В переводе с английского “offset” - это смещение. Допустим, у нас есть такая программка:
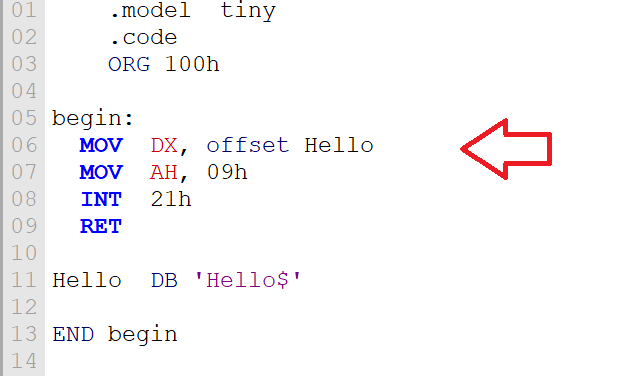
Когда ассемблер доходит до строки 06, он заменяет offset Hello на адрес (смещение) строки, с которой связано имя Hello. В итоге в регистре DX будет нечто вроде этого:
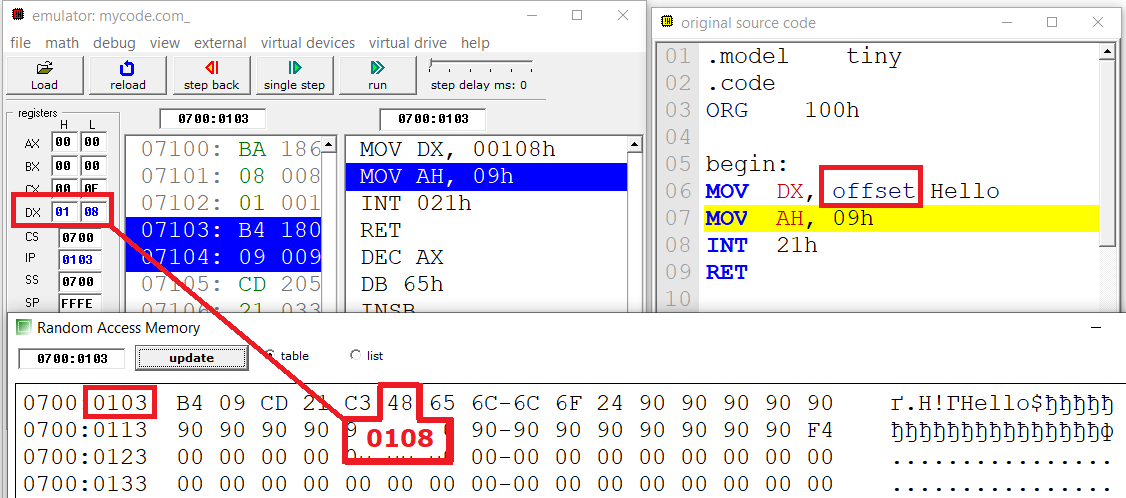
В нашем примере смещение от начала программы равно 0108h. Это число и будет записано в DX.
Если бы мы забыли использовать оператор offset и сделали так:
MOV DX, WORD PTR Hello
то в регистре DX оказался бы не адрес строки, а первые её два байта, то есть буквы He.
Таким образом в регистре DX у нас число 6548h - коды первых двух букв слова Hello.
Почему байты поменялись местами (ведь код английской буквы H - 48h, а буквы е - 65h), надеюсь, вы знаете. Ну а если не знаете, то кратко - у процессоров Интел байты в слове имеют обратный порядок. То есть младший байт (который справа) является как бы первым, а старший - вторым. Поэтому, хотя в памяти, где записана строка, последовательность байтов правильная, при записи слова из памяти в регистр байты этого слова переворачиваются (меняются местами).
Кроме того, выполнение прерывания 21h, скорее всего, привело бы к ошибке, поскольку весьма вероятно, что число, которое мы поместили в DX вместо адреса и которое ассемблер воспринимает как адрес, находился бы за пределами текущего сегмента.
А поскольку у нас СОМ-программа, то вся она должна умещаться в один сегмент и выходить за его пределы мы не должны. Кстати, по этой же причине мы ничего не помещаем в сегментный регистр DS, так как в случае СОМ-программой при её загрузке в память все сегментные регистры принимают значения сегмента, в который загрузилась наша программа.
На этом всё. Надеюсь, погружение в старый добрый 16-разрядный мир “досовских” ассемблерных программ было для вас приятным (ну во всяком случае для тех, кто это помнит))).
Подписывайтесь на канал, чтобы ничего не пропустить.