
Cфера синтеза речи (Text-to-Speech, TTS) постоянно эволюционирует, делая голоса от искусственного интеллекта всё более человечными. Недавняя новость от PlayAI говорит о впечатляющих результатах их новой модели Dialog. Компания заявляет, что люди предпочитают её звучание аж 3:1 по сравнению с ElevenLabs Multilingual v2.0, а против ElevenLabs v2.5 Turbo превосходство вообще достигает 10:1. Ниже — моя интерпретация, почему это важно и какие технические детали стоят за этим.
Почему это интересно?
🔈 Очень реалистичная речь
По отзывам бета-тестеров и независимого исследователя Podonos, пользователи отметили улучшенную «эмоциональную» интонацию PlayAI Dialog, акцентируя «естественную манеру разговора». Для TTS это критически важно, ведь обычные «роботические» голоса отпугивают аудиторию.
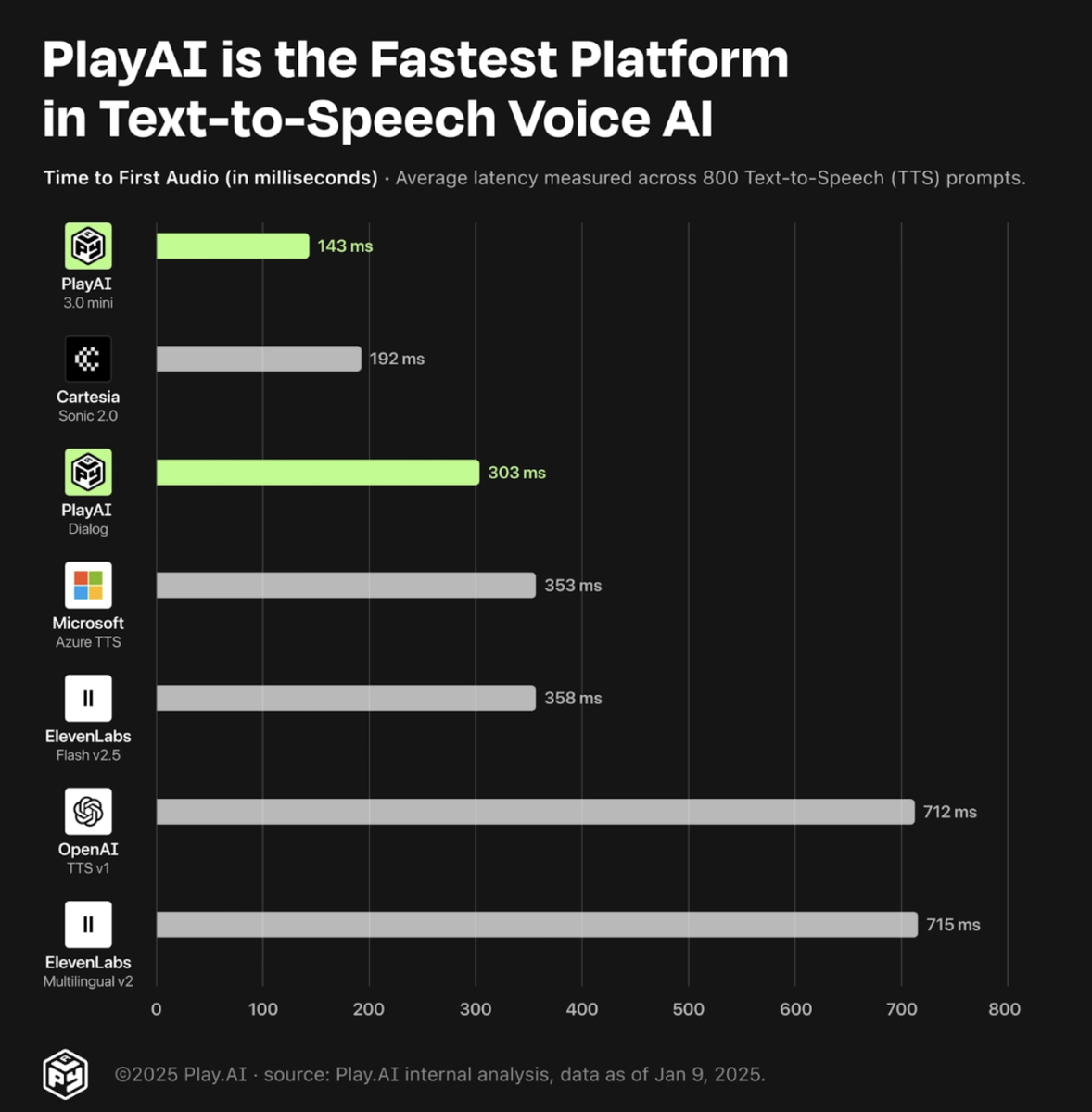
⚡ Низкая задержка (Time-to-First-Audio, TTFA)
Модель соревнуется с версией ElevenLabs v2.5 Turbo, оптимизированной под быстрый вывод речи. Оказывается, Dialog сохраняет сопоставимое время отклика, но звучит «более живо». Таким образом, технология подходит для контакт-центров, автоматизированных голосовых помощников и даже игровых сервисов — там, где медлительный вывод речи неприемлем.
🌐 Мультиязыковая поддержка
Dialog теперь умеет говорить на множестве языков: английский, китайский, французский, немецкий, хинди, японский, корейский, португальский, урду, а ещё 23 языка в экспериментальном режиме. Это открывает двери к глобальным продуктам — можно быстро озвучивать контент практически для любой аудитории.
Технические подробности
🔍 Независимый бенчмарк от Podonos
Тестирование проводилось на 60 одинаковых текстовых примеров (мужские/женские голоса), где 100 респондентов выбирали, какой из синтезов речи звучит более естественно. Итог — около 76% предпочли Dialog против 24% (то есть 3:1), если сравнивать с ElevenLabs Multilingual v2.0.
🔍 Сбалансированность «скорость vs. качество»
В более быстром сценарии (ElevenLabs v2.5 Turbo) у Dialog получился ещё больший разрыв (10:1). Это говорит о том, что PlayAI сумели создать архитектуру, которая хорошо масштабируется по скорости, не теряя качества озвучки.
🔍 API и низкая латентность
PlayAI уточняет, что модель реализована так, чтобы время до первого звука (аудио) (Time-to-First-Audio) был минимальным. Это особенно важно в таких сферах:
- 🎧 Игры и интерактивные приложения: никому не хочется ждать несколько секунд, пока голосовая реплика загрузится.
- ☎️ Колл-центры: задержки в диалогах с оператором, пусть даже виртуальным, снижают удовлетворённость клиентов.
- 🚀 Живые трансляции: некоторые стримеры добавляют голосовой ИИ как часть контента (например, авто-озвучка донатов).
Личное мнение: чего ждать дальше?
С моей точки зрения, конкуренция среди генеративных TTS-моделей становится всё острее. ElevenLabs задали высокую планку — их модель славится «насыщенной» интонацией и мульти-языковым колоритом. Но PlayAI Dialog, похоже, действительно впечатлила своей «человечностью» и скоростью. Интересно, появятся ли в ближайшее время сопоставимые решения от других крупных игроков вроде Google или Amazon, которые вновь толкнут качество вперёд.
Важный момент, который нравится многим разработчикам: обилие языков и возможность быстро переключаться между ними. Так что теперь контентмейкеры и учебные платформы могут автоматически генерировать озвучку для глобальных аудиторий. При этом эмоциональность и тон озвучки повышают вовлечённость пользователей. Радио-станции, например, уже ощутили выгоды: PlayAI упоминает кейс NextKast, где «автоведущий» на радио по качеству оказался близок к настоящему человеку.
Особенности развития TTS и дальнейшие шаги
🗣️ Искусственные DJ и контент
Если PlayAI Dialog действительно сохраняет высокую выразительность, можно ждать всплеска «виртуальных ведущих» на подкастах и радио. Представьте, что интро, реклама, новости — все сгенерировано ИИ и при этом звучит неотличимо от человека.
🧠 Улучшение обучения
Подобные модели часто делают упор на фреймворки вроде трансферное обучение (Transfer Learning) для быстрой адаптации под разные языки. Вероятно, PlayAI активно внедряет новые техники (их упоминание о «низкоуровневых оптимизациях» это косвенно подтверждает).
☑️ Лицензирование и RAW-тесты
PlayAI публикует сырые данные сравнения. Это даёт исследователям и скептикам шанс проверить, насколько результаты воспроизводимы. В будущем, подобные открытые тест-репозитории станут стандартом для TTS-бенчмарков.