Друзья, открыла для себя интересный промт (текстовый запрос, по которому нейросеть генерирует картинки):
Photography, Portrait, Pin-up, Atmospheric, Luminous, Emotion, Colorful, Urban, Nightlife, Sensual
(Фотография, Портрет, Пинап, Атмосферный, Светящийся, Эмоции, Красочный, Городской, Ночная жизнь, Чувственный)
При его исследовании в нейросети Playgroundai получились интересные результаты, которыми хочу с вами поделиться.
Во-первых, хочу сразу предупредить, что нейросеть Playgroundai по этому запросу генерирует очень редко интересные изображения даже с применением фильтров во всех моделях, кроме Stabble Diffusion XL. Лучше использовать исходное изображение, которое загружается слева в поле <Image to Image>:
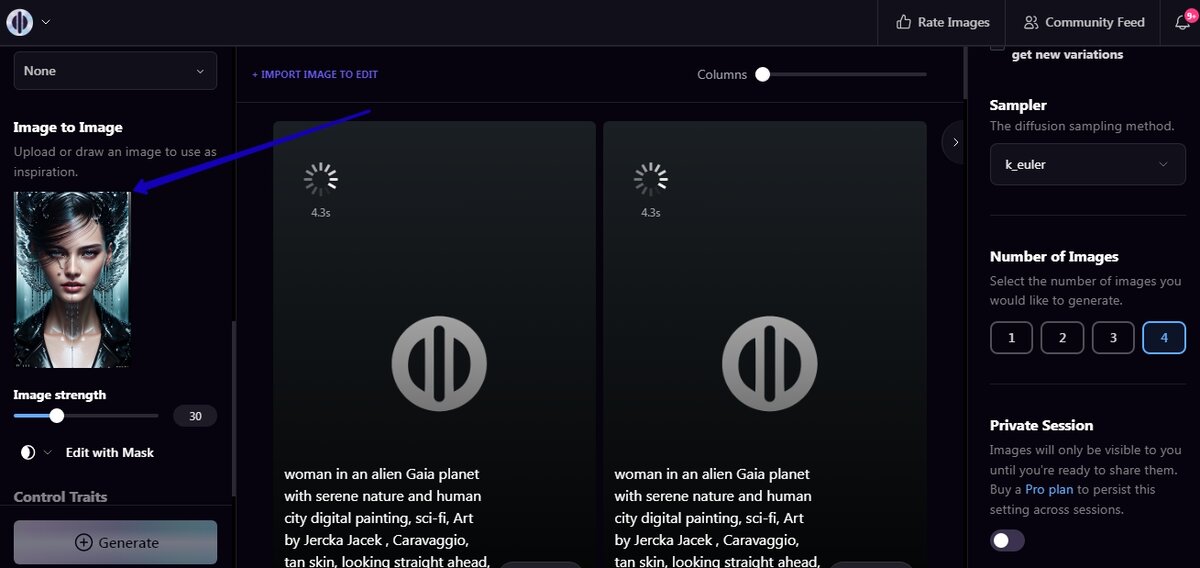
Для эксперимента я использовала вот эту картинку:

Для исследования запроса я применила следующие параметры:
Model: Playgroundai v1 (модель)
Image Dimensions: 512*768 (размеры картинки)
Promt Guidance: 15 (сила запроса: чем больше это значение, тем картинка ближе к запросу)
Quality Details: 50 (в бесплатной версии - это максимальное количество шагов)
Seed: Randomize each number to get new variations (рандомное число)
Sampler (алгоритм):
plms
ddim
k_euler
k_euler ancestral
k_heun
k_dpm_2
k_dpm_2 ancestral
k_lms
Number of Images: 4 (количество изображений)
Image strength: 33 (сила изображения)
Еще я вводила негативный промт. Его можно выбрать здесь:
Я использовала все алгоритмы (Sampler) в шести фильтрах, встроенных в нейросеть. Продемонстрирую, что у меня получилось в ходе эксперимента:
Фильтры:
1. Delicate detail (Тонкая деталь)
2. Lush illumination (Яркое освещение)
3. Cinematic (Кинематографический)
4. Spielberg (Спилберг)
5. Masterpiece (Шедевр)
6. Black and white (3D) (Черное и белое)
А теперь оцените вот эти изображения, созданные при тех же параметрах, при том же исходном изображении, но только при использовании другой модели - Stabble Diffusion XL:
В результате проведенного эксперимента у меня сложились свои предпочтения относительно стилевых фильтров, сэмплеров и моделей. Но, однако, однозначных выводов делать не стану, так как каждый случай индивидуален - многое зависит от промта и исходного изображения, которое берется за основу.
Друзья, экспериментируйте, делайте свои выводы. И, конечно же, делитесь ими в комментариях.
******************************************************************************************
P. S. Приглашаю всех желающих на бесплатный мастер-класс «Специалист по нейросетям»! За один день вы познакомитесь с несколькими нейросетями (ChatGPT, Midjourney, Claude, YandexGPT, GigaChat, Kandinsky) и узнаете, как стать востребованным специалистом с достойным доходом.
<<<<<< Регистрация на мастер-класс >>>>>>
После регистрации вы получите ПОДАРОК — PDF-книгу «10 способов заработка на нейросетях ChatGPT и Midjourney».