В последнюю версию LM-Studio добавили новую функцию - спекулятивное декодирование. Мы джва года ее ждали. Ниже я расскажу, что это такое и как его использовать.
Speculative decoding или, по-русски, спекулятивное декодирование - это метод ускорения генерации токенов большими языковыми моделями (LLM) за счет использования дополнительной модели меньшего размера.
Спекулятивноедекодирования работает следующим образом. У вас есть две LLM с одинаковым словарем токенов, то есть нельзя использовать модели различных семейств, типа, llama и qwen, а вот llama-3.2-70b и llama-3.2-3b или qwen2.5-coder-32B и qwen2.5-instruct-1B подходят. Основная модель - та у которой больше параметров. Вспомогательная модель, называемая черновик - модель с малым числом параметров, обычно 0,5B-7B.
Без спекулятивного декодирования основная модель авторегрессивно генерирует токен за токеном, например, A -> A + B -> A B + C и т.д.
При спекулятивном декодировании сначала модель черновик находит тем же авторегрессивным способом последовательность токенов, допустим A B C Z E F, затем основная модель проверяет каждый из этих токенов, проверка происходит намного быстрее, чем генерация новых токенов (если кто-то сможет объяснить почему, прошу в комментарии). Если основная модель находит ошибку, например, вместо Z должно быть D, она генерирует токен D и передает его модели черновику, модель черновик генерирует новую последовательность токенов A B C D + E F G J K L, основная модель продолжает проверять и так до конца.
Схематично принцип работы указан на картинке:

Данный алгоритм довольно старый (2023 год или даже раньше) возможно сейчас применяются усовершенствованные алгоритмы, например, я встречал на реддите следующие объяснения:
Спекулятивное выполнение работает следующим образом: вы пытаетесь угадать (предположить) следующие k токенов и надеетесь, что они будут связаны.
Трансформеры работают следующим образом: они пытаются предсказать следующий токен для каждого токена.
Предположим, что ваши токены — это A, B, C, D, E. Обычно для продолжения предложения нужно декодировать их по одному: Decode(E) → F, Decode(F) → G и т. д.
Однако вы можете использовать быструю модель для прогнозирования следующих пяти символов: E, F, G, H, I.
Затем вы можете декодировать их одновременно: Decode(E, F, G, H, I) и надеяться, что они совпадут (то есть вы получите F, G, H, I для следующих токенов из основной модели).
И еще такое:
При спекулятивном декодировании вы загружаете модель A, а затем выбираете другую модель B и загружаете её в качестве «предварительной модели». Обычно A — это очень большая модель, например 70b, а B — очень маленькая модель, например 3b.
Во время вывода эти две модели будут считывать контекст вместе, а затем маленькая модель начнет пытаться угадать, какие токены использовать в ответе. Таким образом, крошечная модель может выдать 8 возможных токенов в качестве следующего токена для ответа, большая модель оценит эти 8 и либо примет один из них (пропустит), либо провалит их все, и в этом случае она генерирует сам токен.
Используя этот метод, вы можете значительно ускорить реакцию модели A, потому что 3b может очень быстро угадать множество токенов, а большой модели остаётся только сказать «да» (самый быстрый вариант) или «нет, я сделаю это сам» (самый медленный вариант).
Нам не особо важны детали работы этого алгоритма, главное, что теперь мы его можем использовать без танцев с бубном. В LM Studio с версии 0.3.10 завезли speculative decoding включающийся в 1 клик.
В правой панели появилась настройка speculative decoding, в которой можно просто из выпадающего списка выбрать модель черновик и генерировать ответы значительно быстрее. Переключатель Visualize accepted draft tokens включает выделение цветом тех, токенов, которые были сгенерированы черновиком и приняты основной моделью.
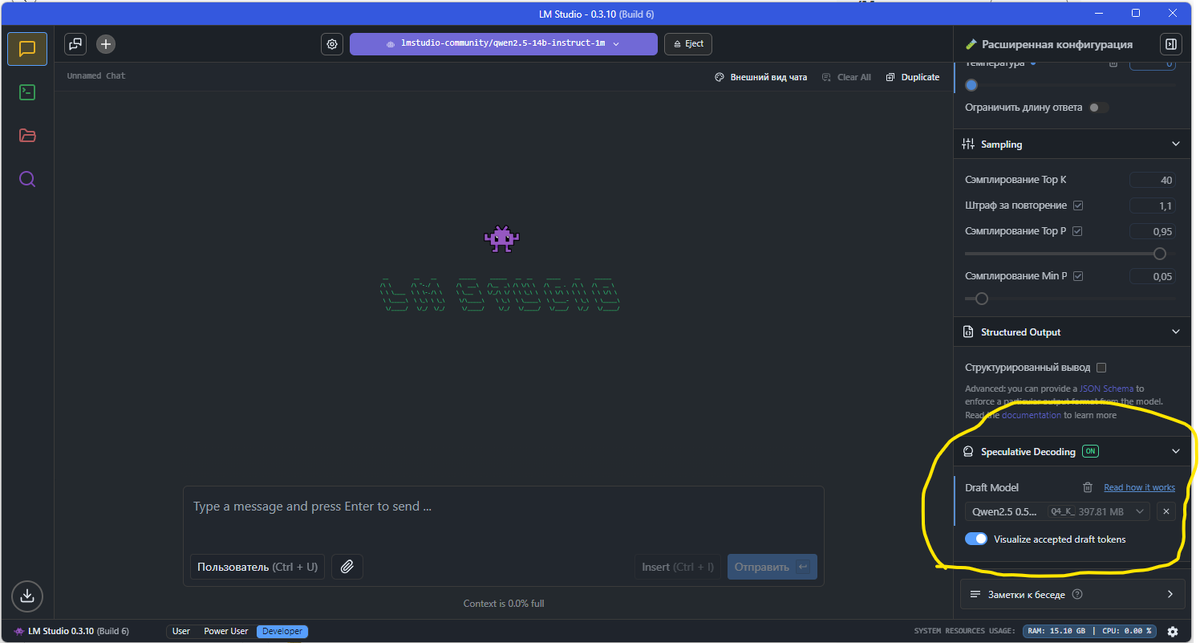
Для пробы я использовал в качестве основной модели:
Qwen2.5-14B-Instruct-1M-Q8_0.gguf
В качестве черновиков:
Qwen2.5-0.5B-Instruct-Q4_K_M.gguf
qwen2.5-3b-instruct-Q4_K_M.gguf
Qwen2.5-14B-Instruct-1M-IQ2_XS.gguf
В итоге получилась следующая картина:
Без спекулятивного декодирования 1.89 tok/sec (да, я использую процессор).
С черновиками:
Qwen2.5-0.5B-Instruct-Q4_K_M.gguf - 2.24 tok/sec Accepted draft tokens 36.4%
qwen2.5-3b-instruct-Q4_K_M.gguf - 2.32 tok/sec Accepted draft tokens 50.9%
Qwen2.5-14B-Instruct-1M-IQ2_XS.gguf - 1.46 tok/sec Accepted draft tokens 51.8%
Как видите ускорение на грубом тесте более чем на 20 процентов. Также, можно заметить, что чем умнее черновая модель, тем больше совпадающих токенов, но чем больше черновая модель, тем медленнее происходит генерация, поэтому важно поймать золотую середину для максимальной скорости.
На этом у меня все, пишите комментарии.