У всех компаний есть разнообразные данные: о клиентах, транзакциях, закупках, оборудовании, доходах и расходах. Но для одних компаний данные – драйвер роста, а другие несут убытки, полагаясь на них.
Почему так происходит и как сделать так, чтобы данные генерировали прибыль, а не убытки – в материале по итогам онлайн-встречи, которую эксперты Qlever Solutionsпровели в мае.
Какие данные стоят дорого?
Данные относятся к категории нематериальных активов и определить их фактическую цену в денежном выражении проблематично. Компании могут оценивать стоимость информации на основе экономического влияния, которое она оказывает на бизнес. А именно:
· Прибыль от обладания данными
Как правило, речь идет о той потенциальной выгоде, которую можно извлечь, применив данные, - удачно инвестировать, оптимизировать процессы и т.д. Иногда речь идет и о прямой прибыли от обладания данными, например, исследовательская компания может продать итоги своих исследований.
· Конкурентное преимущество от владения данными
Компания Netfix изначально была сервисом DVD-проката, которым в 2006 году пользовалось 6,2 млн абонентов. Благодаря этому у Netflix появилась огромная и максимально полная база данных клиентов, которую сервис использовал для касания с пользователями, когда начал запуск стриминговых сервисов.
· Оценки рисков, связанных с потерей данных
Согласно исследованию Qrator Labs, 71% респондентов из предприятий банковской сферы назвал утечку пользовательских данных одной из главных угроз. Для банка, как, впрочем, и для любой компании, утечка данных – это серьезный удар по репутации и риск потери клиентов.
Таким образом, данные могут быть действительно ценным активом. С одной оговоркой: ценность дает только высокое качество данных, низкое же напротив - создает издержки.
Если вы пошли в лес и набрали полную корзину ядовитых грибов, суп из них вас вряд ли порадует. Некачественные данные так же губительны для бизнеса, как для человека – ядовитая пища.
Сейчас в России уже сложилась традиция накопления корпоративных данных, но это скорее разрозненные массивы плохо структурированных и неполных сведений, чем стройные системы. Компании тратят значительные человеческие, временные и денежные ресурсы на поиск и обработку нужных данных в несовершенных информационных системах.
Топ типовых ошибок, из-за которых данные становятся некачественными:
• Ошибки в форматах данных, путаница в единицах измерения и форматах дат и времени, отчего данные становятся неупорядоченными.
• Формальное отношение сотрудниковк внесению исходных данных – причина появления неточных, неполных и неактуальных записей.
• Отсутствие или неполнота общих словарей;
• Дубликаты – создают неуникальные данные;
• Проблема перевода, например, как корректно перевести «ООО» – «ООО», «LLC», «Ltd» или «LLP»? Из-за этого возникают неточные и несогласованные данные.
• Отсутствие или недостаточностьаудита исторических данных (например, изменение юридического статуса контрагента) также способствует неуникальности данных;
• Проверка данных на возможность передачи во внешний мир (персональные и иные конфиденциальные данные).
Низкое качество данных = потеря денег
Поскольку все ключевые бизнес-процессы задействуют данные, ошибки и неточности в них расходуют ресурсы компании. Это могут быть оплачиваемые часы работы сотрудников, неликвид на складах, прямые убытки в виде штрафов, конфискаций или бракованных партий товаров, потеря клиентов из-за репутационных рисков.
Вот несколько конкретных примеров из разных отраслей.
1. Отрасль: финансы и кредит
Проблема: неоправданные трудозатраты
По результатам аудита было выявлено, что 1000 из 5000 сотрудников банка было занято подготовкой отчетов вручную и исправлением ошибок и несоответствий в справочниках.
2. Отрасль: ритейл
Проблема: излишки на складе
В крупной торговой филиальной сети в номенклатуре отсутствовал единый идентификатор. В одном филиале хранился «Втулка торсиона кабины», а в другом «Сайлентблок кабины». Компания несла расходы на хранение излишков на складе, а также доставку из отдаленных филиалов, хотя нужные позиции находились на более близком складе, но их не нашли в информационной системе.
3. Отрасль: логистика
Проблема: штрафы
Сотрудники международной логистической компании допусками ошибки при кодификации товаров по ТН ВЭД. Штрафы за неправильную кодификацию могли составить до 200% от неуплаченных пошлин с риском конфискации товара.
4. Отрасль: пищевая промышленность
Проблема: переделка партии товаров и репутационные риски
Ошибки в маркировке товаров влекут убытки из-за переделки партии упаковки или самого товара. Помимо прямых убытков это создает ущерб репутации бренда. От 50 до 70% ошибок маркировки – ошибки в данных, которых можно избежать нормализацией и автоматически проверяемыми стандартами.
Основные данные (НСИ)
Среди всех корпоративных данных выделяется большая группа относительно неизменных и постоянно используемых сведений, которая называется нормативно-справочная информация (НСИ) или основные данные (master data). Их постоянство и частота использования в бизнес-процессах заставляют обратить на них особое внимание, когда компания начинает задумываться о качестве данных.
Для разных отраслей основные данные могут отличаться и иметь разную степень влияния на бизнес. Например, для ритейла самым объемным и важным справочником является справочник «Товары (SKU)» – от ошибок в нем зависит логистика, излишки или недостатки складских запасов, риски потери товаров в связи с истечением сроков годности. А для телекома большее значение будет иметь справочник клиентов.
Ниже приведены примеры объектов основных данных в разных отраслях.
Для всех компаний:
- Номенклатура
- Контрагенты
- Договоры
- Банковские счета
- Сотрудники
Для производственных компаний:
- Технологические объекты
- Материально-технические ресурсы
- Объекты кап. строительства
- Нормативно-техническая документация
Для ритейл-компаний:
- Товары (SKU)
- Аккаунты клиентов
- Торговые точки
- Поставщики
Для компаний из сферы HoReCa:
- Аккаунты клиентов
- Блюда, напитки (рецептура, технолог. карты)
- Оборудование
- Единицы учета (столы, кассы)
Для компаний из сферы строительного девелопмента:
- Объекты строительства
- Подрядчики
- Клиенты
- Объекты инфраструктуры
- Проектная документация
В первую очередь, следует обратить внимание на качество объектов НСИ, которые:
- Оказывают наибольшее влияние на доход и связаны с основным бизнес-процессом компании (часто номенклатура, клиенты, контрагенты).
- Отнимают больше всего времени сотрудников на работу с ними (часто справочники для подготовки закупочной документации, особенно по 223 ФЗ и 44 ФЗ).
- Связаны с требованиями регуляторов и создают риск наложения штрафных санкций со стороны ФНС, Роспотребнадзора, Федеральной таможенной службы и т.д.
Как повысить качество основных данных?
Чтобы повысить качество данных используются следующие методы и инструменты:
1. Нормализация. Трансформация данных в соответствии с требованиями методики ведения объекта нормативно-справочной информации: структурирование данных, заполнение необходимых атрибутов, выявление и удаление дублей, ошибок, неактуальных данных.
2. Обогащение. Дополнение данных новыми атрибутами, которые обеспечат большую полноту и качество данных.
3. Маппинг. Сопоставление полей данных в разных источниках. Потребность в маппинге возникает при необходимости обмениваться данными между двумя и более системами.
4. ML-автоматизация. Применение технологии машинного обучения (machine learning) для автоматического выявления и исправления некачественных данных в объектах НСИ.
5. Назначение ответственных. Без назначения конкретных сотрудников, выполняющих разные роли оп отношению к объектам данных, данные становятся неуправляемыми, снижается их качество и расчет несогласованность.
6. Нормативно-методическая документация. Для каждого важного объекта данных должна быть разработана методика ведения (структура, правила, требования и ограничения к значениям) и регламент ведения (порядок ведения и роли участников процесса).
7. Интеграция внешних справочников. Поддержание данных в актуальном состоянии с помощью получения данных из внешних источников. Для автоматизации процесса можно настроить регулярный экспорт – импорт или подключится к внешнему источнику по API, чтобы всегда иметь доступ к актуальным данным.
Оптимальный путь управления НСИ
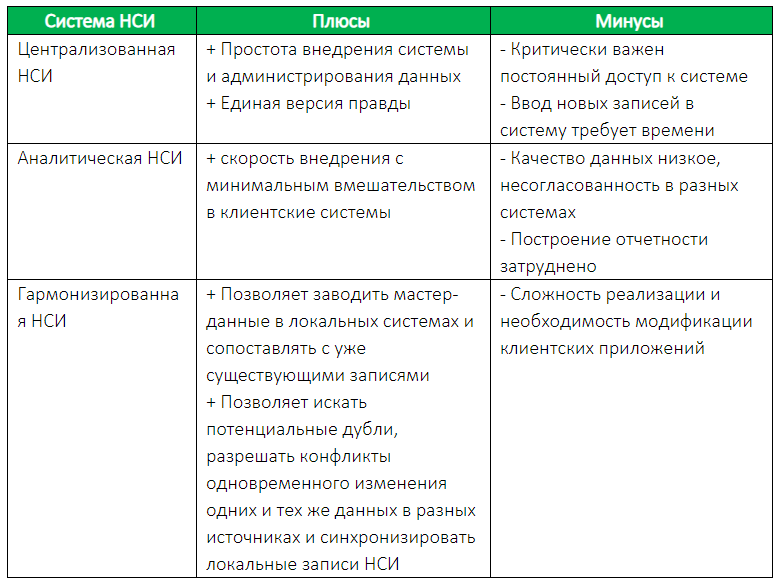
Существует несколько вариантов организации системы НСИ в зависимости от того, как НСИ взаимодействует с клиентскими информационными системами организации. Для каждой из форм организации НСИ характерны свои плюсы и минусы, которые нужно учитывать при выборе подхода к построению системы.
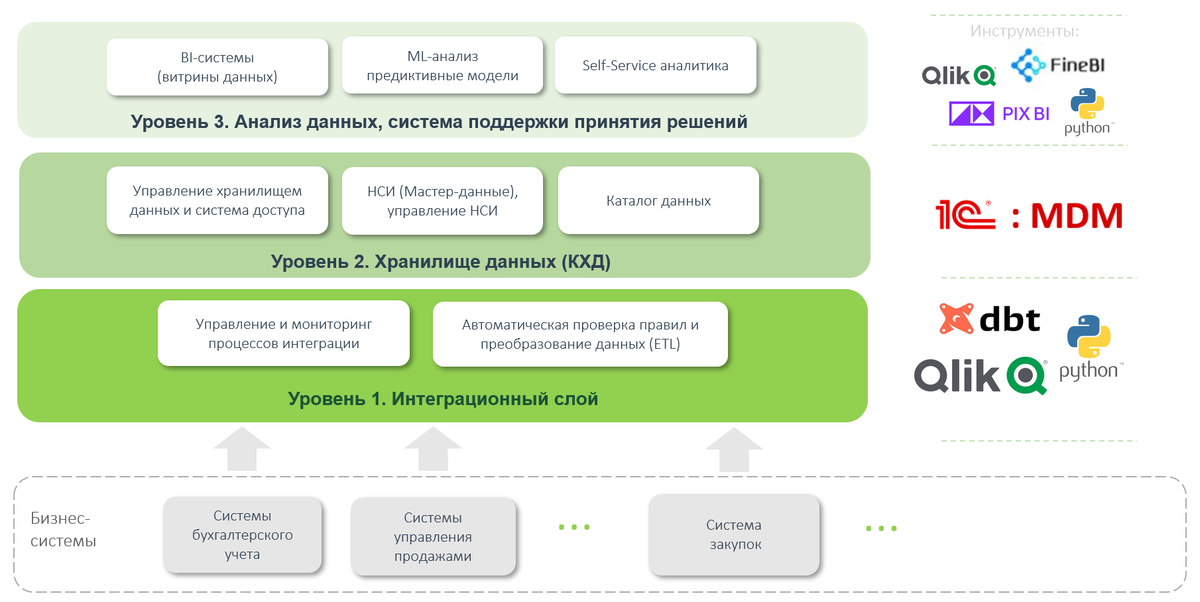
Исходя из нашего опыта построения систем НСИ, оптимальная архитектура, которая обеспечит одновременно гибкость, управляемость и надежность системы выглядит следующим образом.
На первом уровне находится интеграционный слой – информационная шина, к которой подключаются все бизнес-системы. Именно через этот слой происходит информационный обмен. Шина управляет трансформацией данных между разными информационными системами, автоматическими проверками и уровнями доступа разных пользователей к определенным данным.
Следующий слой – корпоративное хранилище данных (КХД, DWH), где хранятся необходимые для работы различных бизнес-систем данные. Система НСИ находится именно в этом слое, где она обеспечивает доступность этих данных, их актуальность, качество и правильную структуру.
На третьем слое находятся BI-инструменты, в том числе self-service, инструменты ML-анализа. Главная цель сбора данных – их дальнейший анализ для извлечения ценности: принятия верных управленческих решений, получения инсайтов для развития бизнеса. Чтобы результаты анализа были корректны, важно, чтобы данные «на вход» были чистыми. За это во многом отвечает система НСИ.
Разберем пример проекта по управлению НСИ для одного из самых часто используемых справочников - «Номенклатура»:
На схеме видим, что на старте всегда проводится обследование, с помощью которого определятся исходное состояние (AS IS):
- 3 системы-источника
- 7 систем-потребителей
- 50 тысяч исторических записей, которые не нормализованы, имеют дубликаты, ошибки и пустые поля
- 10 основных атрибутов справочника
- 200 бизнес-пользователей
Задача проекта: вычистить некачественные данные, структурировать информацию и выделить характеристики, чтобы иметь возможность делать параметрическое описание номенклатуры.
Параметры системы (TO BE) по итогам реализации проекта:
- Единая система-источник
- Единая методика ведения
- Структурированные характеристики
- Система классификации записей
- 40 тысяч нормализованных записей
- 1000 номенклатурных групп
Инвестиции в проект управления НСИ и сроки окупаемости
Для примера, рассмотренного выше, рассчитаем инвестиции и окупаемость.
Рассматриваем проект продолжительностью 1,5 года. Полгода – период аудита и описания текущих процессов, разработки структуры и хранения данных, создания методической документации нормализации справочников и запуск системы в промышленную эксплуатацию. Еще год – сервисное обслуживание справочника для обеспечения обучения пользователей, мониторинга качества и выполнения заявок.
Теперь рассмотрим за счет чего будет обеспечен возврат инвестиций и в какие сроки он возможен. Самое существенную экономию в нашем примере обеспечит снижение расходов на логистику и хранение излишков на складе, остальная экономия достигается за счет снижения трудозатрат. Таким образом, уже на второй год рентабельность инвестиций в проект составит 192%, а экономия – более 20,3 млн рублей в год.
Разумеется, конкретные цифры инвестиций и ROI зависят от количества объектов НСИ, качества исходных данных и бизнес-процессов компании. Нередкой является ситуация, когда компания начинает управление НСИ с нормализации одного небольшого справочника для оценки возможного экономического эффекта или разработки нормативно-методической документации для своих справочников.
Вне зависимости масштаба проекта по управлению НСИ, первым шагом будет аудит текущего состояния информационных систем. В ходе аудита выявляются основные проблемы в качестве, структуре, полноте и согласованности данных, определяется состав номенклатурных групп. На основе данных аудита можно не только построить детальный план работ и определить оптимальные инструменты, но и рассчитать экономический эффект, который принесет проект.
Qlever Solutions предлагает услугу бесплатного аудита, на основании которого мы предложим дорожную карту внедрения проекта. Наша команда зарекомендовала себя как надежный партнер в управлении НСИ. В нашем портфеле заказов – реализованные проекты по внедрению эталонного справочника в нефтяной отрасли, созданию методологии ведения справочников капитального строительства и разработке НСИ для номенклатуры, участвующей в производственных процессах переработки.
Кроме реализованных проектов по управлению НСИ, Qlever Solutions имеет 10-летний опыт внедрения корпоративной бизнес-аналитики и консалтинга в области эффективного использования данных. Мы поможем вам взглянуть на свои данные под новым углом и сделать их драйвером роста вашего бизнеса.