В сегодняшней статье мы расскажем, как развернуть DeepSeek локально без каких-либо затрат. Но сначала давайте кратко рассмотрим, почему вообще стоит рассматривать локальное развертывание.

Почему стоит локально развертывать DeepSeek-R1?
DeepSeek-R1, хотя, возможно, уже не самая мощная модель рассуждений, но определенно остается одной из самых популярных моделей рассуждений. Поэтому, если вы используете официальный сайт или другие хостинговые сервисы, вы часто можете столкнуться со следующей неприятной ситуацией:
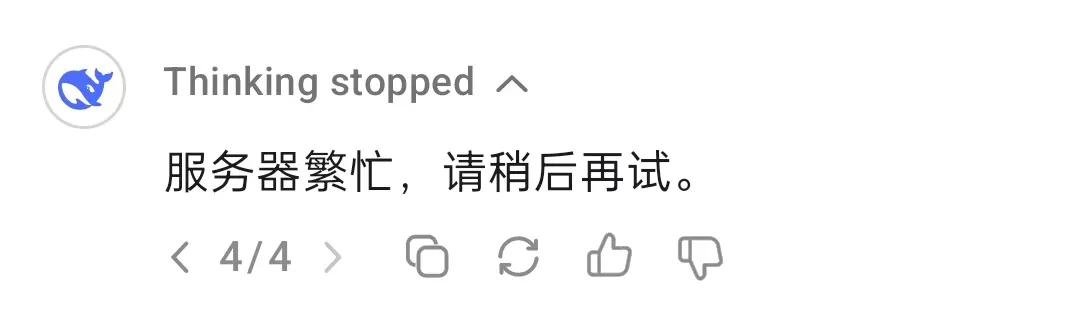
Локальное развертывание модели может эффективно предотвратить такие ситуации. Проще говоря, локальное развертывание означает установку ИИ-модели на ваше собственное устройство, без зависимости от облачных API или онлайн-сервисов. Распространенные методы локального развертывания включают:
- Легковесный локальный инференс: запуск на персональном компьютере или мобильном устройстве (например, Llama.cpp, Whisper, модели в формате GGUF).
- Развертывание на сервере/рабочей станции: использование высокопроизводительных GPU или TPU (например, NVIDIA RTX 4090, A100) для запуска больших моделей.
- Частное облако/внутренний сервер: развертывание на корпоративных серверах (с использованием TensorRT, ONNX Runtime, vLLM).
- Периферийные устройства: запуск ИИ на встраиваемых или IoT-устройствах (например, Jetson Nano, Raspberry Pi).
Локальное развертывание имеет свои сценарии применения, например:
- Корпоративный ИИ (например, приватные чат-боты, анализ документов);
- Научные вычисления (например, биомедицинские, физическое моделирование);
- Оффлайн ИИ-функции (например, распознавание речи, OCR, обработка изображений);
- Аудит безопасности и мониторинг (например, юридический и финансовый комплаенс-анализ).
В этой статье мы в основном сосредоточимся на легковесном локальном инференсе, который подходит большинству индивидуальных пользователей.
Преимущества локального развертывания
Помимо фундаментального решения проблемы "сервер занят", локальное развертывание имеет и другие многочисленные преимущества, включая:
Конфиденциальность и безопасность данных
При локальном развертывании ИИ-модели вам не нужно загружать критическую информацию в облако, что эффективно предотвращает утечку данных. Это особенно важно для финансовой, медицинской и юридической отраслей. Кроме того, локальное развертывание помогает соответствовать корпоративным или региональным требованиям по данным (например, китайскому "Закону о безопасности данных" или GDPR в ЕС).
Низкая задержка и высокая производительность в реальном времени
Поскольку при локальном развертывании все вычисления происходят локально без сетевых запросов, скорость инференса полностью зависит от вычислительной мощности вашего устройства. Следовательно, если ваше устройство достаточно мощное, вы можете получить отличную производительность в реальном времени, что делает локальное развертывание идеальным для приложений, где критично время отклика (например, распознавание речи, автономное вождение, промышленный контроль).
Более низкие долгосрочные затраты
Локальное развертывание избавляет от необходимости оплачивать API-подписки, позволяя использовать модель на долгосрочной основе после одноразового развертывания. Кроме того, если у вас нет высоких требований к производительности модели, вы можете контролировать аппаратные затраты, развертывая облегченные модели (например, с 8-битной или 4-битной квантизацией).
Возможность автономного использования
Возможность использовать ИИ-модели без подключения к интернету подходит для периферийных вычислений, автономной работы и удаленных сред. Поскольку ИИ-приложения могут работать без интернета, это гарантирует непрерывность критически важных бизнес-процессов.
Высокая степень настройки и контроля
Возможность тонкой настройки и оптимизации моделей для лучшего соответствия бизнес-требованиям. Например, DeepSeek-R1 был точно настроен и дистиллирован в различные версии, включая неограниченную версию deepseek-r1-abliterated и другие. Кроме того, локальное развертывание не зависит от изменений политики третьих сторон, обеспечивая высокую степень контроля и избегая повышения цен на API или ограничений доступа.
Недостатки локального развертывания
Несмотря на множество преимуществ, нельзя игнорировать недостатки локального развертывания, главным из которых являются вычислительные требования больших моделей.
Высокая стоимость оборудования
Локальные устройства обычных пользователей часто не могут запускать модели с большим количеством параметров, а модели с меньшим количеством параметров обычно имеют худшую производительность, что требует компромисса. Если пользователь хочет запускать высокопроизводительные модели, необходимо инвестировать больше средств в оборудование.
Ограниченная способность обрабатывать масштабные задачи
Когда задачи требуют масштабной обработки данных, часто необходимо серверное оборудование для эффективного выполнения.
Определенный технический порог
В отличие от использования облачных сервисов, где достаточно открыть веб-страницу или настроить API, локальное развертывание требует определенных технических знаний. Если пользователь также планирует локальную тонкую настройку, сложность развертывания увеличивается. К счастью, этот порог со временем снижается.
Необходимость в обслуживании
Пользователям нужно вкладывать усилия и время в решение проблем с конфигурацией окружения, возникающих из-за обновлений моделей и инструментов.
Выбор между локальным развертыванием и использованием онлайн-моделей зависит от конкретной ситуации пользователя. Вот краткое резюме подходящих и неподходящих сценариев:
- Подходит для локального развертывания: высокая конфиденциальность, низкая задержка, долгосрочное использование (например, корпоративные ИИ-ассистенты, юридический анализ).
- Не подходит для локального развертывания: краткосрочные эксперименты, высокие вычислительные требования, зависимость от больших моделей (например, с 70B+ параметрами).
Как локально развернуть DeepSeek-R1?
Существует множество способов локального развертывания DeepSeek-R1. Здесь мы кратко представим два метода: развертывание на основе Ollama и бескодовое развертывание с помощью LM Studio.
Развертывание DeepSeek-R1 на основе Ollama
Далее мы расскажем, как развернуть DeepSeek-R1 на вашем устройстве с помощью Ollama.
Ollama - это наиболее часто используемый фреймворк для локального развертывания и запуска языковых моделей. Он очень легковесный и хорошо масштабируемый. Как видно из названия, Ollama появился после выпуска Meta серии моделей Llama. Однако это проект, управляемый сообществом, и не имеет прямой связи с Meta или разработкой серии моделей Llama.
После своего появления проект Ollama развивался очень быстро, как с точки зрения количества поддерживаемых моделей, так и в плане поддерживающих его экосистем.
Первый шаг использования Ollama очень прост: скачайте и установите Ollama, посетив следующий адрес и загрузив версию, подходящую для вашей операционной системы.
Ссылка для скачивания: https://ollama.com/download
После установки Ollama вам нужно настроить ИИ-модель для вашего устройства. Рассмотрим пример с DeepSeek-R1. Сначала посетите сайт Ollama, чтобы ознакомиться с поддерживаемыми моделями и их версиями: https://ollama.com/search. Здесь мы видим, что DeepSeek-R1 имеет 7 разных размеров от 1.5B до 671B параметров и 29 различных версий, включая некоторые модели, полученные путем тонкой настройки, дистилляции или квантизации на основе открытых моделей Llama и Qwen.
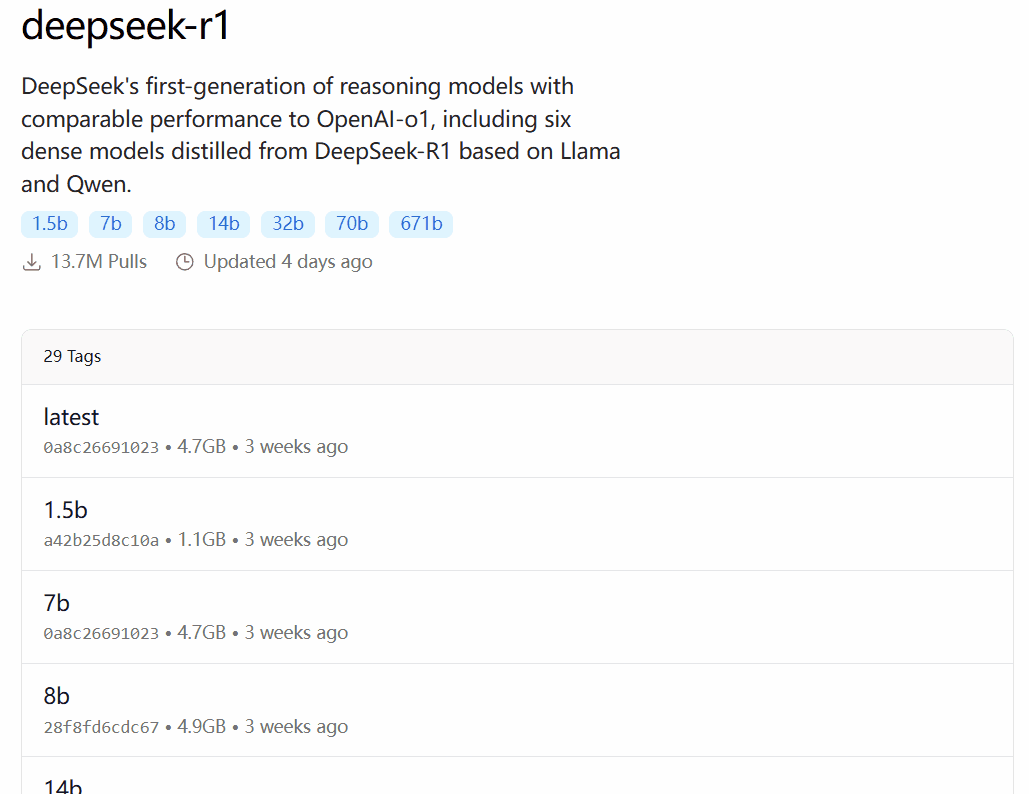
Чтобы выбрать подходящую версию, сначала нужно понять свои аппаратные возможности. Avnish из сообщества разработчиков dev.to написал статью, кратко суммирующую аппаратные требования различных версий DeepSeek-R1, которую можно использовать как ориентир:
Для примера возьмем версию 8B: откройте терминал на вашем устройстве и выполните команду
ollama run deepseek-r1:8b
Затем дождитесь завершения загрузки модели. (Ollama теперь также поддерживает прямую загрузку моделей с Hugging Face, команда для этого: ollama run hf.co/{username}/{repo}:{quantized_version}, например, ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0.)
После завершения загрузки модели вы можете напрямую общаться с 8B версией DeepSeek-R1 в этом терминале.
Однако для обычных пользователей такой способ общения крайне неудобен и непрактичен. Поэтому нам нужно настроить удобный интерфейс. Выбор интерфейсов довольно широк. Мы можем использовать Open WebUI, который предоставляет опыт, подобный ChatGPT, в браузере, или выбрать такие инструменты, как Chatbox. Вы также можете найти подходящий интерфейс здесь: https://github.com/ollama/ollama
- Если вы хотите использовать Open WebUI, просто выполните следующие две команды в терминале:
Установка Open WebUI:
pip install open-webui
Запуск Open WebUI:
open-webui serve
Затем просто посетите http://localhost:8080, чтобы получить опыт, подобный ChatGPT, в вашем браузере.
В списке моделей Open WebUI видно, что Ollama на локальной машине уже настроен с несколькими моделями, включая DeepSeek-R1 7B и 8B версии, а также Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder и другие модели. Выберите DeepSeek-R1 8B и проверьте результат:
2. Если вы предпочитаете использовать DeepSeek-R1 в отдельном приложении, можете рассмотреть такие инструменты, как Chatbox. Настройка также проста: сначала скачайте и установите его: https://chatboxai.app/
После установки запустите приложение, перейдите в "Настройки", выберите OLLAMA API в разделе "Провайдеры моделей", затем выберите нужную модель и установите максимальное количество сообщений в контексте, параметр Temperature и другие соответствующие настройки (хотя можно оставить их по умолчанию).
Теперь вы можете свободно общаться с вашим локально развернутым DeepSeek-R1 в Chatbox. К сожалению, DeepSeek-R1 7B не смог правильно выполнить поставленную нами задачу. Это подтверждает высказанное ранее мнение о том, что обычные пользователи обычно могут запускать на своих локальных устройствах только модели с относительно низкой производительностью. Однако можно предположить, что в будущем с дальнейшим развитием аппаратного обеспечения порог для личного локального использования моделей с большим количеством параметров будет снижаться — и это будущее, вероятно, не за горами.
Конечно, как Open WebUI, так и Chatbox также поддерживают подключение через API к различным моделям DeepSeek, а также к проприетарным моделям, таким как ChatGPT, Claude и Gemini. Вы вполне можете использовать их как повседневный интерфейс для работы с ИИ.
Бескодовое развертывание DeepSeek-R1 с помощью LM Studio
Хотя и не слишком сложно, настройка Ollama и связанных моделей все же требует использования терминала и небольшого количества кода. Если вы все еще считаете это проблематичным/сложным, вы можете использовать LM Studio для бескодового развертывания DeepSeek-R1.
Аналогично, сначала загрузите программу, соответствующую вашей операционной системе, с официального сайта: https://lmstudio.ai
После установки запустите программу и в разделе My Models создайте папку для ваших моделей:
Затем просто загрузите желаемую языковую модель с Hugging Face и поместите ее в настроенную выше папку в соответствии с определенной структурой каталогов (мы также можем использовать встроенную функцию поиска LM Studio, но по нашему опыту она работает не очень хорошо). Обратите внимание, что нам нужны файлы моделей в формате .gguf, например, версии, предоставляемые Unsloth: https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Учитывая наше фактическое аппаратное обеспечение, мы будем использовать дистиллированную версию DeepSeek-R1 (14B параметров), полученную путем тонкой настройки модели Qwen, и выберем версию с 4-битной квантизацией: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
После завершения загрузки поместите ее в ранее созданную папку в соответствии с определенной структурой каталогов: папка_модели/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Затем просто откройте LM Studio, выберите модель для загрузки в верхней части приложения, и вы сможете общаться с вашей локальной моделью.
Главное преимущество использования LM Studio заключается в том, что не требуется работа с терминалом и не нужен никакой код — достаточно уметь устанавливать программы и настраивать папки. Можно сказать, что это крайне дружелюбно к пользователю.
Заключение
Конечно, приведенные выше руководства реализуют локальное развертывание DeepSeek-R1 только на базовом уровне. Если вы хотите дальше интегрировать эту популярную модель в свои локальные рабочие процессы, потребуется дополнительная настройка — от базовой установки системных промптов до более продвинутой тонкой настройки модели, интеграции RAG, функций поиска, мультимодальных возможностей, вызова инструментов и т.д.
Кроме того, с развитием специализированного аппаратного обеспечения для ИИ и технологий малых моделей, порог входа для локального развертывания больших моделей будет и дальше снижаться.
После прочтения этой статьи, попробуете ли вы развернуть свой собственный DeepSeek-R1?
Александр — сооснователь RockAPI, эксперт в области ИИ и разработки API. RockAPI предоставляет неограниченный доступ к передовым моделям ИИ, таким как DeepSeek, GPT-4o, Claude и Gemini, с простой интеграцией и гибкими способами оплаты. Зарегистрируйтесь на https://console.rockapi.ru/ и получите бесплатный стартовый кредит для новых пользователей — начните свое путешествие в мир ИИ уже сегодня!