Используется библиотека requests для получения HTML-кода страницы.
С помощью библиотеки BeautifulSoup извлекаются необходимые данные из HTML-кода.
С помощью регулярных выражений и извлеченных данных формируется текстовый результат.
Полученный результат выводится в телеграм боте.
Парсер получает новости о спорте с сайта.
Парсер извлекает информацию о виде спорта, времени, счете и командах, участвующих в матче.
Результат выводится в телеграм боте. в виде текстовой информации.
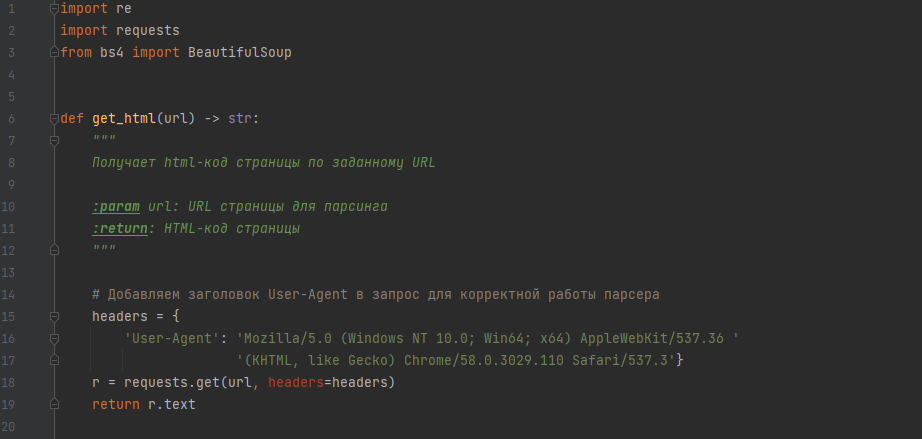
Первым делом импортируем библиотеки, далее получаем html-код страницы по заданному URL
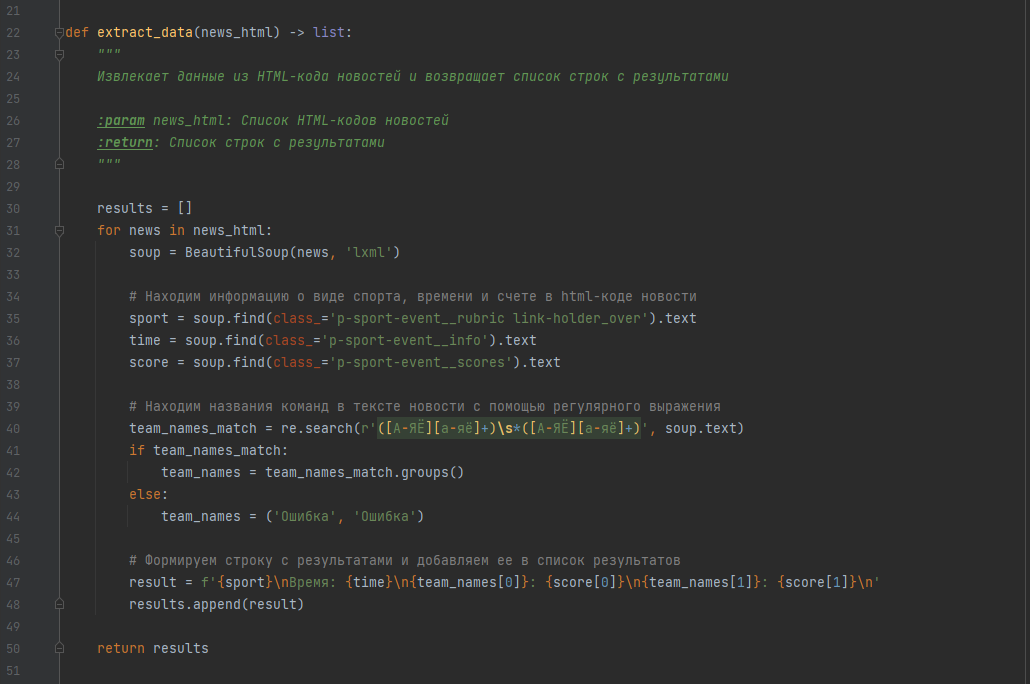
Создаем функцию 'extract_data', которая будет извлекать данные из HTML-кода новостей и возвращает список строк с результатами
Выглядит это примерно так:
Следующая функция 'main' - основная функция программы, которая вызывает остальные функции и возвращает результат
Для того чтобы отправить результат в ТГ бот, мы напишем два хендлера
Пишем loader который запустит наш бот.
Структура бота выглядит так:
Конечный результат выглядит так:
Парсинг информации о спорте с использованием Python позволяет быстро и удобно получать информацию о происходящих событиях. Программа может быть использована как для личного пользования, так и для аналитических целей. Бот создан исключительно в образовательных целях.