Наивное прогнозирование будущих значений временных рядов. Часть 1.
Перед тем как приступить непосредственно к написанию кода, давайте подробно распишем что и как мы будем вычислять и в каком порядке.
При любой работе с данными, первое что нужно сделать это проверить их на достоверность, полноту и отсутствие пропусков в данных. В нашем случае я использую данные достаточно высокого качества, и мы обойдемся без этого этапа. Но в своих задачах помните о необходимости верификации входящих данных.
После этого нам необходимо привести данные к нужному для нашего расчета виду. Мы, для нашего наивного прогноза предполагаем использовать шкалу времени в формате даты и цену закрытия дневного ценового бара.
Думаю, будет быстрее и проще привести данные к этому формату во внешней программе и преобразовать их в формат .csv
После того как данные будут подготовлены к исследованию их нужно будет определить в надежное и доступное место хранения. Что бы в любой момент времени эти данные могли бы быть использованы для контроля или другого исследования.
После этого мы должны экспортировать наш набор первичных данных в среду Colab Notebook, этот вопрос мы с вами уже разбирали ранее.
Теперь наши данные существуют в виде дата фрейма библиотеки Pandas. Эта форма представления данных организованна по типу хорошо знакомых вам таблиц Excel.
после этого мы можем приступать к нашим расчётам.
Нам нужно будет вычислить:
- скользящую среднюю для цен закрытия дня (период примем 30);
- отклонение цен закрытий дня от полученного ранее значения скользящей средней;
- скользящую среднюю для отклонения цен (период примем 7);
- с помощью линейной регрессии c периодом 5 предсказать следующее значение скользящей средней цен закрытия дня;
- с помощью линейной регрессии с периодом 3 предсказать следующее значение скользящей средней отклонения цен закрытия;
- сложив предыдущих два значения (предсказанное значение скользящей средней цен закрытия дня и скользящее среднее отклонения цен закрытия) получить прогнозное значение закрытия следующего дня;
- сравнить фактическое значение закрытия дня с его прогнозом.
Скользящие средние будем считать по самому простому алгоритму, как среднее суммы значений исторических данных направленное в прошлое на заданное количество периодов.
Линейную регрессию для предсказания следующего значения скользящей средней и отклонения цены закрытия от среднего значения рассчитаем по методу наименьших квадратов.
Все периоды скользящих средних и линейных регрессий взяты «по наитию» и скрытого смысла в себе не несут, модель то «наивная». 😊
Сам по себе метод наименьших квадратов, не смотря на свою простоту и популярность имеет весьма затейливую историю, достойную отдельного описания. Вкратце об истории его создания можно прочесть в Wiki.

А непосредственно вычислительная часть изложена вот в этом коротком видео.
Выполнив эти вычисления, мы получим ряд значений, который послужит нам в дальнейшем как некая мера, «опираясь» на которую мы будем иметь возможность оценивать эффективность более сложных моделей прогнозирования.
Хорошей привычкой является время от времени проверять свои вычисления в другой программе и сравнивать результаты.
В данном случае, помимо создания модели на Python я провел аналогичные вычисления в Excel и убедился в совпадении результатов.
Файл с расчетами в Excel можете скачать по этой ссылке.
Ребятам из клуба option LAFT будет доступен код на Python.
Ну и совершенно не логично было бы не провести количественную оценку результатов «наивного прогноза». Для этого была вычислена разница между прогнозным и фактическим значением, полученная цифирь была приведена к текущему размеру цен и уже в отношении этих полученных значений был проведен элементарный статистический анализ.
Для начала я построил график отклонения относительных величин наивного прогноза.
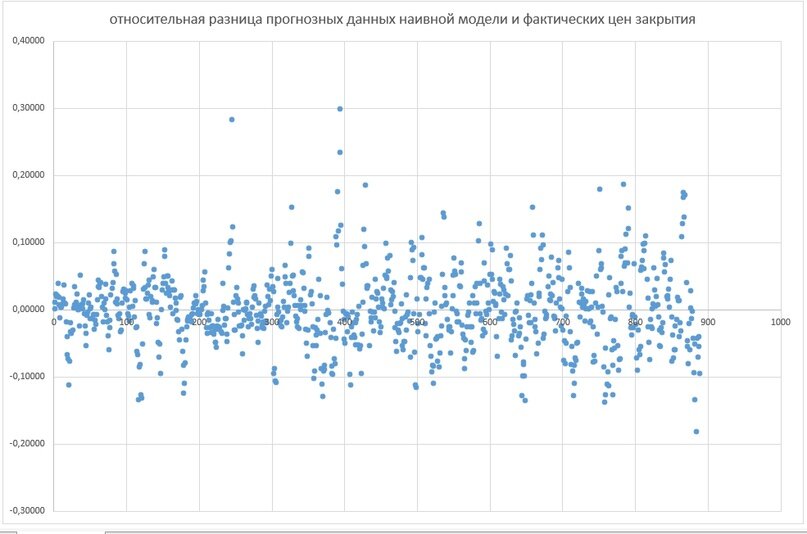
Тут мы можем приблизительно оценить на сколько наш наивный прогноз отличается от реальных данных (нулевая линия).
Ну и для пущего контроля было бы не плохо, посмотреть, как распределяется вероятность этих отклонений. По идее она должна напоминать Гауссиану. Построив гистограмму распределения, видим что это так и есть.
Ожидайте продолжения.