Особый случай номер один: Leonardo AI

Как работает img2img: генерация картинки по картинке в нейросетях. Часть 1
Продолжаем изучать генерацию изображений нейросетями методом "картинка в картинку", то есть с использованием вводных изображений, а не только текстового запроса. В первой части материала, ссылка на которую дана вверху, уже выяснилось, что: а) делать это умеют не все нейросети (или некоторые умеют, но не признаются), б) общий принцип работы режима img2img везде одинаков, но в) результаты получаются иногда совершенно разными.
На примере многострадальной "Девушки с жемчужной серёжкой" стало хорошо заметно, что, скажем, изменить возраст человека на портрете, при этом оставив его узнаваемым, — сложная задача, с которой справляются не все модели. В прошлый раз точнее всего это получилось у Playgroundai. Но в целом лучшие результаты изо всех испытанных мной нейросетей показал Leonardo AI, а точнее, — его модель AlbedoBase XL на основе Stable Diffusion XL. Она исключительно хорошо воспринимает текстовые описания и способна убедительно изображать основные различия между возрастами (особенно если дополнять описания уточнениями вроде "очень морщинистое лицо"). При этом она очень бережно относится к оригиналу и старается сохранить так много исходных черт, как только можно.
Именно благодаря такой понятливости мне удалось сгенерировать достаточно вариантов портрета Вермеера (всего их было 20), чтобы из них можно было составить связное видео взросления и старения человека.
Собственно говоря, Leonardo стал даже слишком понятлив. Настолько, что никакие настройки ему теперь не указ.
img2img на платформе Leonardo AI
Если вы работаете с Leonardo AI уже какое-то время или читали в этом блоге статьи о работе в нём, то вы можете знать, что инструменты для генерации картинки по картинке находятся в интерфейсе слева, в самом низу боковой панели настроек.
Вернее, находились до недавнего времени. И работали точно так, как было описано до этого — как во всех остальных моделях. Но недавно кое-что изменилось.
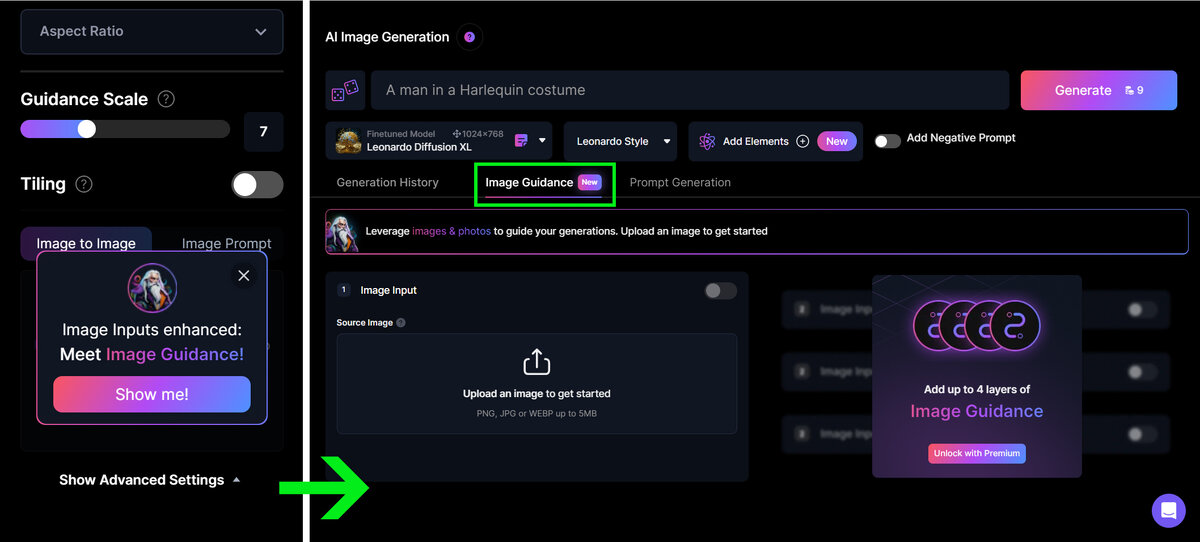
На месте поля для загрузки изображения в боковой панели появилось объявление о переезде. Метод Image to Image в Leonardo называется теперь Image Guidance, и добраться до его настроек можно через новую вкладку, расположенную между вкладками Generation History (История генераций) и Prompt Generation (Генерация запроса) сразу под названием модели и добавленных элементов в основном рабочем окне.
Главное нововведение, впрочем, мне придётся пока так и оставить неиспытанным, поскольку оно открывается строго по подписке, то есть за плату. Суть его в том, что теперь в Leonardo AI можно одновременно использовать до четырёх вводных изображений: основной объект может быть взят из одного, глубина резкости — из другого, контраст — из третьего, а, скажем, поза — из четвёртого. Всего же таких параметров (по состоянию на момент выхода статьи) может быть десять, если вы используете непремиальную модель (то есть не основанную на SDXL и не включающую Alchemy v2):
Их остаётся всего пять, четыре из которых недоступны без оплаты, если используемая модель — премиальная. К таким сейчас относятся SDXL 0.9, Leonardo Diffusion XL, Leonardo Vision XL и AlbedoBase XL:
Но все эти параметры я сейчас оставлю за бортом, потому что они, строго говоря, относятся к отдельной теме протокола ControlNet и поэтому заслуживают отдельного разговора. Пока могу сказать, что, если вы пользуетесь телеграм-ботом "Кандинского", то уже наверняка немного знакомы с ControlNet на практике. Перенос стиля в "Кандинском" — это как раз одно из применений протокола.
Параметр Strength
А пока вернёмся к простой генерации картинки по картинке. Здесь как раз и начало проявляться самоуправство Leonardo. Выражается оно в том, что нейросеть совершенно не реагирует на перемещения ползунка Strength. То есть модель сама решает, насколько итоговое изображение должно быть похожим на оригинал, и в каких именно местах она будет вносить изменения. Пользователь не имеет никакой возможности контролировать результат, кроме как изменяя текстовое описание либо выбирая генеративную модель, которая изменит стиль картинки под свои стандарты. Но Strength не работает везде одинаково, независимо от модели.
Я могу сколько угодно двигать ползунок, но результаты омоложения девушки с жемчужной серёжкой не изменятся:
Кстати, на шкале Strength на платформе Leonardo минимальное значение составляет 0,1, а максимальное - 0,9. Не то чтобы это на что-то влияло.
Единственное, что оправдывает в моих глазах такое поведение нейросети — то, что результаты получаются действительно хорошими. И ещё: я допускаю, что это неповиновение временное, объясняется простым недосмотром разработчиков, и в ближайшем будущем Leonardo снова начнёт реагировать на смену настроек. Если такое произойдёт, я постараюсь вовремя это заметить и сообщить вам.
А пока для полного раскрытия темы вот результаты превращения котика в пёсика и в плюшевого медведя. Запросы использовались те же самые, что и в первой части статьи:
Размер имеет значение
Ещё одна особенность, отличающая генерацию картинки по картинке в Leonardo, состоит в следующем. Стоит внимательно следить за соответствием пропорций вашего исходного изображения пропорциям, на которых обучалась выбранная генеративная модель. Если ИИ заметит несоответствие, вас предупредят об этом жёлтыми треугольными значками:
При этом важнее для вас то предупреждение, которое расположено под загруженной картинкой. Если его проигнорировать, результат генерации может получиться примерно вот таким:
Чтобы исправить ситуацию, достаточно кликнуть на квадратный значок слева от предупреждающего треугольника: размеры итогового изображения будут подогнаны под исходник. При этом предупреждение в боковой панели может сохраняться (или даже появиться, если его до этого не было), но в этой ситуации из двух зол надо выбирать меньшее. В идеале, конечно, стоит так подбирать исходную картинку и генеративную модель, чтобы пропорции первой совпадали с тренировочными размерами второй, но это не всегда возможно.
Вот, пожалуй, и всё важное, что стоит знать о генерации img2img в Leonardo AI. В следующий раз доберёмся и до "Кандинского", а заодно нащупаем пределы возможностей метода img2img.