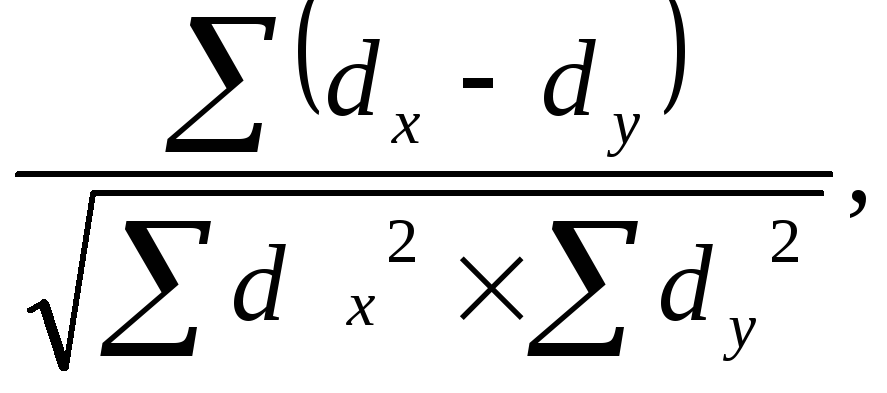
Входные данные
Статистически обработанные значения количеств ожиданий по типам (wait_event_type) , событиям ожиданий (wait_event) на уровне кластера и SQL выражений , за заданный период анализа.
Общая интерпретация значений коэффициента корреляции :
- Очень слабая корреляция: [0 до 0.2]
- Слабая корреляция: (0.2 до 0.5].
- ️Средняя корреляция: (0.5 до 0.7] .
- ️Сильная корреляция: (0.7 до 0.9].
- ️Очень сильная корреляция: (0.9 до 1].
Общая идея и последовательность действий
Шаг 1
Определяется тип ожидания (wait_event_type), имеющий наименьший коэффициент корреляции(❗отрицательная корреляция❗) с операционной скоростью.
—————
⚠️Шаги 2 и 3 применимы только для сценариев нагрузочного тестирования - в случае многократного выполнения тестового запроса.
ℹ️При продуктивной нагрузке , количество выполнений одного запроса , как правило недостаточно , для надежной корреляции.
📝Выполняется только Шаг 1.
—————
Шаг 2
Определяется событие ожидания (wait_event) , имеющий наибольший коэффициент корреляции (❗положительная корреляция❗) с типом ожидания , определённом на предыдущем шаге.
Шаг 3
Определяется SQL запрос, имеющий наибольший коэффициент корреляции (❗положительная корреляция❗) между количеством ожидания(wait_event, определённом на предыдущем шаге) запроса и количеством ожиданий кластера .
ГИПОТЕЗА
Найденный SQL запрос будет запросом , имеющим наибольшее влияние на снижение производительности СУБД, в целом.
Важное дополнение и ограничение.
Чем больше заданный промежуток анализа данных, тем надёжнее результат .
Доказательство
Гипотеза не может быть строго доказана по причине неполноты собираемых данных об ожиданиях СУБД.
Например - не собирается статистика ожиданий CPU.
Возможна ситуация - гипервизор уменьшил тактовую частоту CPU , но со стороны СУБД данное событие никак не будет зафиксировано.
Однако, для практических целей корреляционного анализа ожиданий СУБД, гипотеза может быть принята в качестве рабочей.