уже в конце, сложить их все воедино.
Как видим, некоторые вещи изобретены просто как борьба со злом.
Структуры данных
В Java очень много структурированных коллекций со стандартизированными именами, которые отражают их устройство. Например, есть абстрактный класс Set, то есть множество. И есть его реализации HashSet и ArraySet. Первая это множество на основе хэш-таблицы, второе это множество на основе массива. Аналогичным образом есть различные варианты векторов, списков, хэшмапов, деревьев и пр., уже всего не помню.
Для чего такое разнообразие? Если вы метите на позицию Java-разработчика, то скорее всего вас будут гонять именно по коллекциям. Зная, на основе какой структуры данных реализована коллекция, вы должны понимать, в каких случаях она будет наиболее эффективно работать. Сколько будет стоить операция добавления или удаления элемента, сколько будет стоить операция поиска элемента, сколько оптимально элементов там хранить, как первоначально инициализировать и т.п.
Тот же файл можно прочитать кучей способов, используя FileReader, Scanner, Files или InputStream.
Поэтому, несмотря на всю высокоуровневость языка, Java-разработчик должен хорошо понимать, что и как работает у него под капотом, чтобы эффективно на нём писать.
JAR
Модульность программы в Java достигается довольно легко. Код размещается в файлах по принципу "один класс – один файл", и файлы называются так же, как классы. Вы можете сделать иерархию классов в виде структуры каталогов.
Всё это после компиляции можно запаковать в один файл с расширением .jar (Java это кофе, соответственно jar это банка для кофе).
Далее файлы .jar можно использовать автономно или подключать к другим проектам.
Синтаксис
Java имеет синтаксис, максимально похожий на C, поэтому никаких проблем для знающих С не будет (ну, кроме того, что всё делается через ООП). И да, там тоже можно выстрелить себе в ногу, сделав присваивание в условном операторе:
В Java нет указателей, как в C, но в связи с тем, что кроме примитивных типов int, char, float и т.д. все остальные это объекты, указатели и не нужны. Каждая переменная, ссылающаяся на объект, по умолчанию уже работает как указатель.
Дженерики
Не знаю, где они впервые появились, но так как в предыдущих частях я про них не писал, то напишу здесь на примере Java.
Дженерики нужны, чтобы лучше гранулировать типы в сложных структурах данных и методах. Например, посмотрим такой код:
Здесь мы создаём объект класса Vector и передаём его в метод test(), который также ожидает на входе параметр класса Vector. Java это строго типизированный язык, поэтому в данном случае всё будет работать, а если мы передадим в метод не объект класса Vector, а что-то другое, то соответственно работать не будет.
Однако что делать, если класс Vector внутри себя может содержать другие классы? Например, мы можем сделать вектор, состоящий из целых чисел, или из строк. Как тогда объяснить методу, что параметром должен быть именно вектор, состоящий из строк, а не какой попало?
Для этого мы добавляем дженерик-параметр к описанию вектора и к параметру метода:
Тем самым мы пояснили, что вот этот вектор должен содержать только строки. Поэтому при попытке передать не такой вектор в метод test() возникнет ошибка компиляции. Также она возникнет, если в данный вектор попробовать добавить не строку.
В связи с тем, что в комментах меня начали поучать, поясню.
Дженерик это от слова "generic", то есть обобщение, а где же оно, если мы вроде наоборот конкретизируем тип? Само обобщение происходит в описании того же класса Vector<T>, где вместо <T> подразумевается любой тип. Вот оно:
То есть получается обобщённое описание класса Vector, который может содержать любой тип <T>. Это <T> далее используется в методах класса везде, где надо подставить тип. Это генерализация, но со стороны описания. Со стороны использования мы как раз конкретизируем обобщённый тип <T> своим конкретным типом.
Рефлексия
Это фишка Java (но не только, она присутствует в других языках тоже), которая позволяет программе "вглядеться в себя" и получить сведения о наличии каких-либо классов, а также информацию о том, какие поля и методы есть у этих классов. Например, мы можем попробовать исследовать класс с именем Test:
С помощью метода Class.forName("Test") мы получаем сам класс (если он найдётся, конечно), а далее с помощью метода getDeclaredMethods() получаем список методов, объявленных в этом классе. Но как я и говорил, в этом нет ничего особо уникального, так что можно будет уделить этому больше внимания в обзоре какого-то другого языка.
Заключение
- Java – превосходный язык для тех, кто хочет разобраться в ООП
- Java-классы сильно абстрагированы и завёрнуты во много слоёв, что порождает избыточность кода, но такова цена за ООП
- Есть большое количество способов сделать задачу с помощью разных классов, вопрос лишь в эффективности полученного решения
- Написал однажды – работает везде (* где есть Java-машина, ** версия Java-машины не слишком разная, увы, ах, версий было уже много)
- Java-программист должен серьёзно учить алгоритмы, оценки алгоритмической сложности и структуры данных – что только пойдёт ему на пользу
Читайте дальше: