Подождите! Не торопитесь пролистывать! Этот пост не про "пример, взорвавший Интернет", и не про то "куда катится образование", и даже не про "народ, хорош спорить на пустом месте! ". Я даже вычислять его не буду.
Не бывает плохих и совсем никудышных задач, любая может стать поводом узнать что-то новое, полезное или интересное. Я хочу, оттолкнувшись от этого, конечно же, дурацкого примера, рассказать немного о том, как мы мыслим деревьями и превращаем деревья в строки и наоборот строки — в деревья.
* * *
Привычный для нас способ записи арифметических выражений родился не сразу, а был слеплен где-то к XVI веку из разных традиций, методик и приёмов. Потом он был формализован и приведён к современному виду, не допускающему двусмысленности. При правильном использовании, конечно.
Если записать вынесенное в заголовок выражение в форме дробей, то выглядеть оно будет так:
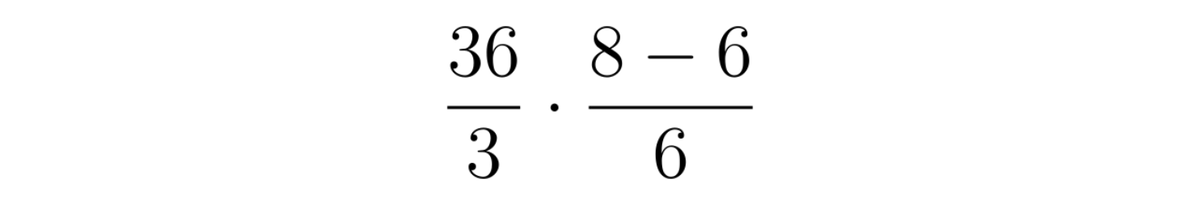
Уже лучше, но точнее всего смысл этого выражения отражает такое дерево:
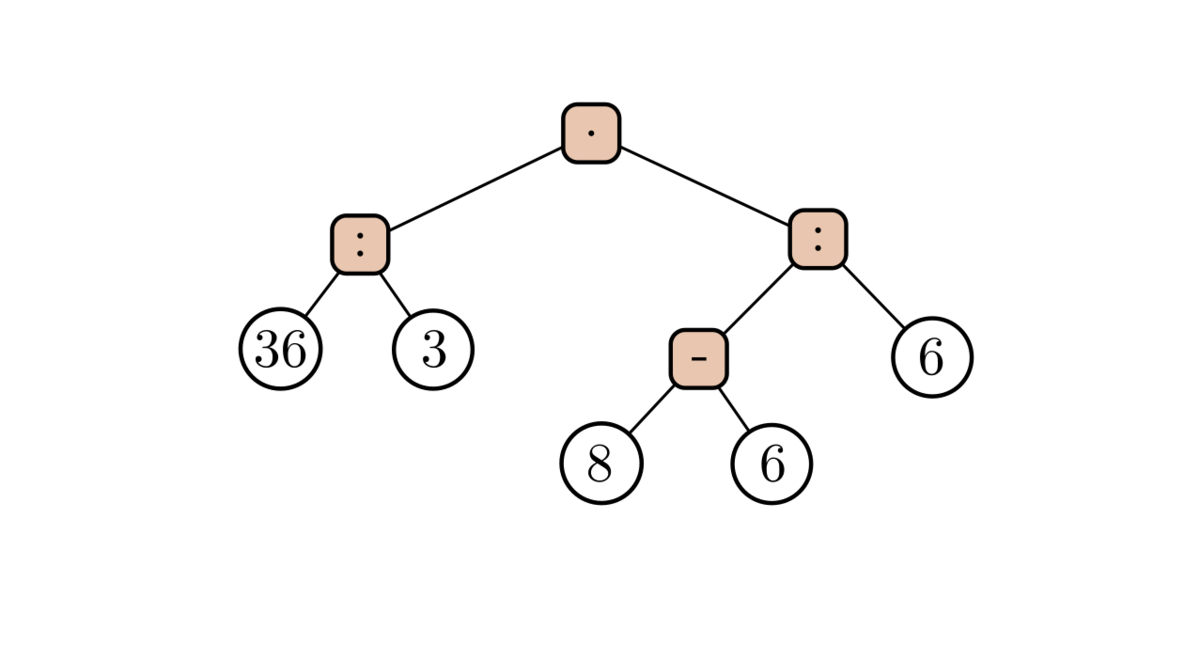
Оно говорит нам, что перед нами произведение двух отношений, в одном из которых делимое это разность. На уроках арифметики мы учимся выделять разные части этого дерева и давать им верные названия:
Этот процесс называется синтаксическим разбором выражения. Даже если мы этого не осознаём, во время чтении арифметического выражения, в голове у нас строится именно такое дерево, которое потом мы каким-то образом обрабатываем.
Если бы мы записывали всю арифметику и алгебру в виде деревьев, то никаких правил приоритета, левой и правой ассоциативности и скобок не потребовалось бы, ведь каждое дерево читается и вычисляется совершенно однозначно.
Однако, если придёт нужда объяснить это древовидное выражение очень прямолинейному автомату, например, компьютеру или калькулятору, то нам придётся выполнить обратную задачу и превратить мысленное синтаксическое дерево в строку, или, как говорят в программисты, сериализовать его, превращая сложную иерархическую структуру в линейную цепочку символов.
Способов сериализации может быть много и так вышло, что привычный нам способ, с приориетами операций и со скобками, один из самых неудобных и неестественных. С математической точки зрения, конечно. Гораздо разумнее просто обходить наше дерево узел за узлом и лист за листом, перечисляя встречаемые на нашем пути элементы.
Например, если мы будем обходить его в глубину снизу вверх и слева направо, то получим такую строку:
Прочесть эту запись можно, как последовательность инструкций:
Такую постфиксную запись, известную, как обратная польская нотация, очень легко обрабатывать на простейшем вычислителе. Именно так устроены стековые языки программирования, такие как PostScript, на котором "думают" принтеры, Forth, управляющий роботами, многие научные калькуляторы, а также виртуальные машины для языков семейства Java и .NET.
Если же мы станем обходить дерево в глубину сверху вниз и слева направо, то строка изменится:
В таком виде выражения записываются редко. Но если расставить скобочки, отделяющие части дерева, то получится префиксная скобочная нотация или S-выражение:
Читается она уже не как инструкция, а как описание выражения:
Таким образом строятся выражения и программы на языках семейства LISP: Scheme, Racket, Clojure и в языках символьной математики Maple, Maxima или Wolfram Language, где префиксная нотация используется для внутреннего представления выражений и кода. Именно с методов обработки таких S-выражений, в далёком 1957 году, начались разработки того, что что сейчас называется "искусственным интеллектом".
Обратите внимание, одно и то же выражение, представленное в виде дерева, можно прочесть, как набор инструкций, либо как описание. Эти два подхода лежат в основе двух больших семейств языков программирования: императивных (приказывающих) и декларативных (описывающих).
Противоречивость примера, вынесенного в заголовок, мгновенно исчезнет, как только вы озвучите его, произнесёте вслух. У вас может получиться что-то похожее на инструкцию: "Тридцать шесть поделить на три, умножить на разницу между восемью и шестью, разделить на шесть." Либо некоторое описание: "Произведение отношения тридцати шести к трём, и отношения разности между восемью и шестью к шести." Оба эти варианта соответствуют стандартному прочтению арифметического выражения, при этом первое является императивным, а второе — декларативным.
Экскурс в парадигмы формальных языков будет не полным, если не упомянуть ещё одну популярную концепцию: объектно-ориентированный подход. За десятки лет использования, объектно-ориентированное программирование приобрело как императивные , так и декларативные черты, но в изначальном, так сказать, дистиллированном виде, оно было реализовано в языке SmallTalk, который сейчас принято относить к "эзотерическим". В этом языке числа это объекты, обменивающиеся с другими объектами сообщениями. Например выражение 3 + 2 означает, что объект "три" отправляет сообщение объекту "два", которое воспринимает его, как метод "сложение", дающее в результате объект "пять". Что же нового может дать такой подход к чтению арифметических выражений? А то, что цепочка обмена сообщениями принципиально левоассоциативна, то есть, сообщения отправляются слева направо. Таким образом в языке SmallTalk
Если первый пример, как кажется, вычисляется традиционным образом, то второй выглядит странно, должно же получиться 13. В парадигме обмена сообщениями мы получаем, что 3 отправляет сообщение + числу 2, и в результате получается 5, которое, в свою очередь, отправляет сообщение * числу 5 и мы получаем результат 25. Так и выходит, что все сообщения (операции) имеют одинаковый приоритет и левоассоциативны.
Скобки в SmallTalk используются и играют ровно такую же роль, как и в привычной записи, так что на языке SmallTalk выражение 36:3*(8–6)/6 будет читаться так (следите за запятыми): "Тридцать шесть поделить на три, умножить на восемь минус шесть, поделить на шесть." Но если мы уберём скобки, то выражение 36:3*8–6/6 будет в SmallTalk разобрано как: "Тридцать шесть поделить на три, умножить на 8, отнять шесть, поделить на шесть." Если перевести это в дерево, то оно получится таким:
Это дерево существенно отличается от традиционного прочтения выражения 36:3*8–6/6, которое представляет собой разность произведения и отношения.
* * *
Компьютеры-компьютерами, но мозг каждого из нас решает задачу синтаксического разбора каждый день. Например, при обработке речи. Звуки, в отличие от изображений, осязания и иных ощущений, на уровне физики принципиально сериализованы. Мы не можем слышать звуки не один за другим, а как-нибудь целиком (в виде спектра или как-нибудь ещё). Линейная, цепочка звуков, фонем, сначала проходит лексический разбор и нарезается на слова, которые классифицируются в части речи: существительные, прилагательные, глаголы и т.п. А потом происходит синтаксический анализ линейной цепочки слов, сворачивающий эту цепочку во что-то подобное синтаксическому дереву, с которого я начал эту статью.
Большей частью этой лексической и синтаксической работы заняты височные доли нашего мозга, и они, конечно же, не в курсе того, что и как называется. В школе, изучая грамматику родного языка, мы учимся явно вычленять и правильно называть части этого дерева, выделяя в предложениях подлежащее, сказуемое, дополнения и обстоятельства, подключая к височным долям иные отделы коры головного мозга из обоих полушарий.
Когда вы читате этот текст, то сетчатка ваших глаз и зрительная кора головного мозга производят лексический разбор последовательности символов, после чего передают эту последовательность в тот же самый синтаксический и семантические анализаторы, что используются при обработке цепочки звуков, после чего они начинают обретать структуру и смысл.
Но всё это работает тогда, когда грамматика определена корректно и известна полностью. Все споры вокруг задачки с примером, связаны только с тем, что в голове у каждого из нас, не смотря на усилия учителей в школах, настроены немного разные синтаксические анализаторы и вшиты немного отличающиеся грамматики. Отсюда и споры на пустом месте.
Много вы встречали жарких дискуссий на тему двусмысленной фразы "Казнить нельзя помиловать"? Она специально построена с нарушением грамматической структуры и допускает двоякое толкование для демонстрации семантики запятой. Чего тут спорить-то! Вот и про 36:3(8–6)/6 надо не спорить, а рассуждать, что бы это могло значить и почему.