Самый унылый этап разработки – когда игра, собственно, уже работает, но нужно её дооформить до нормального вида. В этом месте всё начинает буксовать, потому что в игру ты уже успел наиграться во время тестирования, основная работа уже проделана, а неосновную делать лень, и кроме того она ещё и может оказаться довольно тяжёлой и нудной.
Предыдущая часть:
Игра загружала из двух отдельных файлов сборник карт и сборник картинок, а с внедрением GUI появились дополнительно иконки (те же картинки, только в другом формате) и шрифты. И всё это опять надо грузить, но иметь четыре разных источника данных это уже перебор.
В итоге сделан менеджер ресурсов, который загружает один большой файл, в котором находятся данные всех типов. Он грузит его целиком в память, потому что все эти данные нужны, а их размер не критичен. Далее он настраивает внутренние указатели на эти данные, так что игре остаётся только запрашивать у менеджера ресурсов: дай мне указатель на карту номер 1, на картинку номер 2 и т.д.
Однако проблема оказалась в другом, а именно как собрать этот общий ресурсный файл из набора исходных файлов.
Структура ресурсного файла проста:
- Тэг, количество, данные
- Тэг, количество, данные
- ...
Где тэг это 16-битное представление типа данных (карты, картинки и т.д.)
Пришлось писать отдельную утилиту для командной строки, где с помощью ключей-параметров указывались каталоги, из которых надо собирать файлы, и т.п.
Я первоначально хотел расписать эту утилиту здесь, но это быстро надоело, там всё крайне нудно.
Но есть один момент, который хочется осветить. Я предусмотрел такой случай, когда картинки, скажем, находятся в разных каталогах, и я могу составить такую командную строку для утилиты, которую я назвал respack:
respack IMG:folder1 MAP:folder2 IMG:folder3
Это значит, что в ресурсный файл должны добавиться картинки (с тэгом IMG) из папок folder1 и folder3, а также карты (с тэгом MAP) из папки folder2.
Но как видим, тэги картинок указаны вперемешку с тэгами карт, поэтому утилита должна сначала собрать информацию из всех тэгов IMG, объединить её, и только затем добавить в ресурсный файл.
Для этого мне понадобилось хранилище строк, где я мог бы накапливать найденные имена файлов при сканировании папок.
В любом языке со сборщиком мусора это не вызвало бы проблем. Просто сделать динамический массив и добавлять в него записи, сколько нужно.
Но так как я писал на C, пришлось задуматься о выделении памяти. Обычно я решаю эти задачи выделением сразу достаточного количества памяти на всё. Например, я предполагаю накопить до 1024 строк с длиной до 1024 байт каждая, тогда можно просто выделить 1 мегабайт памяти и не думать больше ни о чём. И ведь 1 мегабайт это по нынешним временам совсем немного, не так ли?
Но тут мне стало как-то обидно что ли, ведь такой способ, хоть и весьма прост, скрывает некий страх работы с памятью.
По-хорошему, любая строка должна выделять индивидуальную память под себя, что и происходит в других языках, но это мне не нравится уже с другой стороны – слишком много мелких выделений памяти, и всю эту память потом надо освободить.
Я решил сделать компромиссный вариант, написав свой микроменеджер памяти для хранения строк. Не то чтобы это было нужно, но почему нет.
Как он работает
У него есть массив выделенных блоков памяти. Каждый блок размером 1 мегабайт. Строки пишутся в текущий блок, пока в нём хватает места. Как только строка не помещается, выделяется новый блок и она пишется туда.
Таким образом, я могу гранулировать выделенную под строки память в пределах плюс-минус один мегабайт, хотя конечно можно задать другую константу.
Важно, что для моей задачи строки только добавляются, но не удаляются из хранилища, поэтому не нужно заморачиваться свободными блоками, сегментацией и прочими побочными эффектами.
Так выглядит структура StringStorage:

В ней хранится количество записей (entry_cnt), количество выделенных сегментов (seg_cnt), позиция записи внутри текущего сегмента (seg_pos), массив записей (entries) и массив сегментов (segments).
Инициализация структуры:
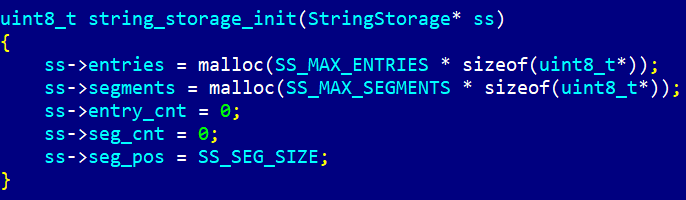
Выделяется память под массив записей и массив сегментов фиксированной длины, достаточной для хранения необходимого количества записей.
#define SS_MAX_ENTRIES 65536
#define SS_MAX_SEGMENTS 1024
#define SS_SEG_SIZE (1024 * 1024)
После инициализации ещё не выделено памяти ни под один сегмент. Но позиция записи внутри "текущего" несуществующего сегмента уже задана такой, чтобы превышать его размер:
ss->seg_pos = SS_SEG_SIZE;
При добавлении первой записи:
проверяется, поместится ли строка в текущий сегмент, и так как она сейчас не помещается, то выделяется новый (в данном случае самый первый) сегмент памяти, указатель на который помещается в массив сегментов.
После чего уже в этот сегмент копируется добавляемая строка, и адрес строки в сегменте записывается в массив записей, а текущая позиция в сегменте увеличивается на длину строки.
Получение записи из хранилища по индексу:
И наконец, централизованная очистка хранилища, где ничего не забудется:
Как пример практического использования, фрагмент сканирования папки и добавления всех найденных имён файлов в хранилище:
В принципе я мог бы написать и про разбор командной строки, и про сканирование папок более подробно, но не знаю, будет ли это кому-то полезно.
Подводные камни
Легко заметить, что размер сегмента в данном случае равен 1 мегабайту, и если каждая строка к примеру занимает 600 килобайт, то память будет расходоваться крайне неоптимально. В один сегмент будет помещаться только одна строка, а почти половина места будет пропадать зря.
Более того, если попадётся строка длиннее чем 1 мегабайт, то она вообще не влезет в сегмент, что приведёт к катастрофе.
Конечно, все эти нюансы можно учесть, добавив дополнительные проверки и сделав даже динамически вычисляемый размер каждого сегмента. Но у меня строки это исключительно имена файлов, которые вряд ли превысят длину даже в 256 байт. Поэтому тут я спокоен.