
Каждый разработчик, сталкивающийся с PostgreSQL, знает, что отладка базы данных может превратиться в настоящий кошмар, особенно если система большая и сложная. Где искать данные? В какой момент была совершена транзакция? Как понять, в какой таблице «потерялась» та самая запись? К счастью, есть решение, которое облегчает процесс дебага до состояния приятного расследования вместо болезненной рутины.
Сегодня мы поговорим о малоизвестной, но крайне полезной технике дебага приложений на PostgreSQL, которую предложил эксперт в области PostgreSQL Ханс-Юрген Шёниг, глава компании CYBERTEC.
🚀 Наследование таблиц: зачем это вообще нужно?
PostgreSQL, в отличие от многих других СУБД, поддерживает концепцию наследования таблиц. Эта функция позволяет создавать базовые таблицы, от которых наследуются другие таблицы, получая автоматически все колонки и свойства родителя. Казалось бы, зачем это нужно? На практике наследование решает сразу несколько задач:
🔸 Единая структура – гарантирует единообразие данных в разных таблицах.
🔸 Автоматическое добавление полей – упрощает разработку, избавляя от повторного описания идентичных колонок.
🔸 Уникальность данных – использование общей последовательности (sequence) для всех дочерних таблиц.
🎯 Практический пример: таблицы товаров и стран
Представим две таблицы: товары (t_product) и страны (t_country). Чтобы хранить общие данные (например, уникальный идентификатор и временные метки), создаётся родительская таблица t_global:
CREATE TABLE t_global (
id serial,
tstamp timestamptz DEFAULT now()
);
Теперь создадим две дочерние таблицы, наследующие от t_global:
CREATE TABLE t_product (
name text,
price numeric
) INHERITS (t_global);
CREATE TABLE t_country (
country_name text
) INHERITS (t_global);
Добавим тестовые данные:
INSERT INTO t_product (name, price)
VALUES ('Кроссовки', 113.98), ('Колбаса', 4.58);
INSERT INTO t_country (country_name)
VALUES ('Австрия'), ('Германия'), ('Япония');
Что мы получили в результате? 🤔
🔑 Единая последовательность ID – любой ID уникален по всей базе данных.
⏰ Общие временные метки – записи имеют одинаковые временные метки, если были добавлены в одной транзакции.
🔍 Как это помогает в дебаге?
Представьте ситуацию: приложение выдаёт ошибку, связанную с конкретным ID, но вы понятия не имеете, в какой таблице его искать. Обычно для этого нужно проверить каждую таблицу по отдельности. Это долго и неэффективно.
Но используя наследование, вы можете получить всю необходимую информацию одним запросом:
SELECT tableoid::regclass, * FROM t_global;
Результат запроса будет выглядеть примерно так:
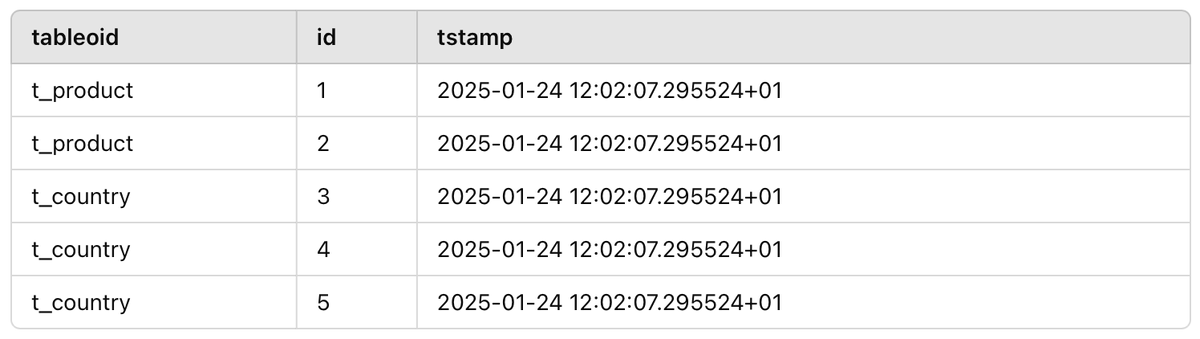
Обратите внимание на колонку tableoid. Эта виртуальная колонка PostgreSQL сразу подсказывает, к какой именно таблице относится запись. Теперь вы не тратите время на поиск, а сразу видите всю картину.
📌 Как увидеть транзакции?
Обратите внимание также на колонку tstamp. Если несколько записей имеют одинаковую временную метку, значит, они были добавлены одной транзакцией. Это позволяет понять:
⏳ Последовательность операций – в каком порядке шла запись данных.
🔗 Связанность данных – какие данные были изменены в рамках одной транзакции.
✨ Дополнительные рекомендации от автора статьи
На своём опыте могу сказать, что эта техника не просто упрощает поиск багов, но и помогает быстро понять внутреннюю логику приложения, даже если вы впервые сталкиваетесь с незнакомым проектом. Я лично считаю её обязательной для крупных проектов и приложений с высокой сложностью.
🛑 Несколько советов:
✅ Используйте единую глобальную таблицу (t_global) только для мета-данных.
✅ Избегайте чрезмерного наследования: лучше иметь чёткую иерархию.
✅ Всегда проверяйте производительность: наследование удобно, но в очень больших системах может иметь некоторые ограничения по скорости операций.
🚧 Подводные камни
Несмотря на удобство, у наследования есть и свои недостатки:
⚠️ Сложность изменения структуры – добавление новой колонки в родительскую таблицу требует модификации всех дочерних.
⚠️ Ограниченные индексы и ограничения (constraints) – наследование не всегда идеально сочетается с ограничениями и индексами, которые могут потребовать дополнительных действий со стороны администратора.
🔗 Ссылки на оригинальную статью и ресурсы:
🔥 Итог
Отладка PostgreSQL не обязательно должна быть мучением. Грамотное использование наследования таблиц может превратить процесс поиска багов в быстрое и удобное действие, экономя вам нервы и время. Попробуйте этот подход уже сегодня – возможно, именно он станет вашим любимым инструментом дебага!
Автор статьи: ваш верный помощник и фанат PostgreSQL 😊