Это сенсация! То, что переведет привычные нам языковые модели на новый уровень.
Опубликована научная статья и представлены веса глубинной рекуррентной модели со скрытыми рассуждениями.
Суть в том (насколько я понял), что если обычная модель состоит из слоев (многослойный перцептрон), обычно их около 40 (в статье модель с 8 слоями), для получения каждого токена все эти 40 слоев просчитываются и на выходе получаем наиболее вероятный токен, то тут добавляется еще один слой (рекуррентный блок), причем добавляется сколько угодно раз для каждого вычисления. В итоге получается модель хоть со 100 слоями, но при этом размер ее не изменяется. Судя по результатам исследования это делает модель гораздо умнее.
Вот краткое содержание статьи:
Увеличение вычислений во время тестирования с помощью скрытых рассуждений: рекуррентный подход к глубине
1. Введение и Проблема (Scaling by Thinking in Continuous Space)
Статья начинается с проведения аналогии между работой предлагаемой модели и человеческим мышлением. Когда мы решаем сложные задачи, мы часто тратим значительное количество времени на внутренние размышления, используя сложные рекуррентные паттерны активации нейронов, прежде чем сформулировать ответ словами.
Традиционные подходы к улучшению производительности языковых моделей (LLM) фокусировались на увеличении их размера, что требует огромных ресурсов.
Альтернативный подход — масштабирование вычислений во время тестирования. Одним из основных методов для этого является Chain-of-Thought (CoT), где модель генерирует промежуточные шаги рассуждения в виде текста.
Однако у CoT есть недостатки: он требует специальных данных для обучения, длинных контекстных окон и ограничен способностью вербализации всех типов мышления. Авторы предлагают кардинально иной подход: позволить модели "думать" в своём внутреннем, скрытом (латентном) пространстве с помощью рекуррентной глубины.
2. Почему рекуррентная глубина? (Why Train Models with Recurrent Depth?)
Во-первых, такой подход не требует специальных данных для обучения, как в случае с CoT. Модель может обучаться на стандартном тексте. Во-вторых, рекуррентность экономит память, позволяя выполнять сложные вычисления без расширения контекстного окна. В-третьих, рекуррентные модели выполняют больше FLOPs на параметр, что снижает затраты на связь между вычислительными устройствами. В-четвёртых, авторы надеются, что такой подход будет способствовать развитию моделей, которые решают задачи с помощью рассуждений, а не простого запоминания. Наконец, предполагается, что рекуррентное мышление в скрытом пространстве может улавливать невербализуемые аспекты человеческого мышления, такие как пространственное воображение или интуиция.
3. Масштабируемая рекуррентная архитектура (A scalable recurrent architecture)
Авторы описывают свою архитектуру, разделяя ее на "макроскопический" и "микроскопический" дизайн.
Макроскопический дизайн: Модель основана на декодер-only трансформере. Она состоит из трех функциональных групп блоков:
- Прелюдия (P) преобразует входные токены в скрытое пространство;
- Рекуррентный блок (R) – это ядро модели, которое итеративно обновляет скрытое состояние. Он принимает на вход:
s_(i-1): Предыдущее скрытое состояние (вектор).
e: Вектор, полученный из прелюдии (представляющий входные данные).
Важно: e подается на вход рекуррентного блока на каждом шаге итерации. Это необходимо для стабильности и сходимости, как показывают предыдущие работы (Bansal et al., 2022).
Блок R обновляет скрытое состояние: s_i = R(e, s_(i-1)). - Кода (C) - последнее скрытое состояние s_r (после r итераций) преобразуется в вероятности для следующих токенов с помощью нескольких слоев трансформера.
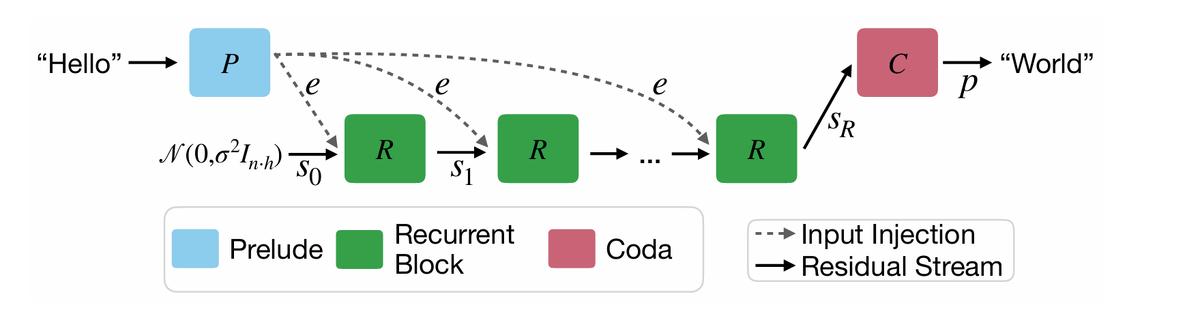
Ключевым моментом является то, что рекуррентный блок R применяется многократно, причем входные данные (выход прелюдии) подаются на вход блока R на каждом шаге. Это обеспечивает стабильность и сходимость. Начальное скрытое состояние выбирается случайно. Параметры рекуррентного блока одинаковы на всех итерациях (weight tying).
Микроскопический дизайн: Внутри каждой группы блоков (P, R, C) используются стандартные слои трансформера: causal self-attention с RoPE, gated SiLU MLP и RMSNorm. Слои упорядочены в "сэндвич" формате (Нормализация -> Внимание -> Нормализация -> MLP -> Нормализация) для стабилизации рекуррентности.
4. Обучение (Training Objective, Training Recurrent Models through Unrolling)
Рекуррентная модель обучается с помощью техники развертывания (unrolling). Количество итераций r рекуррентного блока случайно выбирается для каждого примера во время обучения. Используется лог-нормальное распределение Пуассона, чтобы модель училась использовать разное количество вычислений. Для экономии ресурсов применяется обрезанное обратное распространение ошибки (truncated backpropagation), когда градиенты вычисляются только для последних k итераций. Описываются детали и сложности крупномасштабного обучения модели на кластере Frontier.
5. Результаты (Benchmark Results)
Модель (3.5B параметров, 800B токенов) сравнивается с другими open-source моделями (Pythia, Amber, OLMo) на различных бенчмарках, включая задачи, требующие рассуждений, математических вычислений и программирования. Ключевой вывод: увеличение количества итераций во время тестирования значительно улучшает производительность, особенно на сложных задачах, позволяя модели конкурировать с гораздо более крупными моделями. Степень улучшения зависит от задачи.
6. Упрощение LLM (Recurrent Depth simplifies LLMs)
Показано, что предложенная архитектура естественным образом поддерживает ряд полезных возможностей: адаптивное вычисление (модель сама решает, когда остановиться), совместное использование KV-кэша (снижение потребления памяти) и непрерывный Chain-of-Thought (переиспользование скрытого состояния между токенами). Все это обычно требует специальной настройки в стандартных трансформерах.
7. Возникающие механизмы (What Mechanisms Emerge at Scale in Recurrent-Depth Models)
Авторы анализируют траектории скрытых состояний модели во время итераций. Они обнаруживают, что модель спонтанно развивает различные вычислительные паттерны, такие как сходимость к фиксированной точке, орбиты (для числовых рассуждений) и слайдеры. Важно отметить, что эти паттерны возникают независимо от начального скрытого состояния (path independence).
8. Обзор связанной работы (Related Work Overview)
Раздел помещает данную работу в контекст предыдущих исследований, отмечая связь с рекуррентными нейронными сетями, глубокими равновесными моделями, диффузионными моделями и другими смежными областями.
9. Будущая работа (Future Work)
Обсуждаются потенциальные направления для дальнейших исследований, такие как настройка с подкреплением для лучшего использования вычислительных ресурсов, сжатие рекуррентности и изучение комбинации рекуррентности с разреженностью (mixture-of-experts).
10. Выводы (Conclusions)
В заключении подчеркиваются основные достижения: рекуррентность позволяет масштабировать вычисления без увеличения размера модели, улучшает рассуждение без специальных данных, обеспечивает эффективность и открывает путь к моделям, способным "думать" в своем скрытом пространстве.