Программа STATISTICA позволяет применять четыре варианта t-критерия:
- критерий для независимых выборок по группам (t-test, independent by groups);
- критерий для независимых переменных (t-test, independent by variables);
- критерий для зависимых выборок (t-test, dependent samples);
- критерий для одной выборки (t-test, single sample).
Чтобы посмотреть, как реализуется в программе STATISTICA оба t-критерия для независимых переменных, возьмём пример из книги С. Гланца «Медико-биологическая статистика».
Стоимость пребывания в больнице — одна из весомых статей расходов на здравоохранение. Позволяет ли правильное лечение сократить срок госпитализации? Если можно было бы сократить срок госпитализации без снижения качества лечения, то это привело бы к значительной экономии бюджетных средств. Способствует ли соблюдение официальных схем лечения сокращению госпитализации? Чтобы ответить на этот вопрос, Knapp и соавт. изучили истории болезни лиц, поступивших в госпиталь с острым пиелонефритом («Relationship of inappropriate drug prescribing to increased length of hospital stay», 1979).
Острый пиелонефрит характеризуется чёткой клинической картиной, для его лечения применяют столь же чётко регламентированные методы. Knapp и соавт. сформулировали следующие критерии включения в исследование:
1. Диагноз при выписке — острый пиелонефрит;
2. При поступлении — боли в пояснице, температура выше 37,8 °С;
3. Бактериурия более 100 000 колоний/мл, определена чувствительность к антибиотикам;
4. Возраст от 18 до 44 лет;
5. Отсутствие почечной, печёночной недостаточности, а также заболеваний, требующих хирургического лечения;
6. Больной был выписан в связи с улучшением (т. е. не покинул больницу самовольно, не умер и не был переведен в другое лечебное учреждение).
За «правильное лечение» принималось то, которое соответствовало рекомендациям авторитетного справочника по лекарственным средствам «Physicians’ Desk Reference» («Настольный справочник врача»). По этому критерию больных разделили на две группы: леченных правильно (1-я группа) и леченных неправильно (2-я группа). В обеих группах было по 36 больных.
Применение t-критерия для независимых выборок позволяет проверить гипотезу о том, что средние значения двух выборок отличаются друг от друга.
В программе STATISTICA реализовано два способа сравнения данных t-тестом для независимых выборок, и они основаны на обработке двух разных матриц данных: а) по группам (by groups) - в таблице с данными есть группирующая переменная и б) по переменным (by variables) - данные внесены в самостоятельные столбцы. В этой статье рассмотрим только вариант оформления таблицы а) по группам (by groups).
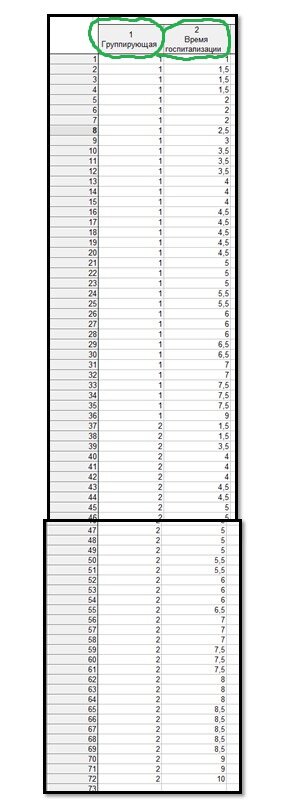
Данные о времени госпитализации в нашем примере представлены в виде таблицы с группирующей переменной. Сразу отметим, что группирующая переменная должна быть дискретной и иметь две градации: в нашем примере это обозначения «1» и «2», которые соответствуют двум группам больных - леченных правильно («1») и неправильно («2»).
В этом случае мы применяем t-критерий для независимых выборок по группам (t-test, independent by groups). Для этого необходимо использовать следующую последовательность команд: нажать на вкладку Statistics (Статистики), найти строчку Basic Statistics and Tables (Основные статистики и таблицы). Нажать на неё.
Из открывшегося списка выбрать пункт t-test, independent by groups (t-критерий для независимых выборок по группам).
В результате этого мы увидим диалоговое окно с нашим t-test, independent by groups. Сверху мы видим кнопку Variable, нажав на которую мы переходим в специальное поле с двумя столбиками: слева необходимо указать зависимую переменную (Dependent), а справа - группирующую переменную (Grouping). В качестве Grouping variable указываем «1. Группирующая» с нашими условными обозначениями «1» и «2». Напоминаю, что это леченные правильно («1») и неправильно («2»). В качестве Dependent variable указываем значения - «2. Время госпитализации».
Под блоком с Variabl'ами мы можем увидеть 3 вкладки: Quick, Advanced и Options. Пока отметим Quick, всё остальное рассмотрим позднее.
Итак, мы выбрали переменные, и можем заметить, что STATISTICA правильно поняла, что две группы пациентов мы обозначили именно как «1» и «2»😊
Теперь нажимаем кнопку Summary или Summary T-tests, и видим результаты вычисления t-критерия:
Что есть что в получившейся таблице? Слева направо:
- Mean 1 и Mean 1 - средние значения в каждой группе («1» и «2»);
- t-value - собственно, значение t-критерия Стьюдента;
- df - число степеней свободы;
- p - уровень статистической значимости результатов, который должен быть p ≤ 0,05. В нашем случае он значительно меньше;
- Valid N 1 и Valid N 1- объем каждой выборки («1» и «2»);
- Std. dev.1 и Std. dev.2 - стандартное отклонение для каждой выборки;
- F-ratio, Variances - значение F-критерия Фишера, с помощью которого проверяется гипотеза о равенстве дисперсий в сравниваемых выборках;
- p, Variances- вероятность справедливости гипотезы о том, что дисперсии сравниваемых выборок не различаются.
Таким образом, мы можем говорить о том, что 36 пациентов, леченных правильно («1»), имеют среднее время госпитализации 4,569444 дней, и 36 пациентов, леченных неправильно («2»), имеют среднее время госпитализации 6,277778 дней. Различия в средних сроках госпитализации статистически достоверны на высоком уровне значимости (p = 0,000786). Значение t-критерия Стьюдента составляет -3,51101. Значение F-критерия Фишера составляет 1,056149, и дисперсии двух распределений статистически значимо не различаются (p = 0,872539), следовательно, применение t-критерия в данном случае корректно.
Напоследок о том, что можно визуально оценить степень зависимости между группирующей и зависимой переменными. Это делается с помощью диаграмм размаха (она же коробчатая диаграмма, она же диаграмма "Ящик-усы").
Для того, чтобы на экран была выведена диаграмма необходимо щёлкнуть на кнопке Box & whisker plot, которая расположена под кнопкой Summary T-tests.
После этого на экран выводится наш ящик с усами.