
Оптимизатор — это метод повышения производительности Модели (Model) Глубокого обучения (Deep Learning). Эти алгоритмы сильно влияют на Долю правильных ответов (Accuracy) и скорость обучения.
При обучении модели глубокого обучения нам необходимо изменить Веса (Weights) – коэффициенты, которые присваиваются каждому Признаку-столбцу (Feature) и передают важность этого соответствующего признака при прогнозировании. Более того, веса позволяют минимизировать Функцию потерь (Loss Function). Чем меньше ее значение, тем ближе предсказание модели к реальным значениям.
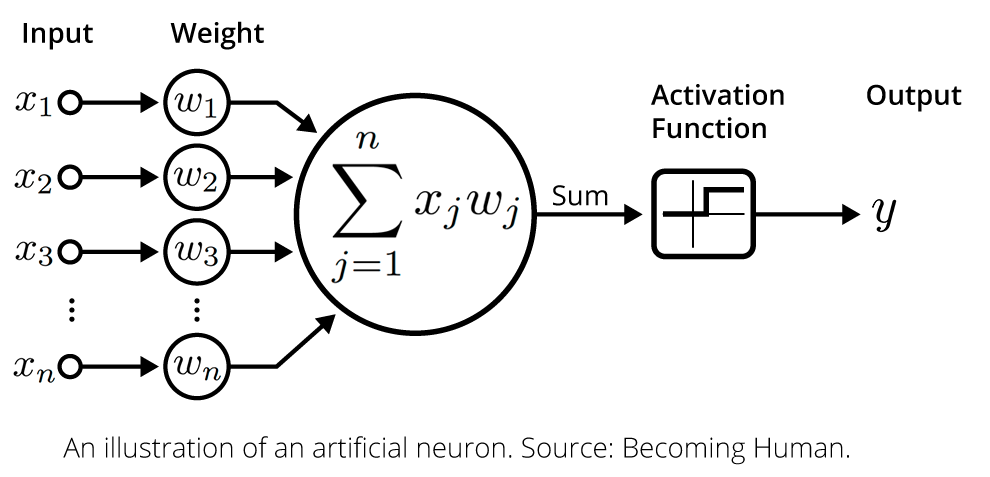
Оптимизатор — это алгоритм, который изменяет атрибуты Нейронной сети (Neural Network). Проблема выбора правильных весов для модели является сложной задачей, поскольку модель глубокого обучения обычно состоит из миллионов признаков. Возникает необходимость выбора подходящего алгоритма оптимизации.
Вы можете использовать различные оптимизаторы в модели машинного обучения, чтобы вносить изменения в свои веса и скорость обучения. Однако выбор лучшего из них зависит от назначения модели. Мы пробуем все виды и выбираем ту, которая показывает лучшие результаты. Сначала это может не быть проблемой, но при работе с сотнями гигабайт данных даже одна эпоха может занять значительное время. Так что случайный выбор алгоритма — это не что иное, как азартная игра с вашим драгоценным временем, что вы рано или поздно осознаете.
В этом руководстве рассматриваются различные оптимизаторы глубокого обучения:
- Градиентный спуск (GD)
- Cтохастический градиентный спуск (SGD)
- Cтохастический градиентный спуск с импульсом
- Мини-пакетный градиентный спуск (MBGD)
- Adagrad
- Среднеквадратичное распространение (RMSProp)
- AdaDelta
- Adam
К концу статьи мы сможем сравнить различные оптимизаторы и процедуры, на которых они основаны. Прежде чем продолжить, вот несколько терминов, с которыми мы познакомимся:
- Эпоха (Epoch) — количество запусков алгоритма на всем наборе обучающих данных.
- Сэмпл — одна строка набора данных.
- Пакет (Batch) — обозначает количество сэмплов, которые необходимо взять для обновления параметров модели.
- Скорость обучения (Learning Rate) — это параметр, который предоставляет модели шкалу того, сколько весов модели следует обновлять.
- Функция потерь (Loss Function): используется для расчета разницы между прогнозируемым и фактическим значениями и, как следствие, характеризует эффективность модели.
- Веса / Смещение (Bias) — параметры, которые управляют сигналом между двумя нейронами.
Теперь давайте рассмотрим каждый оптимизатор.
Градиентный спуск (Gradient Descent)
GD считается популярным детищем среди оптимизаторов. Он последовательно изменяет значения для достижения локального минимума. Прежде чем двигаться дальше, у вас может возникнуть вопрос о том, что такое градиент.
Проще говоря, представьте, что вы держите мяч, лежащий наверху чаши. Когда вы отпускаете мяч, он летит вниз под действием силы тяжести и в конце концов оседает на дне чаши. Градиент оптимизирует маршрут мяча таким образом, чтобы достичь локального минимума – дна чаши, как можно быстрее.
Градиентный спуск работает следующим образом:
- Он начинает с некоторых коэффициентов и ищет способ сократить ошибки.
- Он движется к меньшему весу и обновляет значение коэффициентов.
- Процесс повторяется до тех пор, пока не будет достигнут локальный минимум.
Градиентный спуск лучше всего подходит для большинства целей. Однако у него есть и некоторые недостатки. Вычислять градиенты дорого, если размер данных огромен.
Стохастический градиентный спуск (Stochastic Gradient Descent)
В конце предыдущего раздела вы узнали, почему использование градиентного спуска для массивных данных может быть не лучшим вариантом. Чтобы решить эту проблему, у нас есть стохастический градиентный спуск (SGD). Термин "стохастический" означает случайность, на которой основан алгоритм. В SGD вместо всего набора данных для каждой итерации, мы случайным образом выбираем пакеты – несколько образцов из набора.
Поскольку мы не используем весь Датасет (Dataset), а его части для каждой итерации, путь, пройденный алгоритмом, полон Шума (Noise), т.е. не укладывающихся в закономерность наблюдений. Таким образом, SGD использует большее количество итераций для достижения локальных минимумов. За счет увеличения числа итераций увеличивается общее время вычислений. Но даже после увеличения количества итераций стоимость вычислений все равно меньше, чем у градиентного спуска. Таким образом, вывод состоит в том, что если данные огромны, а время вычислений является важным фактором, стохастический градиентный спуск следует предпочесть алгоритму пакетного градиентного спуска.
Стохастический градиентный спуск с импульсом
Мы узнали, что стохастический градиентный спуск получает более зашумленные предсказания, чем градиентный спуск. По этой причине для достижения оптимального минимума требуется более значительное количество итераций, и, следовательно, большее время вычислений. Чтобы решить эту проблему, мы используем стохастический градиентный спуск с импульсом.
Импульс помогает быстрее достигнуть Сходимости (Convergence) – точке, при которой разность между предсказанным и реальным значениями, сводится к минимуму. Стохастический градиентный спуск колеблется между любым направлением градиента и соответствующим образом обновляет веса. Скорость обучения должна уменьшаться с высоким импульсом.
На изображении выше в левой части показан график сходимости алгоритма стохастического градиентного спуска. В то же время справа показан SGD с импульсом. На изображении вы можете сравнить путь, выбранный обоими алгоритмами, и понять, что использование импульса помогает достичь сходимости за меньшее время. Возможно, вы думаете об использовании большого импульса и скорости обучения, чтобы сделать процесс еще быстрее. Но помните, что при увеличении импульса увеличивается и возможность прохождения оптимального минимума. Это может привести к плохой точности и еще большим колебаниям.
Мини-пакетный градиентный спуск (Mini-Batch Gradient Descent)
В этом варианте градиентного спуска вместо того, чтобы брать все обучающие данные, для вычисления функции потерь используется только выборка. Поскольку мы используем пакет данных, а не весь набор данных, требуется меньше итераций. Вот почему алгоритм мини-пакетного градиентного спуска быстрее, чем алгоритмы стохастического градиентного спуска и алгоритмы пакетного градиентного спуска. Этот алгоритм более эффективен и надежен, чем более ранние варианты градиентного спуска. Поскольку в алгоритме используется пакетная обработка, все обучающие данные не нужно загружать в память, что делает процесс более эффективным для реализации. Кроме того, функция стоимости в мини-пакетном градиентном спуске более зашумлена, чем алгоритм пакетного градиентного спуска, но более гладкая, чем у алгоритма стохастического градиентного спуска. Из-за этого мини-пакетный градиентный спуск идеален и обеспечивает хороший баланс между скоростью и точностью.
Несмотря на все это, у алгоритма мини-пакетного градиентного спуска есть и недостатки. Ему нужен гиперпараметр «мини-пакетного размера», который необходимо настроить для достижения требуемой точности. Хотя размер партии 32 считается подходящим почти для каждого случая. Кроме того, в некоторых случаях это приводит к плохой конечной доле верных предсказаний. В связи с этим необходим подъем, чтобы искать и другие альтернативы.
Адаптивный градиентный спуск (AdaGrad)
Алгоритм адаптивного градиентного спуска немного отличается от своих собратьев. Это связано с тем, что он использует разные скорости обучения для каждой итерации. Изменение скорости обучения зависит от разницы параметров во время обучения. Чем больше изменяются параметры, тем менее заметны изменения скорости обучения. Несправедливо иметь одинаковое значение скорости обучения для всех функций.
Преимущество использования AdaGrad заключается в том, что он устраняет необходимость вручную изменять скорость обучения. Он более надежен, чем алгоритмы градиентного спуска и их варианты, и достигает сходимости на более высокой скорости.
Одним из недостатков AdaGrad является то, что он агрессивно и монотонно снижает скорость обучения. Нередко настает момент, когда скорость обучения становится чрезвычайно низкой. Модель в конечном итоге становится неспособной получить больше знаний, и, следовательно, точность модели ставится под угрозу.
Среднеквадратичное распространение (RMSProp)
Проблема с градиентами в том, что некоторые из них маленькие, а другие – огромны. Таким образом, определение единой скорости обучения может быть не лучшей идеей. RMSProp адаптирует размер шага индивидуально для каждого веса. В этом алгоритме два градиента сначала сравниваются по знакам. Если они имеют одинаковый знак, мы идем в правильном направлении и, следовательно, увеличиваем размер шага на небольшую долю. Если же они имеют противоположные знаки, мы должны уменьшить размер шага. Затем мы ограничиваем размер шага, и теперь мы можем перейти к обновлению веса.
Проще говоря, если существует параметр, из-за которого функция стоимости сильно колеблется, мы хотим наказать обновление этого параметра. Предположим, вы построили модель для классификации рыб. Модель опирается на фактор «цвет» в основном для различения рыб. Из-за этого он делает много ошибок. RMSProp наказывает параметр «цвет», чтобы модель полагалась и на другие признаки. Это предотвращает слишком быструю адаптацию алгоритма к изменениям параметра «цвет» по сравнению с другими параметрами. Алгоритм быстро сходится и требует меньшей настройки, чем алгоритмы градиентного спуска и их варианты.
Проблема с RMSProp заключается в том, что скорость обучения нужно задавать вручную, а предлагаемое значение подходит не для каждого приложения.
AdaDelta
AdaDelta можно рассматривать как более надежную версию оптимизатора AdaGrad. Он предназначен для устранения существенных недостатков AdaGrad и RMSProp. Основная проблема с двумя вышеперечисленными оптимизаторами заключается в том, что начальную скорость обучения необходимо задавать вручную. Еще одна проблема — падающая скорость обучения, которая в какой-то момент становится бесконечно малой. Из-за этого через определенное количество итераций модель уже не может усваивать новые знания.
Adam
Adam в данном контексте означает "adaptive moment estimation" (англ. адаптивная оценка момента). Этот алгоритм оптимизации является дальнейшим расширением стохастического градиентного спуска для обновления весов сети во время обучения. В отличие от поддержания единой скорости обучения посредством обучения в SGD, оптимизатор Adam обновляет скорость обучения для каждого веса сети индивидуально. Adam наследует функции Adagrad и RMSProp.
Этот оптимизатор имеет ряд преимуществ, благодаря которым он получил широкое распространение. Он считается эталоном в глубоком обучении и рекомендуется в качестве алгоритма оптимизации по умолчанию. Кроме того, алгоритм прост в реализации, отрабатывает быстрее, имеет низкие требования к памяти и требует меньше настроек, чем любой другой алгоритм оптимизации.
Если оптимизатор Adam использует хорошие свойства всех алгоритмов и является лучшим доступным оптимизатором, то почему бы вам не использовать Adam в каждом приложении? И зачем было углубляться в изучение других алгоритмов? Это потому, что даже у Адама есть недостатки. Он имеет тенденцию сосредотачиваться на более быстром времени вычислений, тогда как алгоритмы, такие как стохастический градиентный спуск, сосредотачиваются на точках данных. Вот почему такие алгоритмы, как SGD, лучше обобщают данные за счет низкой скорости вычислений.
Таким образом, алгоритмы оптимизации могут быть выбраны соответственно в зависимости от требований и типа данных.
Оптимизаторы на практике
Мы изучили достаточно теории, и теперь нам нужна практика. Пришло время попробовать то, что мы узнали, и сравнить результаты, выбрав разные оптимизаторы на простой нейронной сети. Мы будем обучать простую модель, используя несколько базовых слоев, сохраняя размер партии и эпохи одинаковыми, но применять разные оптимизаторы. Ради справедливости мы будем использовать значения по умолчанию для каждого оптимизатора.
Для начала импортируем необходимые библиотеки:
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
Загрузим набор данных:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
Подготовим Тренировочные (Train Data) и Тестовые данные (Test Data):
x_train = x_train.reshape(x_train.shape[0],28,28,1)
x_test = x_test.reshape(x_test.shape[0],28,28,1)
input_shape = (28,28,1)
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /=255
Создадим функцию build_model(), которая будет строить одни и те же модели, но с разными оптимизаторами:
batch_size = 64
num_classes = 10
epochs = 10
def build_model(optimizer):
model=Sequential()
model.add(Conv2D(32,kernel_size (3,3),activation='relu',input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy, optimizer= optimizer, metrics=['accuracy'])
return model
Обучим модель:
optimizers = ['Adadelta', 'Adagrad', 'Adam', 'RMSprop', 'SGD']
for i in optimizers:
model = build_model(i)
hist=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test,y_test))
Мы запустили нашу модель с 64 пакетами и в 10 эпох. Попробовав разные оптимизаторы, мы получили довольно интересные результаты.
В приведенной выше таблице показаны точность проверки и потери в разные эпохи. Он также содержит общее время, затраченное моделью на 10 эпох для каждого оптимизатора.
- Оптимизатор Adam показывает наилучшую точность за приемлемое время.
- RMSProp показывает такую же точность, но со сравнительно большим временем вычислений.
- Удивительно, но алгоритм SGD занял меньше времени для обучения и также дал хорошие результаты. Но для достижения точности оптимизатора Adam SGD потребуется больше итераций, а значит, время вычислений увеличится.
- SGD с импульсом показывает аналогичную SGD точность с неожиданно большим временем вычисления. Это означает, что значение полученного импульса необходимо оптимизировать.
- AdaDelta показывает плохие результаты как по точности, так и по времени вычислений.
Вы можете проанализировать точность каждого оптимизатора для каждой эпохи на графике ниже:
Вот мы и подошли к концу этого всеобъемлющего руководства. Чтобы освежить вашу память, кратко рассмотрим каждый алгоритм оптимизации еще раз.
SGD — это очень простой алгоритм, который практически не используется в приложениях из-за низкой скорости вычислений. Еще одна проблема с этим алгоритмом — постоянная скорость обучения для каждой эпохи.
Adagrad работает лучше, чем стохастический градиентный спуск, как правило, из-за частых обновлений скорости обучения. Лучше всего использовать его для работы с разреженными данными, то есть содержащими пропуски.
RMSProp показывает результаты, аналогичные алгоритму градиентного спуска с импульсом, он просто отличается способом вычисления градиентов.
Наконец, оптимизатор Adam унаследовал хорошие черты RMSProp и других алгоритмов. Результаты этого оптимизатора, как правило, лучше, чем у любого другого алгоритма оптимизации, занимают меньшее время и требуют меньше параметров для настройки. Из-за всего этого Адам рекомендуется в качестве оптимизатора по умолчанию для большинства приложений.
Но к концу мы узнали, что даже у оптимизатора Adam есть недостатки. Кроме того, бывают случаи, когда такие алгоритмы, как SGD, могут быть полезны и работать лучше, чем оптимизатор Adam. Таким образом, крайне важно знать свои требования и тип данных, с которыми вы имеете дело, чтобы выбрать лучший алгоритм оптимизации и добиться выдающихся результатов.
Автор оригинальной статьи: Ayush Gupta
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.