
Когда речь заходит о «визуальной ETL» — превращении изображений, сканов документов и прочих медиафайлов в удобные для дальнейшей автоматизации объекты, многим из нас хочется чего-то простого и надёжного. Проект VLM Run Hub как раз предлагает решение: набор заранее определённых Pydantic-схем и инструментов для удобного извлечения данных из самых разных источников. Но самое интересное — это возможность локальной обработки с помощью Ollama и структурированных ответов, валидируемых Pydantic.
Зачем вообще нужны Pydantic-схемы?
🚦 Точность и надёжность
Когда вы просите модель «вытащи мне поля из водительского удостоверения», размытые ответы, вроде «Наверное, номер такой-то» или «Да, фамилия там есть», не подходят. С помощью Pydantic вы заранее определяете поля (например, license_number, issue_date, address), и модель обязана вернуть их в конкретном формате, включая нужные типы (дата, число, строка).
✨ Более чистый пайплайн
Вместо того, чтобы писать парсер, который должен угадывать, где там лежит номер лицензии, всё делает модель, а Pydantic проверяет, что формат правильный — без «лишних» угловых скобочек или кривых JSON-ответов.
🧩 Универсальность
Схемы «document.invoice», «document.us-drivers-license», «healthcare.medical-insurance-card» и многие другие позволяют охватить разные индустрии (финансы, здравоохранение, розница и другие индустрии). Одни и те же данные потом легко подать в ваш CRM, в бухгалтерский модуль или в другую систему.
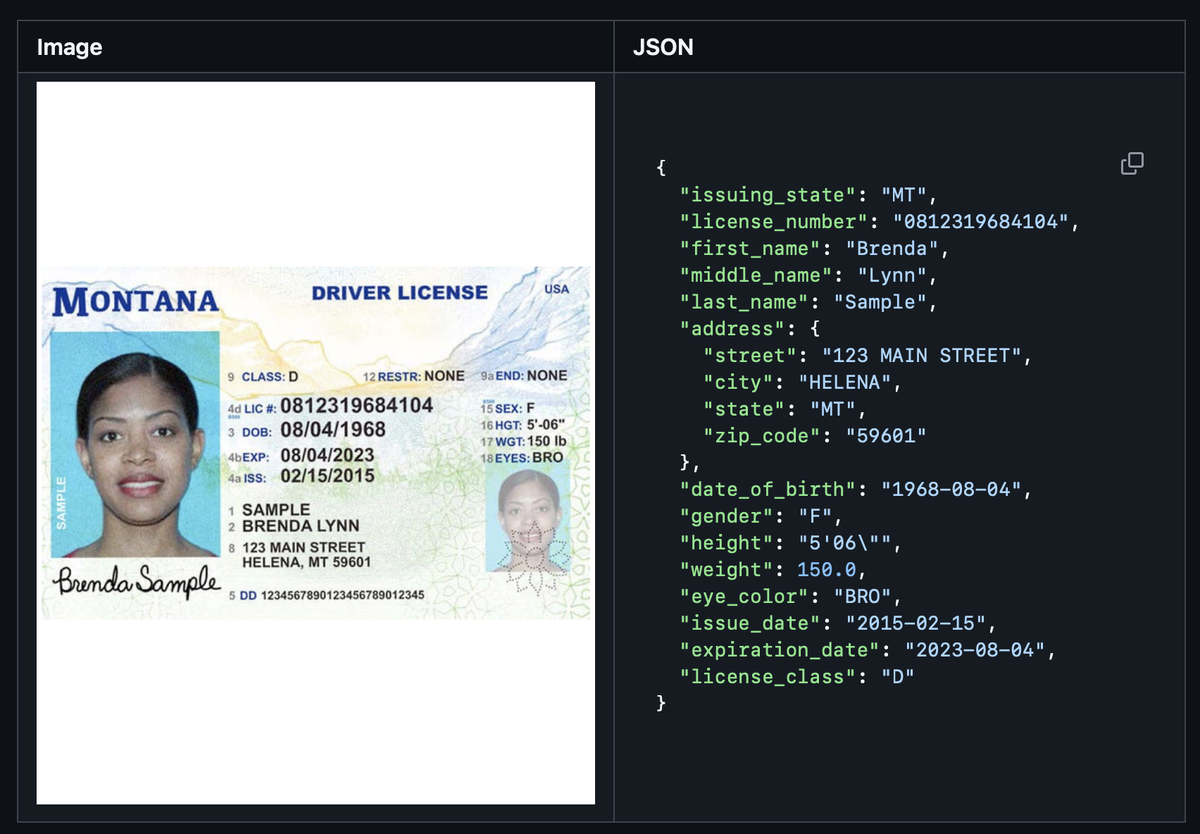
Особенности VLM Run Hub
🧰 Библиотека готовых схем
В репозитории vlm-run/vlmrun-hub есть каталог, где вы найдёте всё — от банковских выписок до документов типа W2-формы (налоговая декларация в США). Под каждую сущность уже заготовлены поля, валидаторы, тест-кейсы.
🖼️ Ориентировано на изображения
Это не просто распознавание текста: схемы учитывают, что в одной картинке может быть много структурированной информации. Благодаря подходу VLM (Vision Language Models), можно анализировать и текст, и визуальные элементы.
⚙️ Интеграция с Ollama
Ollama — инструмент для локальных LLM (например, Llama3.2-vision) без необходимости отправлять данные во внешние API. Это отличное решение, если у вас конфиденциальные документы или требуется работа в офлайн-режиме.
🚀 Совместимость с разными провайдерами
Если вам нужен OpenAI GPT-4o, Anthropic Claude Vision или даже Gemini 2.0 — настройка схем остаётся прежней, меняется только источник моделирования. Это полезно, если вы хотите сменить провайдера без необходимости переписывать большую часть кода.
Пример: извлекаем данные из счёта-фактуры
Допустим, у нас есть скан-счёт (invoice). Мы берём из vlmrun.hub.schemas.document.invoice класс Invoice, а затем вызываем модель, чтобы она вернула JSON. Для Ollama это выглядит так:
from ollama import chat
from vlmrun.common.image import encode_image
from vlmrun.common.utils import remote_image
from vlmrun.hub.schemas.document.invoice import Invoice
IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg"
img = remote_image(IMAGE_URL)
chat_response = chat(
model="llama3.2-vision:11b",
format=Invoice.model_json_schema(),
messages=[
{
"role": "user",
"content": "Extract the invoice in JSON.",
"images": [encode_image(img, format="JPEG").split(",")[1]],
},
],
options={
"temperature": 0
},
)
response = Invoice.model_validate_json(chat_response.message.content)
🪄 Что тут происходит?
- 🔍 remote_image скачивает картинку.
- 🔀 encode_image преобразует её в base64, чтобы Ollama мог её «увидеть».
- 🎨 chat вызывает вашу локальную модель (к примеру, llama3.2-vision:11b), при этом вы указываете формат JSON прямо в format=Invoice.model_json_schema().
- ✅ model_validate_json проверяет, что ответ точно соответствует схеме Invoice.
Нюансы реализации
🤖 Код написан на Python, с использованием Pydantic
Это значит, что любая IDE (PyCharm, VSCode) будет вам подсказывать поля и типы, а при необходимости можно расширить схему своими валидаторами — например, проверять, что сумма счёта не отрицательная.
⚙️ Обратная связь для модели
Если модель вернула что-то «не то», Pydantic выдаст ошибку, и вы можете либо сообщить это модели в виде дополнительного сообщения (prompt engineering), либо перезапустить процесс с учётом корректировок.
⏫ Catalog.yaml
В корневом репо есть каталог, где хранятся все доступные схемы. Каждая схема содержит поля (fields) и описания (descriptions), и всё это автоматически проверяется специальными тестами.
Личный взгляд: чем полезно и как можно развивать
Я вижу несколько сценариев, где VLM Run Hub + Ollama и Pydantic будут особенно хороши:
🔎 Рутинная оцифровка
Представьте, что вы кадровик (HR), и вам поступает поток резюме в формате PDF или изображений. Модель может извлекать ключевую информацию (ФИО, контакты, навыки) по заранее заданной схеме.
💰 Финансы
Счета, чеки, банковские выписки. Никакой магии с RegEx: всё делается через «vision+language». Главное, чтобы текст был читабелен для модели.
🏥 Медицинские карты
Особенно актуально, если хотите локально хранить чувствительные данные, не отправляя их во внешнее API. Настраиваете Ollama и пусть модель обрабатывает сканы медицинских карточек, выписок, страховых документов и других документов.
Где посмотреть и что дальше
Если вы хотите погрузиться глубже, можно глянуть на:
- catalog.yaml — где зарегистрированы все схемы.
- tests/ — пример автотестирования корректности схем.
Итог: Благодаря VLM Run Hub мы получаем удобный, модульный и типизированный способ превращать произвольные документы/изображения в достоверные JSON-объекты. А связка с Ollama даёт возможность работать локально — не беспокоясь о конфиденциальности данных. На мой взгляд, это крутой шаг вперёд для разработчиков, которые хотят встроить «визуальное понимание» в свои приложения и при этом сохранить структуру и надёжность данных.