
В последние годы мы привыкли, что большие языковые модели (LLM) обучаются авторегрессионно — от GPT до LLaMA всё крутится вокруг предсказания следующего токена в последовательности. Но проект LLaDA (Large Language Diffusion with mAsking) показывает, что можно добиться сопоставимого уровня интеллекта и гибкости, используя совершенно другую парадигму генерации — диффузионную.
Что такое LLaDA и почему это интересно?
🌀 От авторагрессии к диффузии
В традиционных LLM формируется контекст слева направо, строка за строкой. LLaDA же работает с идеей «маскировки и восстанавливания» (masked diffusion), что исторически применялось в области диффузионных моделей для изображений и других типов данных.
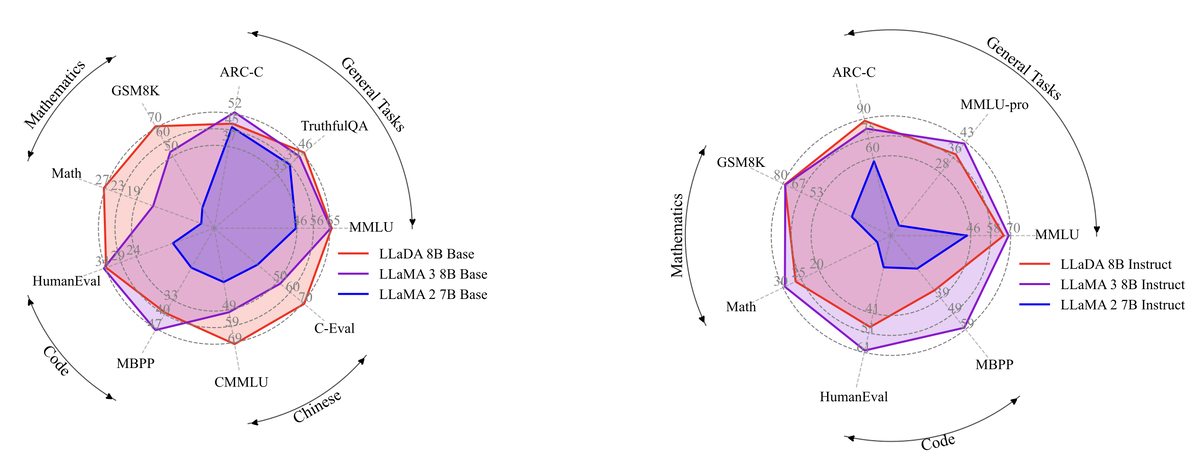
🤖 Сопоставимые результаты с LLaMA3 8B
Авторы указывают, что LLaDA, имея масштаб 8B параметров, успешно конкурирует с LLaMA3 того же размера. Причём все слои и параметры обучены с нуля, то есть модель не использует предварительно натренированный чекпойнт.
✏️ Генерация с «маскированным восстановлением»
Во время обучения часть токенов (иногда все) заменяются масками, и модель учится «восстанавливать» их. В SFT (Supervised Fine-Tuning - контролируемая донастройка модели) маскируются только ответные токены, благодаря чему модель сосредотачивается на генерации релевантных частей диалога, при этом сохраняя контекст.
Технические детали: как устроен процесс
🔎 Рассеяние/Диффузия (Diffusion)
Идея в том, что модель пошагово «превращает» полностью замаскированный текст в открытый, на каждом этапе предсказывая, какие токены надо восстановить. При этом возможен гибкий ре-маскинг: если какие-то участки остались непредсказанными или сильно искажены, их можно «доработать» на следующем шаге, уточняя генерацию модели.
⚙️ Предобучение + SFT
- Предобучение (Pretraining): Случайная маскировка всех токенов (в разных соотношениях), чтобы модель научилась основным закономерностям языка.
- Контролируемая донастройка модели (Supervised Fine-Tuning - SFT): Теперь маскируются только ответы, чтобы отточить навыки генерации отклика на пользовательские запросы (как в диалоговой LLM).
Масштабирование и результаты
🚀 Масштабируемость (Scalability)
Разработчики провели эксперименты на ряде бенчмарков (MMLU, ARC, C–MMLU, PIQA, GSM8K, HumanEval). Графики показывают, что «кривая роста» LLaDA сравнима с авторегрессионными моделями: при увеличении параметров (8B и выше) качество сильно поднимается.
📝 Формирование текста «не слева направо»
Авторы подчеркивают, что генеративный процесс идёт иначе, чем в GPT-подобных моделях. Однако итоговый текст выглядит так же связно — мы видим в примерах, как LLaDA решает математические задачи, рекомендует фильмы, переводит тексты и ведёт диалоги.
Примеры использования
🧮 Решение математических задач
По диалогам видно, что LLaDA:
- Понимает арифметические действия (например, рассчитать общее число клипов, проданных за несколько месяцев).
- Может динамично поддерживать контекст (добавлять новые вычисления, когда пользователь меняет условия).
🎬 Рекомендации фильмов
Предлагает «The Shawshank Redemption», «The Godfather» и «The Empire Strikes Back», снабжая каждого кратким описанием — классический пример простого «опросного» сценария.
💻 Генерация кода на Python
Показывает простой пример сортировки массива «от большего к меньшему» с использованием .sort(reverse=True).
🌐 Переводы на разные языки
Модель умеет переводить между английским, китайским, немецким и при этом сохранить смысл (Пусть и с небольшими стилистическими огрехами — «immaginiert» вместо «imaginiert»(воображаемый), но смысл передан правильно).
Личный взгляд: будущее диффузионных LLM
На мой взгляд, LLaDA — это демонстрация того, что «авторегрессия» не единственный путь к развитому «языковому интеллекту». Основные причины, почему это может оказаться прорывом:
✨ Универсальность
Если диффузионная модель действительно способна конкурировать на уровне больших бенчмарков, то у нас появляется ещё один сильный класс генеративных архитектур. В будущем, возможно, мы сможем объединять преимущества диффузионных и авторегрессионных методов для более устойчивых моделей.
💡 Гибкость масок
В диффузионном подходе можно «переосмысливать» фрагменты ответа, вести пошаговую доработку (iterative refinement), проще встраивать логику правок, что может быть удобно для редактирования длинных текстов.
⚙️ Отображение в другие домены
Уже были работы, где диффузия применялась для картинок, аудио. Если LLaDA эффективно работает с текстом, возможно, появятся мультимодальные модели, которые единообразно обрабатывают изображение, звук и текст в рамках одного принципа.
Ссылки и детали для ознакомления
Заключение
LLaDA — это любопытная веха в том, что «большие языковые модели» вовсе не обязаны быть авторегрессионными. Диффузионный способ генерации позволяет достичь сходного качества и демонстрирует внушительную масштабируемость. Тенденция «больших диффузионных LLM» может дать нам новые горизонты развития диалоговых ассистентов и инструментов работы не только с текстом, но и с аудио и видео.