Давайте погрузимся в особенности FPGA и их роль в обработке рекуррентных нейронных сетей.
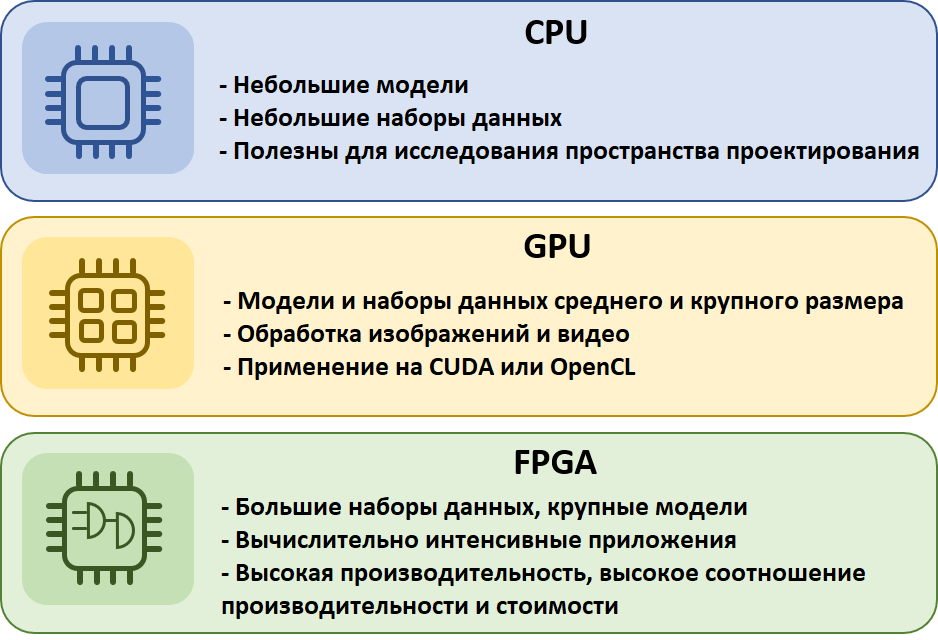
FPGA (Field-Programmable Gate Array) представляют собой уникальную категорию программируемых чипов, которые можно сравнить с "железным" аналогом интерпретатора скриптов. В отличие от традиционных процессоров, где архитектура фиксирована, FPGA позволяют создавать полностью настраиваемые вычислительные пути прямо на кристалле. Это похоже на возможность перестраивать внутреннюю структуру дома по своему усмотрению после его постройки.
Исторически сложилось так, что FPGA изначально использовались в телекоммуникациях и промышленной автоматизации, где требовалась высокая гибкость и надёжность. Однако с ростом популярности искусственного интеллекта эти чипы начали находить всё больше применений в области машинного обучения.
Для массового пользователя важно понимать, что FPGA работают принципиально иначе. Представьте, что обычный процессор – это универсальный швейцарский нож, который может делать многое, но не идеально ни в одной задаче. FPGA же – это возможность создать идеальный инструмент именно под вашу задачу.
Технология основана на матрице программируемых логических элементов, соединённых между собой через конфигурируемые маршруты. Каждый элемент может выполнять простые логические операции, а их совокупность формирует сложные вычислительные цепочки. При этом конфигурация может быть изменена даже во время работы устройства.
Пояснения:
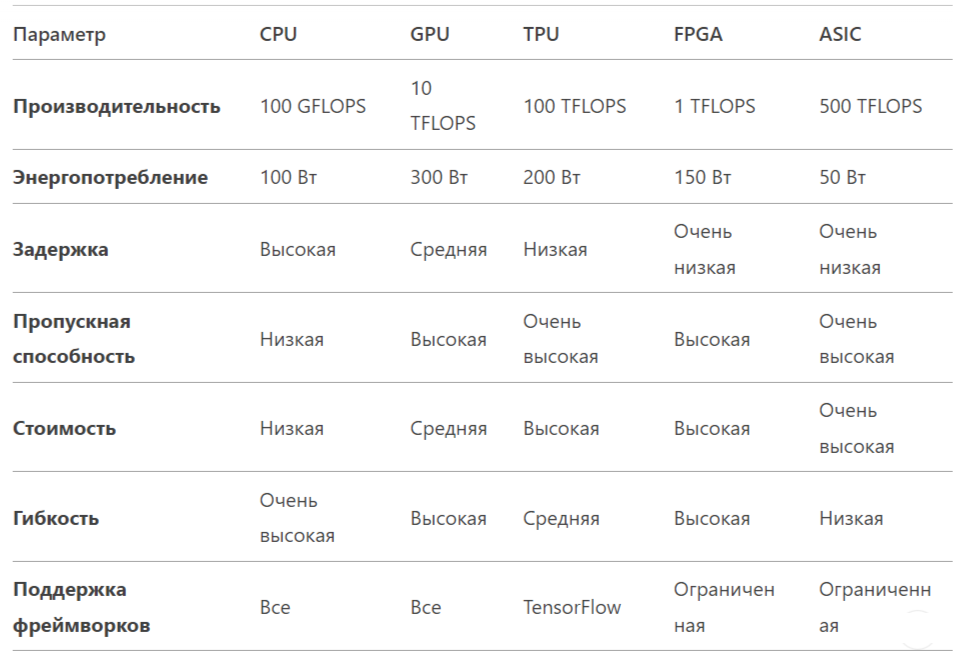
CPU: Универсальные процессоры, подходят для широкого круга задач, но имеют относительно низкую производительность для RNN.
GPU: Графические процессоры, оптимизированы для параллельных вычислений, что делает их подходящими для обучения и выполнения RNN.
TPU: Тензорные процессоры, разработанные Google, специализируются на ускорении операций машинного обучения, включая RNN.
FPGA: Программируемые логические матрицы, обеспечивают гибкость и высокую производительность для специализированных задач.
ASIC: Специализированные интегральные схемы, разработанные для конкретных задач, таких как ускорение RNN, обеспечивают максимальную производительность и энергоэффективность.
В случае с RNN это становится особенно ценным. Рекуррентные сети требуют последовательной обработки данных с сохранением контекста, что идеально соответствует возможностям FPGA. Чипы могут быть настроены таким образом, чтобы каждое состояние сети соответствовало определённой части аппаратной реализации.
К примеру, современные FPGA содержат миллионы программируемых логических элементов, тысячи DSP-блоков для обработки сигналов и огромное количество блоков памяти различных типов. Все эти компоненты могут быть сконфигурированы под конкретные требования задачи.
Стоит отметить, что разработка для FPGA имеет свои особенности. Вместо написания программного кода разработчик создаёт описания аппаратной логики, которые затем преобразуются в реальные электронные цепи на кристалле. Этот процесс называется синтезом и является ключевым этапом разработки.
Пояснения:
Логические элементы (LE): Основные строительные блоки FPGA, определяющие вычислительную мощность.
Встроенная память (Block RAM): Используется для хранения данных и промежуточных результатов.
DSP-блоки: Специализированные блоки для выполнения операций цифровой обработки сигналов.
Частота работы: Максимальная тактовая частота, на которой может работать чип.
Энергопотребление: Важный параметр для энергоэффективных решений.
Технологический процесс: Определяет плотность транзисторов и энергоэффективность.
Интерфейсы: Поддержка современных интерфейсов для интеграции с другими компонентами системы.
Цена: Приблизительная стоимость чипа, которая может варьироваться в зависимости от поставщика и объема заказа.
FPGA представляют собой мощный инструмент для специализированных вычислений, который открывает новые возможности для развития искусственного интеллекта. Их способность к настройке под конкретные задачи делает их особенно привлекательными для работы с рекуррентными нейронными сетями.
После того как мы познакомились с базовыми принципами работы FPGA, давайте теперь рассмотрим, как эти чипы меняют подход к работе с рекуррентными нейронными сетями.
Рекуррентные нейронные сети имеют особую "память", которая позволяет им запоминать предыдущие входные данные и использовать их при обработке новых. Это похоже на чтение книги – каждое новое предложение имеет смысл только в контексте предыдущих. FPGA позволяют создавать уникальную архитектуру именно для этих потребностей.
Процесс начинается с преобразования рекуррентных связей в пространственные структуры. Это похоже на разворачивание времени в физическое пространство, где каждая точка представляет собой момент времени. Такой подход позволяет одновременно обрабатывать несколько шагов, значительно ускоряя вычисления.
Особенно интересна работа с LSTM (Long Short-Term Memory) ячейками, которые являются одним из самых распространённых типов RNN. Каждая LSTM ячейка содержит несколько вентилей (gates), каждый из которых выполняет свою функцию: забывание старых данных, добавление новых или регулирование выхода. FPGA позволяют реализовать каждый из этих механизмов аппаратно, что даёт значительное преимущество в производительности.
Современные FPGA оснащены специализированными блоками для обработки сигналов (DSP), которые идеально подходят для выполнения математических операций, необходимых для работы RNN. Например, умножение матриц и векторов, активационные функции и нормализация могут быть реализованы аппаратно с максимальной эффективностью.
Теперь представьте, что вы строите водопроводную систему. Каждый участок трубопровода должен быть правильно размерен и соединён, чтобы вода текла беспрепятственно. Аналогично, при проектировании FPGA для RNN необходимо точно рассчитать, как данные будут перемещаться между различными блоками обработки.
Эта способность кастомизации делает FPGA особенно привлекательными для компаний, которые хотят получить максимальную производительность при минимальном энергопотреблении. Хотя процесс разработки может показаться сложным, современные инструменты значительно упрощают его.
Производительность RNN (например, скорость обработки данных или точность) зависит от таких параметров, как количество слоев, количество нейронов в слое и размер пакета (batch size).
FPGA предоставляют уникальные возможности для оптимизации работы рекуррентных нейронных сетей, позволяя создавать аппаратные реализации сложных алгоритмов. В следующей части мы рассмотрим практические аспекты разработки таких решений и столкнемся с реальными вызовами этого процесса.