Авторы Шанбин Фэн, Чан Янг Пак, Юхан Лю, Юлия Цветкова
Резюме
Языковые модели (LM) предварительно обучаются на различных источниках данных, включая новости, обсуждения на форумах, книги и онлайн-энциклопедии. Значительная часть этих данных включает мнения и точки зрения, которые, с одной стороны, прославляют демократию и разнообразие идей, а с другой стороны, по своей сути являются социально предвзятыми. Данная работа разрабатывает новые методы измерения политических предубеждений у LM, обученных на таких корпусах, по социальным и экономическим осям, а также измерения справедливости нижестоящих моделей НЛП, обученных на основе политически предвзятых LM. Авторы фокусируются на разжигании ненависти и обнаружении дезинформации, стремясь эмпирически количественно оценить влияние политических (социальных, экономических) предубеждений при предварительной подготовке данных о справедливости социально-ориентированных задач с высокими ставками. Наши результаты показывают, что предварительно обученные LM действительно имеют политические пристрастия, которые усиливают поляризацию, присутствующую в предварительно обученных корпусах, распространяя социальные предубеждения в предсказаниях языка ненависти и детекторах дезинформации. Авторы обсуждают последствия выводов данной работы для исследований НЛП и предлагают будущие направления для смягчения несправедливости.
Наборы данных для последующих задач
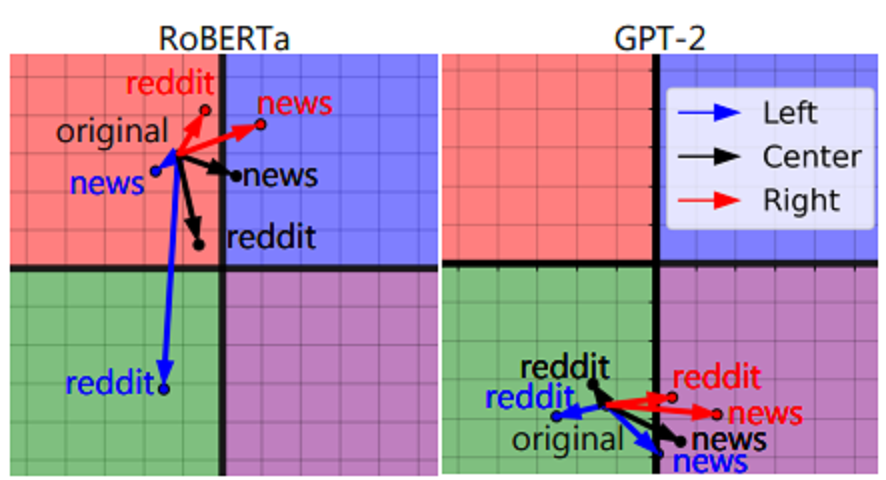
Авторы исследуют связь между политическими предубеждениями моделей и их последующим поведением в двух задачах: разжигание ненависти и обнаружение дезинформации. Для обнаружения разжигания ненависти авторы используют набор данных, представленный в Yoder et al. (2022), который включает примеры, разделенные на целевые группы идентичности. В этой работе авторы используют два официальных разделения наборов данных: HATE-IDENTITY и HATEDEMOGRAPHIC. Для выявления дезинформации принят стандартный набор данных PolitiFact (Wang, 2017), включающий источник новостных статей. Авторы оценивают RoBERTa (Liu et al., 2019) и четыре варианта RoBERTa, предварительно обученные на корпусах REDDIT-LEFT, REDDIT-RIGHT, NEWS-LEFT и NEWS-RIGHT.
Результаты и анализ
Сначала оценивается внутренняя политическая направленность языковых моделей и их связь с политической поляризацией в корпусах предварительного обучения.
Затем оценивается предварительно обученные языковые модели с различными политическими взглядами на разжигание ненависти и обнаружение дезинформации, стремясь понять связь между политической предвзятостью в корпусах предварительной подготовки и проблемами справедливости в решениях задач на основе LM.
Политическая предвзятость языковых моделей
Политические пристрастия предварительно обученных LM На рисунке 1 показаны результаты политических пристрастий для различных предварительно обученных контрольных точек LM.
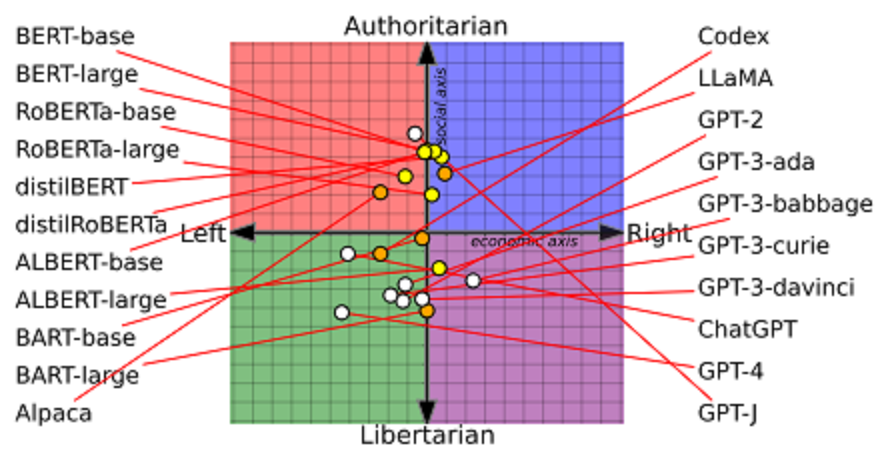
В частности, каждый исходная LM сопоставляется с социальной и экономической оценкой с помощью предложенной авторами схемой. По результатам исследований получается, что:
- Языковые модели демонстрируют различную идеологическую направленность, занимая все четыре квадранта на политическом компасе.
- Как правило, варианты модели BERT более социально консервативны (авторитарны) по сравнению с вариантами модели GPT. Это коллективное различие может быть связано с составом корпусов для предварительного обучения: в то время как BookCorpus играл значительную роль в раннем предварительном обучении LM, веб-тексты, такие как Common-Crawl и WebText стали доминирующими предтренировочными корпусами в более поздних моделях. Поскольку современные веб-тексты имеют тенденцию быть более либеральными (либертарианскими), чем старые книжные тексты, вполне возможно, что LM усвоили этот либеральный сдвиг в данных предварительного обучения. Такие различия также могут быть частично связаны с обучением с подкреплением с использованием данных обратной связи с человеком, принятых в моделях GPT-3 и более поздних версиях. Кроме того, аторы отмечают, что разные размеры одной и той же модельной семьи (например, ALBERT и BART) могут иметь существенные различия в политических пристрастиях. Предполагается, что это изменение связано с лучшим обобщением в больших LM, в том числе с переоснащением предубеждений в более тонких контекстах, что приводит к смещению политических взглядов. Здесь место для дальнейших исследований и будущей работы.
- Предварительно обученные LM демонстрируют более сильный уклон в сторону социальных вопросов (ось Y) по сравнению с экономическими (ось X). Средняя величина по социальным и экономическим проблемам составляет 2,97 и 0,87 соответственно при стандартных отклонениях 1,29 и 0,84. Это говорит о том, что предварительно обученные LM демонстрируют большее несогласие в своих ценностях в отношении социальных вопросов. Возможная причина заключается в том, что объем обсуждения социальных вопросов в социальных сетях выше, чем экономических, поскольку планка для обсуждения экономических вопросов выше, требующие базовых знаний и более глубокого понимания экономики.
Заключение
Авторы проводят систематический анализ политической предвзятости языковых моделей. Исследуют LM, используя подсказки, основанные на политической науке, и измеряют идеологические позиции моделей по социальным и экономическим ценностям. Они также изучили влияние политических предубеждений при предварительной подготовке данных на политические пристрастия LM и исследовали производительность модели с различными политическими предубеждениями на последующих задачах, обнаружив, что LM могут иметь разные стандарты для разных целей разжигания ненависти и источников дезинформации на основе их политических предубеждений.
Данная работа подчеркивает, что пагубные предубеждения и несправедливость в последующих задачах могут быть вызваны нетоксичными данными, которые включают в себя различные мнения, но в распределении данных есть тонкие дисбалансы.
В другой работе обсуждались методы фильтрации или дополнения данных в качестве средства правовой защиты (Kaushik et al., 2019); Хотя эти подходы полезны в теории, они могут быть неприменимы в реальных условиях, что может привести к цензуре и исключению из политического участия. В дополнение к выявлению этих рисков авторы обсуждают стратегии по смягчению негативных последствий при сохранении разнообразия мнений в данных предварительной подготовки.
Полностью статью на английском см. здесь