
Автор Хамель Хусейн
Пошаговое руководство с выводами из более чем 30 внедрений ИИ
Проблема: команды ИИ тонут в данных
Вы когда-нибудь тратили недели на создание системы ИИ, только чтобы понять, что вы понятия не имеете, работает ли она на самом деле? Вы не одиноки. Я заметил, что команды повторяют одни и те же ошибки при использовании LLM для оценки результатов ИИ:
- Слишком много метрик: создание многочисленных измеряемых характеристик, которые становятся неуправляемыми.
- Произвольные системы оценок: использование некалиброванных шкал (например, от 1 до 5) по нескольким измерениям, где разница между оценками неясна и субъективна. Что делает что-то 3 вместо 4? Никто не знает, и разные оценщики часто интерпретируют эти шкалы по-разному.
- Игнорирование экспертов в предметной области: не вовлечение людей, которые глубоко разбираются в предмете.
- Непроверенные метрики: использование измерений, которые на самом деле не отражают то, что важно для пользователей или бизнеса.
Результат? Команды оказываются погребенными под горами показателей или данных, которым они не доверяют и которые не могут использовать. Прогресс останавливается. Все расстраиваются.
Например, я нередко вижу панели мониторинга, которые выглядят так:
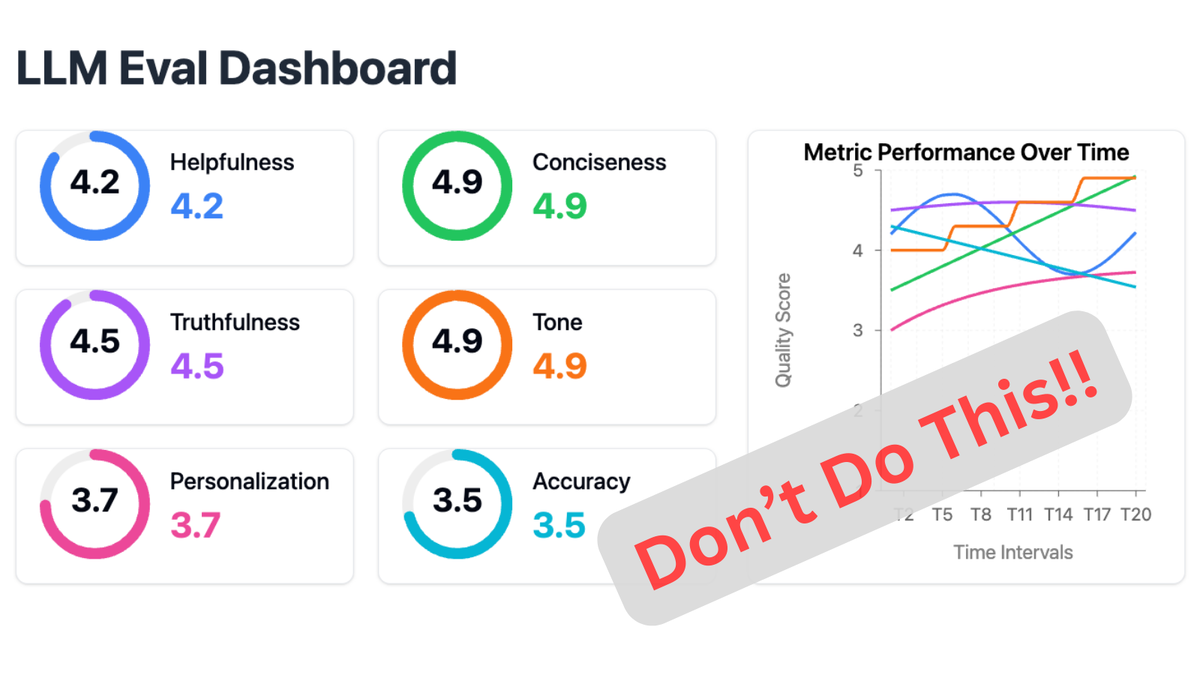
Отслеживание множества оценок по шкале от 1 до 5 часто является признаком плохого процесса оценки (позже я расскажу, почему). В этом посте я покажу вам, как избежать этих ловушек. Решение — использовать технику, которую я называю «Critique Shadowing (Критическое отслеживание)». Вот как это сделать, шаг за шагом (ссылки на английский текст).
Шаг 1: Найдите главного эксперта в предметной области
Шаг 3: Поручите эксперту в предметной области выносить суждения «прошел/не прошел» с помощью критики
Шаг 6: Проведите анализ ошибок
Шаг 7: Создайте больше специализированных LLM-судей (при необходимости)