
Pandas – это популярная и надёжная библиотека анализа данных на Python. Она предоставляет структуры данных и функции для управления числовыми таблицами и данными временных рядов. Однако, при работе с огромными наборами данных, Pandas иногда может стать медленным и неэффективным инструментом. В этой статье мы рассмотрим, как мы можем использовать встроенные функции Python и Pandas для более быстрого выполнения вычислительных задач.
Постановка проблемы и предварительные условия
Для анализа давайте сгенерируем поддельные данные о человеке, связанные с возрастом, контактными данными, циклом сна и т.д., и свяжем их с функцией, для которой мы можем сгенерировать миллионы строк, определив размер 10 миллионов, который имеет объём памяти около 460 МБ.
import pandas as pd
import numpy as np
def generate_df(size):
df = pd.DataFrame()
df['age'] = np.random.randint(1,100,size)
df['avg_sleeping'] = np.random.randint(1,24, size)
df['gender'] = np.random.choice(['Male','Female'], size)
df['annual_income'] = np.random.randint(1000,100000, size)
df['phone_number'] = np.random.randint(1_111_111_111, 9_999_999_999, size)
df['favourite_food'] = np.random.choice(['pizza', 'burger', 'chips', 'nachos'], size)
return df
df = generate_df(10_000_000) # 10 million rows.
df.info()
------------------ OUTPUT ------------------
RangeIndex: 10000000 entries, 0 to 9999999
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 age int64
1 avg_sleeping int64
2 gender object
3 annual_income int64
4 phone_number int64
5 favourite_food object
dtypes: int64(4), object(2)
memory usage: 457.8+ MB
Постановка задачи: Нам нужно сгенерировать функцию, которая предоставляет вознаграждение человеку на основе этих условий:
- Если среднее время сна составляет ≥ 6 часов, а годовой доход составляет от 5000 до 10000 долларов, мы дадим ему / ей бонус в размере 15% от текущего дохода.
- Если их возраст составляет от 60 до 90 лет, а их пол женский, то бонус в размере 20%, в противном случае, если пол мужской, то 18%
- по умолчанию будет предоставлена прибавка в размере 10% в дополнение к вышеуказанным условиям.
Ниже представлен код, в котором реализована система вознаграждения для каждого человека:
def reward_function(row):
total_bonus = 0
if (row['avg_sleeping'] >= 6) and (5000 <= row['annual_income'] <= 10000):
total_bonus += row['annual_income']*10/100
if (60<=row['age']<=90) and row['gender'] == 'Female':
total_bonus += row['annual_income'] * 20/100
elif (60<=row['age']<=90) and row['gender'] == 'Male':
total_bonus += row['annual_income'] * 18/100
total_bonus += row['annual_income'] * 10/100
return total_bonus
# A Wrapper function which will help in timing the function
def wrapper(func, *args, **kwargs):
def wrapped():
return func(*args, **kwargs)
return wrapped
Метод 1: Цикл (Beginner)
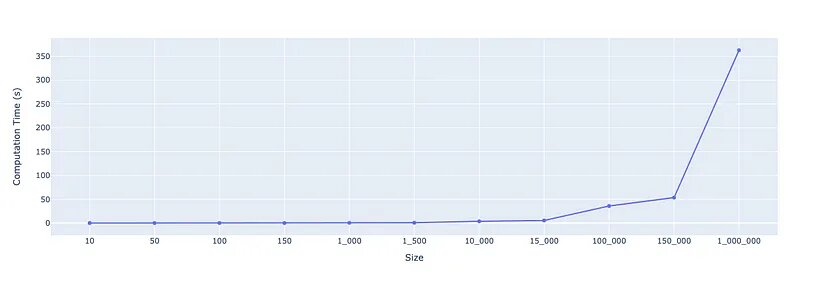
Первый метод заключается в циклическом переборе всех строк с использованием цикла For, который будет протестирован на размер от 10 до 1 миллиона (все числа должны быть кратны 10).
def loop_function(size):
df = generate_df(size)
for idx, row in df.iterrows():
df.loc[idx, 'bonus'] = reward_function(row)
return df
import timeit
sizes = ['10','50', '100','150','1_000','1_500','10_000','15_000','100_000','150_000','1_000_000']
time_loop = []
for size in sizes:
size = int(size)
wrap = wrapper(loop_function, size)
n = timeit.timeit(wrap, number = 10)
time_loop.append(n)
print(f'Size: {size} | Time: {n}')
------------ OUTPUT --------------------
Size: 10 | Time: 0.015464209020137787
Size: 50 | Time: 0.029195624985732138
Size: 100 | Time: 0.04483937501208857
Size: 150 | Time: 0.060746584029402584
Size: 1000 | Time: 0.37726833298802376
Size: 1500 | Time: 0.5435548750101589
Size: 10000 | Time: 3.667369958013296
Size: 15000 | Time: 5.4342494159936905
Size: 100000 | Time: 35.758805999998
Size: 150000 | Time: 53.41354637499899
Size: 1000000 | Time: 362.79915604100097
Метод 2: Apply (Intermediate)
Второй метод заключается в использовании встроенной функции apply, которая автоматически перебирает строки для получения тех же результатов. Можно заметить, что данный метод в 51 раз быстрее, нежели предыдущий.
def apply_function(size):
df = generate_df(size)
df['reward'] = df.apply(reward_function, axis=1)
return df
import timeit
sizes = ['10','50', '100','150','1_000','1_500','10_000','15_000','100_000','150_000','1_000_000']
time_apply = []
for size in sizes:
size = int(size)
wrap = wrapper(apply_function, size)
n = timeit.timeit(wrap, number = 10)
time_apply.append(n)
print(f'Size: {size} | Time: {n}')
------------ OUTPUT -----------------
Size: 10 | Time: 0.012611749989446253
Size: 50 | Time: 0.012881291972007602
Size: 100 | Time: 0.015168334008194506
Size: 150 | Time: 0.017598833015654236
Size: 1000 | Time: 0.07729966600891203
Size: 1500 | Time: 0.12314429198158905
Size: 10000 | Time: 0.7140216250554658
Size: 15000 | Time: 1.0925505409832112
Size: 100000 | Time: 7.15100325003732
Size: 150000 | Time: 10.620125459041446
Size: 1000000 | Time: 71.90183841699036
Метод 3: Векторизация (Advanced)
Третий метод, использующий векторизацию, преобразует вашу функцию в векторизованную функцию, которая может легко выполнять параллельные вычисления. Этот метод в 120 раз быстрее, чем итеративный метод, и в 24 раза быстрее, чем функция apply.
def vectorize_function(size):
df = generate_df(size)
return np.vectorize(reward_function_part)(df['avg_sleeping'], df['annual_income'], df['gender'], df['age'])
import timeit
sizes = ['10','50', '100','150','1_000','1_500','10_000','15_000','100_000','150_000','1_000_000']
time_vector = []
for size in sizes:
size = int(size)
wrap = wrapper(vectorize_function, size)
n = timeit.timeit(wrap, number = 10)
time_vector.append(n)
print(f'Size: {size} | Time: {n}')
------------- OUTPUT ------------------
Size: 10 | Time: 0.009834291995503008
Size: 50 | Time: 0.007047833991236985
Size: 100 | Time: 0.006179624993819743
Size: 150 | Time: 0.006125124986283481
Size: 1000 | Time: 0.011216916958801448
Size: 1500 | Time: 0.011040707991924137
Size: 10000 | Time: 0.036138333030976355
Size: 15000 | Time: 0.05108320800354704
Size: 100000 | Time: 0.3286715000285767
Size: 150000 | Time: 0.4928594169905409
Size: 1000000 | Time: 3.5127678340068087
Заключение
Если сравнить все 3 метода, представленные в этой статье, можно сделать вывод, что каждый последующий метод будет эффективнее, полезнее и быстрее (а также сложнее!).
В заключение, Pandas – это мощная библиотека, которая может значительно ускорить задачи анализа данных. Используя возможности метода векторизации, Pandas может выполнять вычисления намного быстрее, чем стандартные методы, на очень больших наборах данных.
1