Всем привет, меня зовут Андрей, это снова я!
Сегодня я хочу рассказать про функцию Эксель СМЕЩ()
Интересная особенность этой функции заключается в том, что с ее помощью можно создать целый массив данных, в котором может быть:
- или несколько строк и несколько столбцов;
- или только один столбец;
- или только одна строка;
- или только одна ячейка.
Приведем примеры.
Пусть у нас имеется какая-то таблица, в которой достаточно много строк (или много столбцов; или много и столбцов, и строк). Пусть будет в нашей таблице 12 строк и 50 столбцов. Покажем фрагмент этой таблицы, в котором видны только несколько ее левых столбцов:
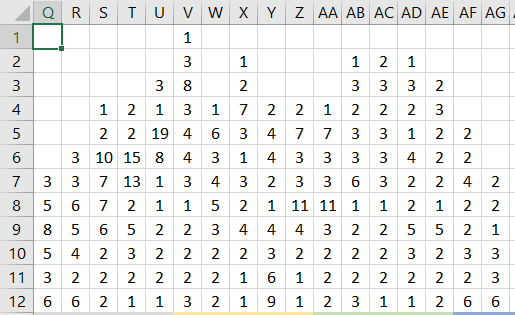
Итак, левая верхняя ячейка нашей таблицы – это ячейка Q1. Всего 12 строк, 50 столбцов.
Допустим, что нам надо выяснить сумму всех чисел этой таблицы (не тех цифр, что показаны на рисунке-фрагменте, а всей таблицы полностью). Нам не обязательно знать буквенное обозначение правого столбца данной таблицы. Достаточно использовать функцию СМЕЩ(), чтобы найти сумму всех чисел таблицы.
Итак, нам нужна сумма. Это значит, что в начале будем использовать функцию СУММ(), а сразу после нее – функцию СМЕЩ().
Нужная нам функция будет выглядеть так:
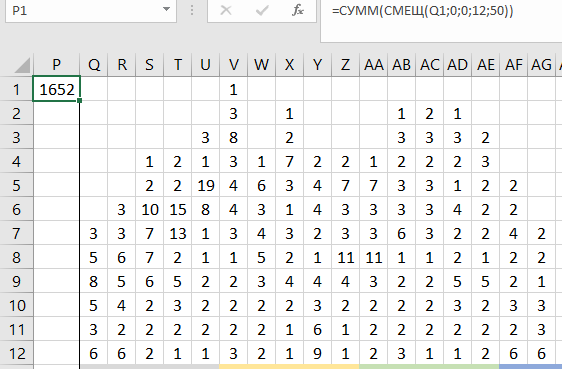
=СУММ(СМЕЩ(Q1;0;0;12;50))
Здесь Q1 – это та ячейка, относительно которой будем начинать считать, что-то типа «системы отсчета». Первый ноль – это смещение по строкам, второй ноль – это смещение по столбцам. В нашем конкретном случае обе эти цифры равны нулю потому, что та ячейка, которую мы выбрали за «систему отсчета», находится в левом верхнем углу нужной нам таблицы (нужного нам массива чисел), для которой нужно найти сумму; 12 – это высота массива, 50 – его ширина.
Две последние цифры не обязательные для функции СМЕЩ(), если их пропустить или приравнять к единице, то мы получим всего одну ячейку (в нашем конкретном случае это была бы ячейка Q1).
Если бы высота массива была равна единице, то это бы значило, что весь массив умещается в одну строку; если бы ширина массива была равна единице, тогда весь массив умещался бы в одном столбце.
Если мы эту формулу запишем в ячейку P1, то получим результат: 1652:
Аналогичным образом можно вычислять не только сумму, но и все то другое, что связано с массивом данных, например – минимум, максимум, количество значений и т.д. Например, для подсчета количества значений функцию СУММ() заменим на функцию СЧЁТ(). В любом случае, мы будем работать с массивом данных, в котором задано количество строк, количество столбцов и левый верхний угол нужного массива данных.
Не обязательно в самой формуле указывать именно левый верхний угол того массива, который нам нужен. Можно указать любую ячейку как внутри нужного нам массива, так и вне его. Например, если бы мы ввели в ячейку P1 формулу:
=СУММ(СМЕЩ(R2;-1;-1;12;50))
то получили бы такой же результат. Таким образом, отрицательное смещение означает смещение влево по столбцам и вверх по строкам, положительное – вправо или вниз.
Эту формулу можно еще немного изменить таким образом, чтобы не нужно было самому считать сумму смещения как по строкам, так и по столбцам:
=СУММ(СМЕЩ(R2;СТРОКА(Q1)-СТРОКА(R2);СТОЛБЕЦ(Q1)-СТОЛБЕЦ(R2);12;50))
Результат будет тем же:
Хотя, конечно же, удобнее всего выбирать "точку отсчета" так, чтобы она была в левом верхнем углу массива, тогда смещения и по вертикали, и по горизонтали, будут нулевыми.
Приведем еще один пример, из того же файла.
Пусть у нас еще одна таблица, где есть 13 столбцов и 70 строк. Левый верхний угол таблицы – это A16. Покажем несколько верхних строк этой таблицы:
Допустим, что в ячейке P2 нужно вычислить сумму всех чисел этой таблицы.
Введем в эту ячейку формулу:
=СУММ(СМЕЩ(A16;0;0;70;13))
Мы получим тот же ответ, что был и в предыдущем случае (1652). Но это и не удивительно, потому что мы суммировали исходные данные для решения одного и того же японского кроссворда. Если в первом случае мы сталкивались с суммой закрашенных клеток по вертикалям, то во втором случае – та же сумма, но по горизонталям. Очевидно, что эти суммы совпадут, потому что суммарное количество закрашенных ячеек во всём японском кроссворде будет одним и тем же, как бы мы ни считали – сумму по строкам, или сумму по столбцам.
Одно из удобств (самое очевидное, но не единственное) получения массивов данных с помощью функции СМЕЩ() заключается в том, что если у нас вдруг появятся какие-то изменения в нашей таблице, где надо найти сумму (или минимум, или что-то еще), например: изменится число строк, число столбцов и т.д., то мы просто быстро исправим нужные цифры в формуле, и даже не надо думать о том, каким именно будет буквенное обозначение крайнего правого столбца в нашей таблице с массивом данных.
Есть еще одно удобство в применении функции СМЕЩ().
Рассмотрим те же цифры, что и были в нашем примере.
Снова покажем этот рисунок:
Допустим, надо вычислить, на какой позиции в 12-й строке находится первая тройка (то есть: где впервые встречается цифра 3).
Введем в ячейку P12 формулу:
=ПОИСКПОЗ(3;СМЕЩ(Q12;0;0;1;50);0)
Будет результат: 6, это значит, что среди всех чисел 12-й строки (в заранее заданном интервале, в нашем случае интервал начинается со столбца Q и содержит 50 элементов) цифра 3 впервые встретится на 6-й позиции.
Если бы нужно было выяснить, на какой позиции в том же массиве та же тройка (цифра 3) встречается во второй раз, мы бы ввели в какую-то свободную ячейку следующую формулу допустим, что мы ввели эту формулу в ячейку P13):
=P12+ПОИСКПОЗ(3;СМЕЩ(Q12;0;6;1;50-6);0)
Здесь P12 - это та ячейка, в которой мы уже содержится номер позиции, в которой цифра 3 встречается первый раз в нужном массиве. А функция ПОИСКПОЗ() будет находить тройку не в первоначальном массиве, а в урезанной его версии, причем мы урезаем слева несколько чисел таким образом, чтобы последней урезанной нами ячейкой была именно та ячейка, которая содержит цифру 3 в нашем исходном массиве в первый раз. Внутри этой функции СМЕЩ() ячейка Q12 - это левая верхняя ячейка всего массива целиком, до "урезания"; после этого ноль означает смещение по строкам (потому что у нас левый верхний угол всего массива, до "урезания", находится в той же строке, что и ячейка Q12; хотя наш массив состоит всего из одной строки, но, сколько бы ни было строк и столбцов в массиве, первые цифры в формуле СМЕЩ() после "точки отсчета" касаются смещения по строкам и по столбцам именно левой верхней ячейки того массива, который мы имеем ввиду, относительно этой самой "точки отсчета"). Если "точка отсчета" совпадает с левой верхней ячейкой массива, тогда смещение и по строкам, и по столбцам будет равно нулю.
Далее идет смещение по столбцам, в нашем примере это цифра 6, потому что перед этим мы вычисляли, на какой позиции в нашем массиве цифра "3" встречается впервые, и был получен ответ: 6, то есть цифра "3" в нашем массиве впервые встречается на шестой позиции. Поскольку теперь нам надо вычислить, на какой позиции цифра "3" будет встречаться во второй раз, то мы просто сделаем смещение по столбцам на 6 единиц.
Тут и выясняется еще одно, очень существенное преимущество представления массивов именно с помощью функции СМЕЩ(). Ведь,если бы не было этой функции, то весь массив пришлось бы представлять таким образом, чтобы были задействованы буквенные имена столбцов. Для выявления первой цифры "3" в рассматриваемом массиве еще можно применить формулу, например:
=ПОИСКПОЗ(3;Q12:BN12;0)
Но уже при поиска второй "тройки" выясняются все очевидные неудобства в именно этом представлении нужной нам формулы. Ведь, если бы нужное нам число впервые встретилось на первой позиции, тогда для поиска следующей позиции нужно было брать массив от R12, если бы это число встретилось впервые во второй позиции, тогда для поиска следующей позиции нам нужен был бы массив, который начинался бы с ячейки S12, и так далее. Таким образом, нам даже очень трудно выявить единую формулу для поиска второй "тройки" (или другого числа, которое встречается в массиве второй раз). А вот представление массива с помощью функции СМЕЩ() решает не только эти, но и многие другие проблемы и трудности, которые могут возникнуть при работе с массивами, причем это в наибольшей степени касается массивов с неопределенной или "плавающей" размерностью.
А нашу формулу поиска второй цифры в массиве можно еще немного усовершенствовать. Если мы найдем еще одну пустую ячейку (например, P11) и будем ее использовать исключительно для того, чтобы помещать в нее то самое число, для которого нам нужно вычислить: когда оно встречается в нужном массиве первый раз, а когда - второй раз, тогда формула для выяснения "второй позиции" будет звучать так (допустим, что мы ввели эту формулу в ячейку P13):
=P12+ПОИСКПОЗ(P11;СМЕЩ(Q12;0;P12;1;50-P12);0)
И теперь, как только изменится число в ячейке P11, то сразу же изменятся числа в ячейках P12 и P13. В ячейке P12 мы увидим, на каком месте в массиве можно первый раз встретить то самое число, что находится в ячейке P11, а в ячейке P13 - когда в том же массиве можно увидеть то же число во второй раз. Приведем пример - пусть то число, которое нас интересует, - единица:
Мы видим, что единица в нужном нам массиве первый раз используется на четвертой позиции, второй раз - на пятой.