Всем привет! Пора писать следующий урок для SEO-курса по инфосайтам под пассивный доход. Напомню, сейчас я делаю сетку инфосайтов (веб-сервисов) под заработок на рекламе. Суть такая: создаем полезный сайт, растим поисковый трафик из Яндекса и Гугла и ставим рекламу. В итоге получаем доход с сайтов (с просмотров рекламы), даже когда спим.
В прошлых уроках мы подобрали и зарегистрировали домен, установили движок и сделали базовую настройку сайта. Теперь пора собрать семантическое ядро сайта под будущие страницы. Это крайне важный этап, напрямую влияющий на количество трафика (посетителей).
Что такое семантическое ядро и зачем оно нужно
Семантическое ядро (СЯ) – это набор ключевых фраз, которые вписываются в тексты, заголовки, мета-теги и другие элементы сайта.
Ключевая фраза – это слово или словосочетание, которое человек вбивает в поисковике для поиска нужной информации.
Например, человек хочет построить печь своими руками. Он заходит в Яндекс, ищет информацию по запросу (ключевой фразе) «Как сложить печь из кирпича своими руками». Яндекс выдает человеку страницы, соответствующие его запросу.
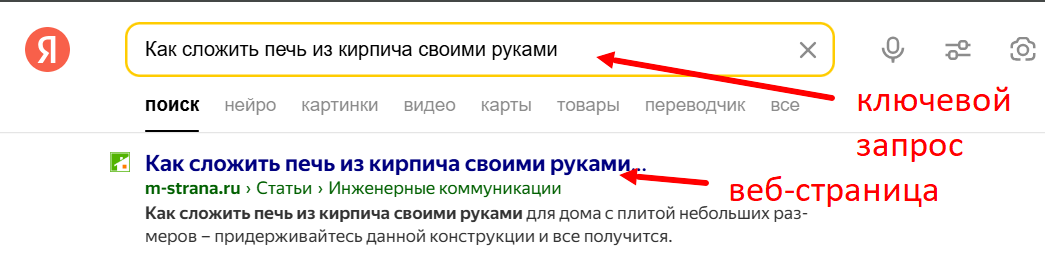
На таких страницах встречается ключевая фраза «Как сложить печь из кирпича своими руками», есть текст с подробной информацией, картинки, видео и т.д. Если в тексте нет такого ключа или синонимов, то человеку страница показываться не будет. Алгоритмы поисковых систем работают так, чтобы, например, не показывались сайты про аквариумы по запросу о печах.
Вот почему важно собрать ключевые запросы и оптимизировать под них продвигаемые веб-страницы. Нет семантического ядра – нет трафика, либо его крайне мало.
Как составить семантическое ядро
В этой статье я расскажу, как собираю семантическое ядро для инфосайтов и не только. В этом уроке мы рассмотрим сбор СЯ для многостраничного сайта. Данный алгоритм подойдёт и для коммерческих проектов. А в следующем уроке я расскажу и покажу, как собираю семантику для веб-сервисов. Поехали!
Определение маркеров
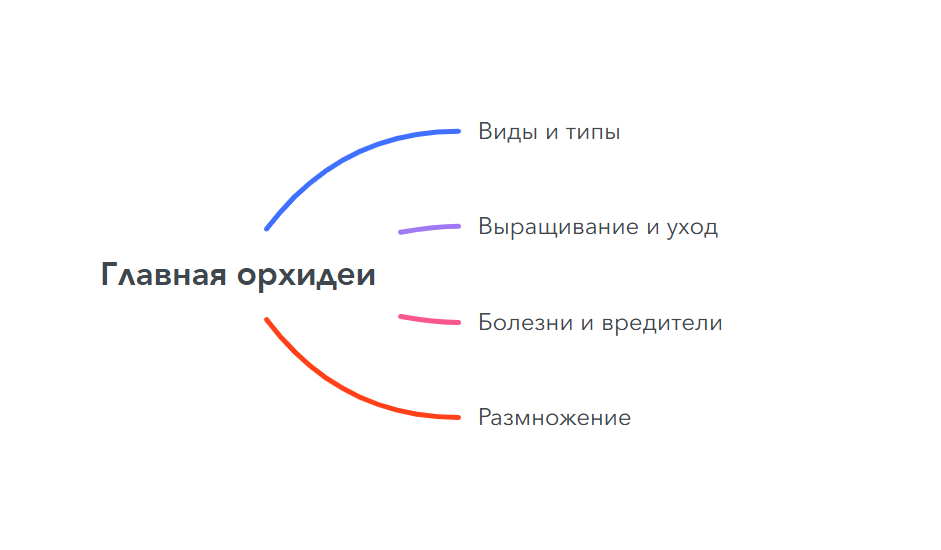
Подбираем маркерные слова, на основе которых будем собирать СЯ. Рассмотрим на примере тему – Орхидеи. Это мои любимые цветы.
1. Мозговой штурм
Я составила такой первоначальный список маркеров:
- Виды орхидей
- Выращивание и уход
- Заболевания орхидей и вредители
- Размножение орхидей
Эти маркеры я брала из головы, что бы я хотела видеть на своём сайте. На коммерческих сайтах отталкивайтесь от ассортимента категорий, товаров и услуг.
Переношу то, что у меня получилось в онлайн-майндкарту, чтобы составить понятную для меня структуру сайта. Я использую Mindmeister. Вы можете взять любой сервис майндкарт, таблицу в Excel или даже составить такую карту просто на листе бумаги от руки.
2. Анализ конкурентов
Затем мне нужно значительно расширить структуру сайта, собрать темы статей. Для этого я анализирую конкурентов. У меня инфосайт, значит я анализирую именно инфосайты. Если бы у меня был интернет-магазин орхидей, то я изучала бы интернет-магазины.
Для анализа ищу подходящие сайты в Яндексе. Вбиваю какой-нибудь запрос, например: «уход за орхидеями», «блог про орхидеи», «сайт про орхидеи» и т.д.
Кроме маркеров рекомендую изучить как вебмастеры оформляют свои сайты. Чтобы понимать, каким бы вы хотели видеть свой сайт в будущем. Смотрите конкурентов и с ноутбука, и со смартфона, чтобы понимать, как должен выглядеть удобный сайт.
Для быстрого анализа ключевых слов сайтов-конкурентов используйте https://pr-cy.ru/website-keywords/ (нужна регистрация, это бесплатно). На странице сервиса укажите сайт конкурента и нажмите «Проверить».
Листайте результаты проверки до пункта Запросы. В столбике Ключевое слово вы увидите, какие ключевые слова есть на сайте вашего конкурента. Это поможет составить структуру вашего сайта и определить темы статей.
Так изучаю около 10-15 сайтов: смотрю навигационное меню, подменю, рубрики, статьи. И дополняю майндкарту со структурой:
3. Поиск в Wordstat.yandex.ru
Чтобы отточить структуру нашего сайта идём в wordstat.yandex.ru. Вбиваем основное слово, тему сайта, в моём случае это – орхидеи. И внимательно изучаем, что ищут пользователи в Яндексе. В результате анализа вы увидите закономерность, что некоторые ключи можно объединить в группы (кластеры).
Если встречается такая закономерность, то это можно считать маркером. Этот маркер можно отнести к новой рубрике или теме статьи. Дополняем таким образом структуру сайта.
Позже по ходу сбора семантики могут еще всплыть маркеры, какие-то интересные темы. Сейчас нам нужно определиться с основными маркерами инфосайта и создать первоначальный пул тем статей.
Поизучать вблизи майндкарту можно тут: https://mm.tt/app/map/3602201433?t=HpVUeiGpMb
Подготовка к сбору СЯ
Мы выполнили первую часть урока – собрали маркеры и темы статей проекта. Структура может сначала получиться на 10-30 страниц. По мере роста проекта вы можете её обновлять и расширять, подбирая что-то новенькое через анализ конкурентов и wordstat.yandex.ru.
Теперь нужно собрать семантическое ядро, те ключевые слова, которые будем вписывать на страницы веб-сайта.
Есть много сервисов для сбора семантического ядра. Сразу скажу, что все эти сервисы платные. Самый доступный Word Keeper, 590 руб. в месяц. После регистрации начисляют бонус – 250 лимитов. Им и будем пользоваться.
Раньше я работала в программе Key Kollector. Разовая оплата 2200 руб. с пожизненным доступом. Но программа перестала нормально работать, пришлось от неё отказаться и искать что-то другое.
Как собрать ключевые слова в Word Keeper
1. Зарегистрируйтесь в Word Keeper. Вам придёт письмо с данными для входа, нужно будет в этом письме перейти по ссылке, чтобы подтвердить регистрацию.
2. После этого перейдите на страницу https://word-keeper.ru/dashboard и выберите Парсинг фраз из Яндекс Wordstat (левая колонка).
3. Создайте новый проект. Я назвала свой проект «Орхидеи». Впишите несколько маркеров из структуры вашего сайта. Я вписала: виды орхидей, сорта орхидей, покупка орхидеи, пересадка орхидеи, пересадить орхидею. Заполните настройки проекта, как на скриншоте. Нажмите «Создать задание».
Посмотреть скриншот поближе >>
4. Затем перейдите на страницу Мои проекты https://word-keeper.ru/core. Тут вы увидите свой проект и статус готовности задачи по сбору фраз. Перейдите в проект. Вы увидите таблицу с собранными ключевыми фразами с базовой частотностью (столбец W).
Просмотрите собранные данные и удалите мусорные ключевые фразы. У меня получился такой мусор: олег видов дикая орхидея, видов в дикой орхидее, орхидея парфюмерная фабрика, вид орхидеи 5 букв и т.д. Это не подходит дня сайта про орхидеи. Поэтому выделяю оранжевым ненужные фразы (щёлк левой кнопкой) и нажимаю на мусорное ведро:
Лайфхак. Вы увидели мусорное слово, например, олег видов дикая орхидея, как у меня. Укажите в быстром поиске часть мусорной фразы, чтобы найти похожие слова. Я указала олег и программа мне выдала эти ненужные фразы, я их удалила:
Будьте внимательны! Во время чистки ключевых фраз вам могут попадаться новые маркеры для последующего сбора слов. Например, я узнала, что люди ищут не только сорта орхидей, но и группы по цветам и признакам, например «ароматные орхидеи». Всё это вы можете переносить в структуру, чтобы не потерять, использовать для последующего сбора ключей.
5. После чистки ключевых слов от мусора соберите точную "!" частотность ключевых слов, это важно. На данный момент у нас собрана только базовая в столбце W. Точная частотность будет в колонке "!W". Для сбора точной частотности нажмите кнопку «Парсинг», затем Частотности за месяц и укажите настройки, поставьте галочку рядом с "!W". Нажмите «Создать задание».
Получается такой результат. Появилась колонка с точной частотностью "!W": Нажмите на название колонки "!W", чтобы данные отсортировались по убыванию.
Очень важный нюанс! Не берём в СЯ ключевые слова с 0 точной частотностью "!W". Именно для этого мы её собирали, чтобы отсортировать пустышки и оставить только те фразы, которые будут приносить трафик.
6. Итак, мы получили почищенные и отсортированные по точной частотности ключевые слова.
Теперь выгрузите из Word Keeper собранные данные. Для этого нажмите на Выгрузка и выберите CSV (win), если у вас Виндовс. Если MacOS, то выберите для выгрузки CSV (mac):
Должна выгрузиться такая таблица в Excel. Удаляем столбцы C и D, они нам не нужны:
Выделите в файле первую строку, затем нажмите на панели Сортировка и фильтр, затем выберите Фильтр:
Пока это просто данные. Теперь нужно создать отдельную таблицу с семантическим ядром проекта и перенести туда полученные фразы по группам (кластерам). 1 кластер одна страница.
Шаблон файла семантического ядра вы можете скачать по ссылке: https://docs.google.com/spreadsheets/d/1jwpCzdf8aEDOGYQILc89nIyGTQEsNH7HMPTdEtVA0T8/edit?usp=sharing
Вспомните маркеры, по которым собирали ключевые слова в Word Keeper. Перейдите в выгруженный файл из Word Keeper и с помощью созданного ранее фильтра Excel найдите нужные фразы. Например, у меня были маркеры «вид орхидей» и «сорта орхидей». Ищу их в столбце B «Фраза»:
В итоге после фильтрации в столбце «Фраза» у меня отображается пул нужных мне ключевых слов:
Выделяю и копирую эти слова с частотностями в общий файл семантического ядра в кластер «Виды и сорта орхидей». Это будет рубрика. С остальными маркерами поступаю точно так же.
В итоге в файле семантического ядра должно получится несколько кластеров с отобранными ключевыми фразами. Кластер вы можете назвать так, как вы пожелаете, чтобы вам было понятно, о чём эта страница.
Внимание! Главное правило распределения ключевых слов по страницам – на одну страницу уникальные ключевые слова! Не пихайте везде всё подряд, так неправильно. Если страница про мошек в орхидеях, то и такие ключи должны быть, не другие. Статья должна нести конкретный смысл с конкретными ключевыми запросами.
Мой файл с семантическим ядром под орхидеи https://docs.google.com/spreadsheets/d/19kR3FMKekGM--OUVnEVDS8fWuOItndHjJ3l49jlpcRc/edit?gid=0#gid=0
Так вы пополняете файл семантического ядра из файла выгрузки Word Keeper, пока не кончатся ключевые фразы и маркеры. Для начала попробуйте поработать с одним маркером, чтобы не путаться в большом объёме данных.
Затем берём новые маркеры, например: болезни орхидей, вредители орхидей, насекомые в орхидеи, мошки в орхидее и т.д. Для сбора новых ключевых фраз не надо создавать новый проект.
1. Для этого откройте текущий проект в Word Keeper, у меня всё те же «Орхидеи».
2. Нажмите на кнопку «Выделить все найденные фразы». После этого все ключевые слова выделятся оранжевым. Затем нажмите на мусорное ведро, чтобы их удалить. Эти слова нам больше не нужны, ведь мы отобрали нужные нам фразы и сгруппировали в файле семантического ядра.
3. Теперь проект пустой и его можно пополнить ключевыми фразами по новым маркерам. Для этого нажмите Парсинг, затем Сбор фраз из Wordstat (левая колонка). После этого заполните форму сбора данных так же, как и в самом начале работы с Word Keeper. То есть начинаем всё по кругу. И так до самого конца, пока не выпишите всевозможные статьи на своём проекте.
Да, это очень нудная работа, но важная, если вы хотите, чтобы ваш веб-проект рос.
Дополнительные слова
И это не всё! Рекомендую использовать дополнительные слова (LSI-фразы), чтобы собрать как можно больше трафика с поисковых систем на страницах своего веб-проекта.
Для поиска таких слов используем бесплатный сервис https://artur2k.ru/tools/poisk-lsi/, регистрация не нужна.
1. Перейдите на https://artur2k.ru/tools/poisk-lsi/
2. Введите список поисковых запросов для поиска LSI фраз. То есть тут указываем наши маркеры или темы статей. Например, виды орхидей с фото и названиями.
Давайте посмотрим, какими словами мы можем дополнить этот кластер. Нажмите «Найти n-граммы».
3. Получаем такой результат. Данные можно скачать в формате таблицы Excel.
4. Из столбца Фразы LSI я беру те, которые не пересекаются с уже отобранными ключевыми словами. И дополняю ими таблицу семантического ядра, вписываю LSI напротив нужного кластера в столбец Дополнительные слова.
Готово! Мы собрали ключевые фразы в Word Keeper, почистили их, отсортировали и перенесли в файл семантического ядра по группам (страницам), дополнили кластеры LSI-словами. Ну вот, положено начало семантического ядра вашего проекта.
Если вы не хотите париться со сбором СЯ и тратить на это деньги
В этом случае всё просто. Собираете структуру сайта, как описано в первой части урока. И под каждую рубрику и страницу смотрите ключевые слова вручную в https://wordstat.yandex.ru/. Вот как это можно сделать на примере орхидей.
1. Перейдите в https://wordstat.yandex.ru/
2. Введите нужный маркер/ключевое слово. Обратите внимание, что должна быть выбрана вкладка Топы запросов:
3. Проанализируйте полученные ключевые фразы и выберете те, которые наиболее подходят для конкретной страницы вашего сайта. Рекомендую брать от 5 ключевых слов под одну страницу и более.
Но в этом случае нет гарантии, что вы отобрали трафиковые запросы и их будет достаточно для продвижения сайта. Но лучше так, чем ничего.
Уф, урок получился прям насыщенным, я готовила его несколько дней. Если вам что-то не ясно, что-то не получается, то задавайте вопросы в комментариях, либо в моём ТГ-канале.