Об этом простом, но при этом крайне эффективном способе факторизации чисел написано достаточно много статей. Однако я мало где видел, чтобы обозревались конкретные модификации данного алгоритма. В частности, представляется интересным сравнение его с многопоточной версией и с модификацией Ричарда Брента. Эти улучшения, на мой взгляд, не менее важны для теории чисел и защиты информации в целом, чем сам алгоритм Полларда.
Условия задачи
Прежде, чем перейти к самому алгоритму необходимо формализовать задачу, которую он решает. Ее формулировка немного отличается от традиционной в меру специфики развития алгоритмов теории чисел.
Для произвольного составного натурального n необходимо найти такие натуральные p и q не равные 1, что n = p*q.
А теперь попробую заранее ответить на вопросы, которые могли возникнуть по формулировке задачи.
Почему мы рассматриваем только множество составных чисел для факторизации?
Во-первых, потому что в теории чисел задача определения простоты решается, как правило, с помощью вероятностных методов, гораздо быстрее, чем любая факторизация. Например, BPSW - один из мощнейших алгоритмов определяющих простоту числа работает за O(log(n)^4) при этом лучшее время, за которое сегодня работает алгоритм факторизации, не превосходит в скорости O(n^(1/4)). Именно это факт и позволяет нам работать только с составными числами, не увеличивая значительно время работы.
Во-вторых, алгоритм Полларда в случае с простыми числами работает очень долго, за O(n^(1/2)). Таким образом, самым правильным решением в данном случае является в начале определить его простоту за более быстрое время, а потом, если оно составное, разложить на два множителя.
Почему мы раскладываем число только на 2 множителя?
Дело в том, что если мы умеем решать задачу для n, то для меньших чисел она тривиальна и несильно влияет на время работы алгоритма в целом. Для большего понимания этого факта рассмотрим 2 диаметрально противоположных случая:
- Пусть n состоит из большого числа простых множителей.
- Пусть n состоит из двух простых множителей, то есть является полупростым.
В первом случае, так как число имеет много простых множителей, то в меру их количества они гораздо меньше, чем возможные множители во втором случае, следовательно, факторизовать его не составит труда, так как делители небольшие. Другими словами, увеличение количества запусков алгоритма из-за количества множителей ни в коем случае не увеличит сильно количество операций, потому что число имеет маленькие делители, что сильно упрощает работу алгоритму.
Во втором случае предполагается лишь один запуск алгоритма, но при этом работа его может быть дольше обычного, так как нетривиальные делители могут быть примерно равны n^(1/2), что труднее, чем если бы делителями были 2,3,5. Даже с точки зрения теории вероятности на них сложнее наткнутся, случайно ткнув на отрезок натуральных чисел, чем на делители в первом случае.
Описание алгоритма
У данного подхода к решению задачи факторизации есть огромное множество похожих друг на друга алгоритмов. Однако в дальнейшем для сравнения его с модификацией Ричарда Брента имеет смысл использовать самый простой и элегантный вариант.
Пусть имеется N - составное натуральное число, которое необходимо разложить на множители, тогда запускаем следующую последовательность действий:
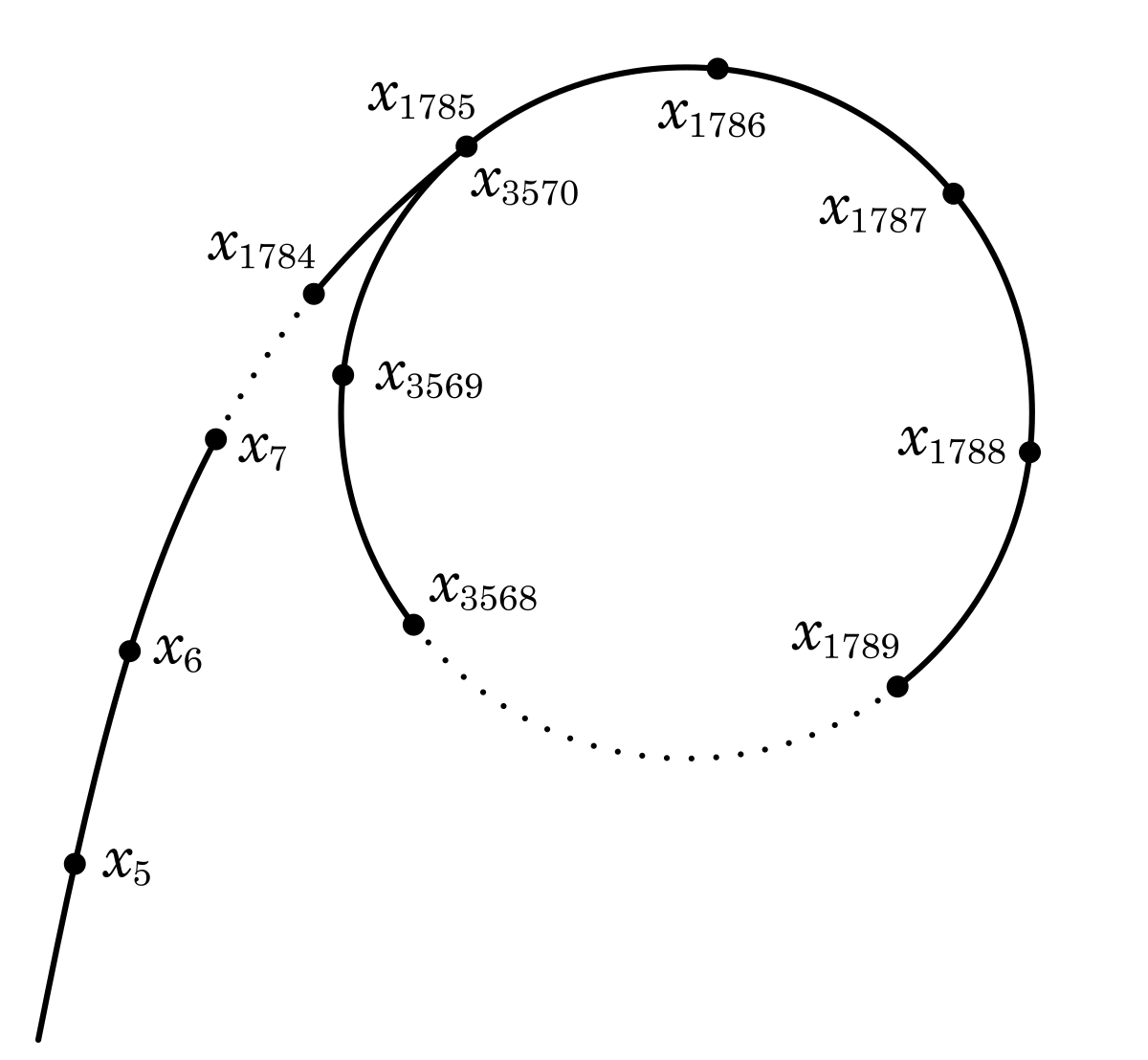
- Случайным образом выбирается небольшое число x_0 и строится последовательность {x_n}, где x_1 = F(x_0), ..., x_(n+1) = F(x_n).
- При этом во время построения последовательности всякий раз, когда встречаются такие x_i и x_j, что i<j и i = 2j, вычисляем НОД(N,|x_i-x_j|).
- Если этот НОД отличен от 1, то мы нашли разложение числа N = p*q, где p = НОД(N,|x_i-x_j|), а q = N/p. В ином случае, продолжаем двигаться по последовательности.
Примечание: за F(x) обычно берется какой-то нелинейный полином по модулю факторизуемого числа, например, F(x) = x^2+1 (mod n). F(x) должна образовывать достаточно "случайную последовательность" при применении композиции. Однако, например, F(x) = x^2+2 не подойдет.
Таким образом, ро-алгоритм Полларда - это по сути интерпретация алгоритма поиска цикла ("Черепахи и зайца") только уже в теории чисел. О нем вы можете прочитать в моей другой статье.
Собственно в названии поэтому и встречается буква "ро", так как рано или поздно он обязан зациклиться, визуально образовав петлю, в меру ограниченности функции F(x) и множества, на котором она определена. И, следовательно, исходя из совпадения остатков по модулю n можно пытаться полагать, что НОД модуля разности их с факторизуемым числом может дать делитель самого n.
Теперь, когда уже понятно почему алгоритм работает, остается открытым вопрос "За какое время он работает?". Тут уже на помощь приходит известный всем парадокс дней рождений.
Доказательство времени работы
Прежде, чем перейти к основной части необходимо получить поверхностное понимание парадокса дней рождений.
Если описывать его очень кратко и сухо, то парадокс дней рождений - это контринтуитивное утверждение о том, что в группе, состоящей из 23 или более человек, вероятность совпадения дней рождения (число и месяц) хотя бы у двух людей превышает 50 %.
Однако можно дать более общую и строгую формулировку данному "парадоксу":
Вероятность p(n) того, что в группе из n человек как минимум у двух из них дни рождения совпадут при равномерном распределении вероятности на всех 365 днях, другими словами, вероятность того, что человек родился в первый день года или в любой другой - абсолютно одинаковая, вычисляется как p(n) = 1-g(n), где g(n) равен:
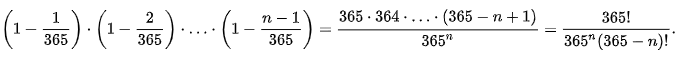
Теперь перейдем к самому доказательству. Если не вдаваться в подробности доказательства, то представьте, что вместо дат рождения у вас остатки от деления на N не превышающие N^(1/2), а вместо людей - бездушный набор чисел, который образуется в ходе последовательного применения функции F(x). И если подставить в формулу эти параметры и по аналогии вычислить сколько необходимо выполнить итераций цикла ( или как увеличить количество чисел в случайной последовательности, порожденной применение F(x) ), чтобы с вероятностью 50% остатки совпали, то получится, что при факторизуемом числе N как раз будет выполнено O(N^(1/4)) итераций.
Битва за доли секунд...
Теперь, когда мы знаем как работает магия рандома, возникает вопрос: "А можно быстрее?" - Да, можно. К сожалению, этот способ факторизации не является абсолютным чемпионом по скорости, есть и быстрее, хотя он в модификации Ричарда Брента считается лучшим на числах в диапазоне от 2^16 до 2^70. Однако в данной обзорной статье мы не будем касаться других алгоритмов, а скорее просто уделим внимание разнообразным улучшениям уже имеющегося решения и сравним их в работе.
Модификация Ричарда Брента
Данное улучшение алгоритма основано на том, что вместо алгоритма Флойда для поиска цикла используется алгоритм Брента, который в среднем работает на 25% быстрее. Если коротко, то главное отличие заключается в том, что вместо постоянного применения свойства: "Если x_i находится внутри цикла, то выполняется равенство x_i = x_2i", используется немного другая хитрость: "Должно существовать такое k, что в последовательности от x_(2^k + 1) до x_(2^(k+1)) лежит цикл". Реализуется эта идея следующим образом:
- Берем k := 1, x_j=x_i=x_0 и по такому же принципу строим последовательность {x_n}
- Берем j=2^k, x_j := f(x_0), x_i := f(f(x_0)). При первом проходе на данном шаге получится j=2, i=3.
- Пробегаемся i от 2^k + 1 до 2^(k+1), включительно, обновляя соответствующим образом значение x_i.
- Если в определенный момент получается так, что x_i=x_j, то становится сразу известна длина цикла i-j. В противном случае изменяем k := k+1 и j := 2^k, при этом x_j := x_i и x_i := f(x_i). Таким образом, возвращаемся к 3-му шагу, пока не будет найдено совпадение x_i=x_j.
То есть в алгоритме Брента цикл ищется сразу и для этого не требуется двигать сразу 2 указателя или начинать все сначала после первого же совпадения значений двух указателей. В приложении к Ро-алгоритму Полларда это выглядит следующим образом.
- Генерируем случайный x в пределах от 1 до n-2.
- Берем y = 1, i = 0, stage = 2.
- Вычисляем НОД( |x-y|, n), если он не равен 1, то мы нашли делитель, то есть p = НОД( |x-y|, n), а q = n/p - разложение найдено. В противном случае переходим к следующему шагу.
- Если i равен stage, то присваиваем y := x и stage := 2*stage. Иначе идем к следующему пункту.
- Делаем шаг x := F(x) и обновляем счетчик i := i+1. Возвращаемся ко 3-му пункту.
Впоследствии именно эту вариацию и будем использовать для распараллеливания работы алгоритма.
Распараллеливание
К сожалению, конкретных примеров в официальных научных журналах мною не было найдено, поэтому исходя из собранного материала я решил провести собственный эксперимент и предложить свои способы распараллеливания:
- Наивный запуск одного и того же алгоритма на разных потоках и с разными стартовыми значениями x_0.
- Запуск на разных потоках алгоритмов, которые будут отличаться линейной и константной частью F(x) и стартовым значением.
- Запуск на разных потоках алгоритмов, которые будут отличаться стартовыми значениями и старшей степенью в F(x).
Третий вариант гипотетически имеет больший смысл, чем остальные, так как существует следующее эвристическое соображение:
Если известно, что для делителя P числа N и некоторого K>2 справедливо, что P-1 делится на K, то имеет смысл использовать F(x) = x^K+b (mod N) для более быстрой сходимости цикла.
Однако результат меня немного удивил. Оказывается, что в среднем на малых значениях лучше всего по скорости работает первый способ, а хуже - последний.
В среднем на такой выборке первый, второй и третий способы работали за 0.02537, 0.02538 и 0.02556 секунд соответственно, но при увеличении верхней границы в выборки наблюдалась диаметрально обратная ситуация:
На выборке с верхней границей 10^150 лидером по факторизации является третий способ с временем 0.02768 секунд, второе место занимает либо первый способ, либо второй - в данном случае их среднее время работы составляет 0.02803 и 0.02808 секунд соответственно.
Примечание: с увеличением количества потоков время работы различных алгоритмов почти не отличалось друг от друга. Скорее всего, потому что в меру их значительного ускорения тяжело было заметить какую-нибудь ощутимую разницу на такого размера данных.
Заключение
Таким образом, был разобран алгоритм и модификации к нему, в том числе и многопоточные реализации. Конечно, как сообщалось выше, есть алгоритмы, которые на более больших числах могут работать быстрее, чем метод Полларда. Однако использование многопоточности и различных сочетаний уже известных методов может позволить данному подходу быть чемпионом по скорости на достаточно широком множестве чисел. Сегодня данный алгоритм в модификации Ричарда Брента является лучшим на множестве чисел в диапазоне от 2^16 до 2^70.
На мой взгляд, грамотное использование и сочетание первого и третьего способа реализации многопоточности может значительно улучшить среднее время работы и расширить диапазон чисел, на которых он превосходит остальные решения. Однако это уже будет тема следующей статьи.
Примечание: интересно, что выдвигались предположения о достижимости ускорения O(p/log(p)^2), однако на сегодняшний день максимально возможное доказанное ускорение составляет O(p^(1/2)).