
В мире существует множество PDF-документов: от учебных пособий до юридических бумаг. Однако заглянуть в их «внутренности» с позиций структуры данных — задача не из самых простых. Сырые байты PDF включают в себя компрессию, разные типы потоков, перекрёстные таблицы (xref) и массу прочих деталей. Именно поэтому библиотека PDFSyntax предлагает любопытное решение: создавать HTML-страницу, которая не только демонстрирует «распечатку» содержимого, но и обогащает её полезными ссылками и подсветкой ключевых элементов.
Чем интересен PDFSyntax
PDFSyntax — это написанная на Python библиотека без дополнительных зависимостей. Она работает на низком уровне с структурой PDF, но команда browse делает результат визуально понятным даже без серьёзных познаний в PDF-формате.
Что радует особенно?
- Библиотека генерирует статичный HTML, которым можно пользоваться с отключённым JavaScript.
- Вы получаете «сырой» вид данных, но уже со встроенной логикой переходов и цветовой подсветкой, которая указывает на важные поля или предупреждения (например, упоминание /JS).
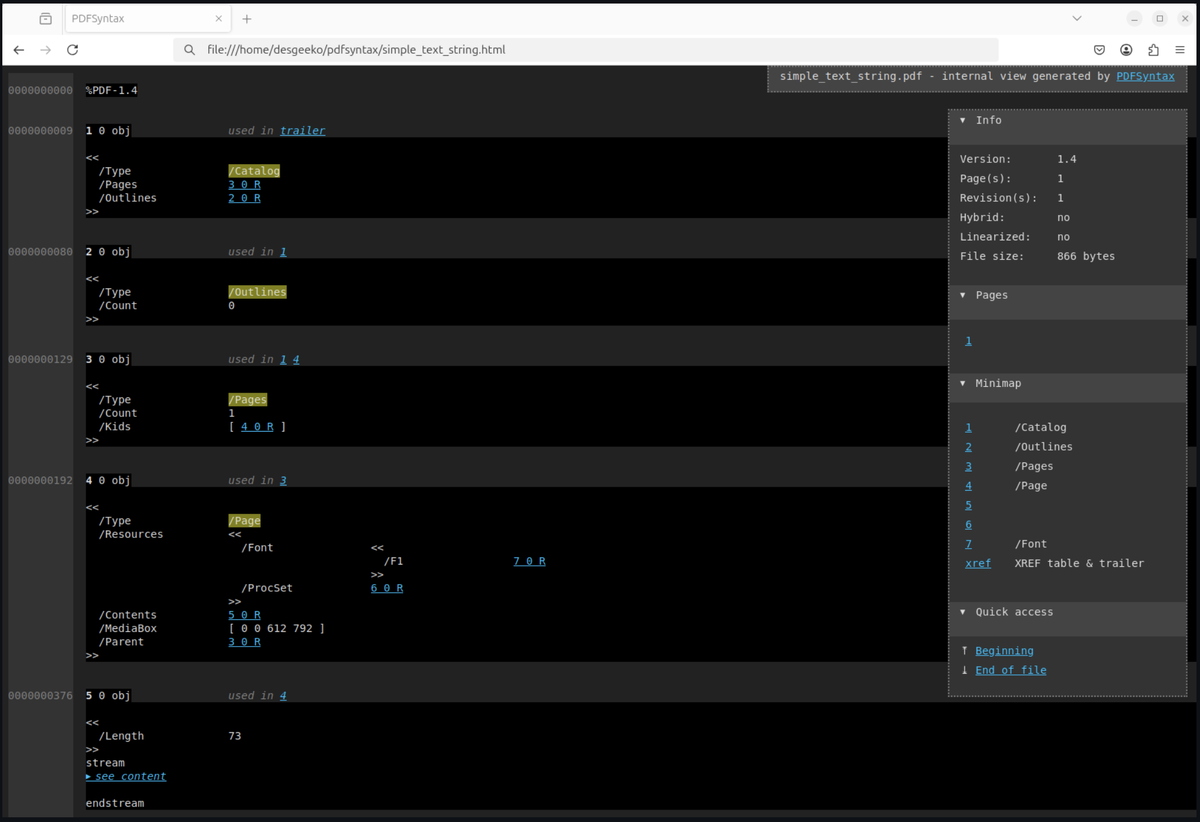
На мой взгляд, это отличный пример инструмента, который ориентирован больше на развитие понимания, чем на прикладную обработку (типа текстового поиска или редактирования). Если вам интересно именно «разобрать» PDF, то PDFSyntax — замечательный вариант.
Архитектура и технические детали
Основная особенность PDFSyntax — минимализм и автономность.
- 🐍 Python-библиотека: никаких внешних зависимостей не нужно, достаточно стандартного Python (3.x).
- 🎯 Низкоуровневая обработка: библиотека самостоятельно отвечает за распаковку потоков, работу со сжатием и определение xref-таблиц.
- 🏷️ Отдельная команда browse внутри pdfsyntax: формирует HTML, который показывает логическую структуру PDF по порядку байтов.
Когда мы говорим «структура PDF», подразумеваем, что, например, объектные потоки будут разобраны, каждая вкладка (объект) получит свою позицию, а ссылки внутри PDF станут гиперссылками в сгенерированном HTML. Удобство очевидно: не нужно вручную искать смещения или индексы, всё это уже превращено в кликабельные элементы.
Как использовать
Чтобы установить библиотеку, достаточно одной команды:
pip install pdfsyntax
А далее очень просто:
python3 -m pdfsyntax browse file.pdf > inspection_file.html
Затем открываете файл inspection_file.html в браузере и видите «расширенный» список объектов PDF, где каждый элемент можно кликнуть, чтобы перейти к нужному месту.
Возможности HTML-визуализации
Вместо простого текстового дампа PDFSyntax добавляет несколько «фишек», делающих изучение файлов намного комфортнее:
🔗 Подсветка ссылок (indirect references) — объекты PDF (к примеру, /Parent 1 0 R) становятся навигационными гиперссылками на соответствующие объекты.
🔎 Интерактивная карта — помимо логической разбивки, есть и «физическая» мини-карта в навигационном меню, которая даёт представление о размере и расположении объектов.
🗂️ Обратный индекс — можно увидеть, где в файле упоминается конкретный объект (например, заметить, что объект №5 используется внутри объекта №10).
📄 Список страниц — быстро пролистать «страницы» или разделы, не блуждая бесцельно по всему файлу.
🎨 Цветовое оформление — ключевые поля выделены цветом, а что-то потенциально опасное (например, /JS, символизирующий JavaScript) тоже явно выделяется.
⚙️ Декодирование и просмотр потоков — файлы PDF часто содержат сжатые потоки. PDFSyntax может показать их содержимое (или часть), что удобно при поиске «скрытых» данных.
Личное мнение: зачем всё это
Для разработчиков, занимающихся PDF на низком уровне, подобная утилита — настоящий клад.
- 🎯 Дебаг: если что-то пошло не так в структуре PDF, HTML-«просмотровщик» от PDFSyntax сразу покажет нарушения или странные ссылки.
- 🔬 Исследования PDF-формата: можно глубже понять, как устроены инкрементальные обновления, дописываемые в конец файла, увидеть все объекты и их взаимосвязи.
- 🗒️ Обучение: замечательный наглядный способ «ощущать» байтовую структуру PDF, не углубляясь в громоздкие спецификации на сотни страниц.
Да, шифрование пока не поддерживается, так что защищённые файлы посмотреть в таком формате не выйдет. Но как говорит автор, в планах много новых функций. Судя по тому, как стремительно развивается сама библиотека, можно ожидать интересных улучшений — возможно, появится даже более глубокая визуализация потоков или дополнительные режимы анализа.
Живой пример
Если хотите почувствовать инструмент «в деле», обязательно посмотрите пример. Там можно пощелкать по ссылкам, поменять темы (светлую/тёмную) и увидеть, насколько удобным может быть раскадрированный и дополненный метаданными PDF.
Ссылки и дополнительная информация
Официальная документация и описание:
HTML visualization of a PDF file's internal structure (GitHub)
Демо:
Полный пример статического HTML
Если вы когда-нибудь столкнётесь со сложной отладкой PDF-документа, помните о PDFSyntax. Это инструмент, который в удобном HTML-формате приоткроет завесу тайн вашего PDF и не заставит ломать голову над байтовыми смещениями. И кто знает, возможно, именно эта библиотека спасёт вас от безумия, когда в очередной раз придётся «копаться» во внутренних структурах формата PDF!