В предыдущей части мы рассмотрели основные типы функций активации и их роль в нейронных сетях. Теперь мы перейдем к анализу того, как выбор функции активации влияет на производительность модели, включая скорость обучения, точность и требования к аппаратным ресурсам.
3. Влияние функций активации на производительность модели
3.1 Скорость обучения
Скорость обучения модели напрямую зависит от выбора функции активации. Некоторые функции, такие как ReLU, ускоряют обучение, в то время как другие, например сигмоида, могут замедлять его из-за проблем, связанных с градиентами.
- ReLU: Благодаря своей простоте и отсутствию проблемы "исчезающего градиента" для положительных значений, ReLU значительно ускоряет обучение глубоких сетей.
- Сигмоида и tanh: Эти функции склонны к проблеме "исчезающего градиента", что замедляет обучение, особенно в глубоких сетях. Градиенты на начальных слоях становятся настолько малыми, что веса почти не обновляются.
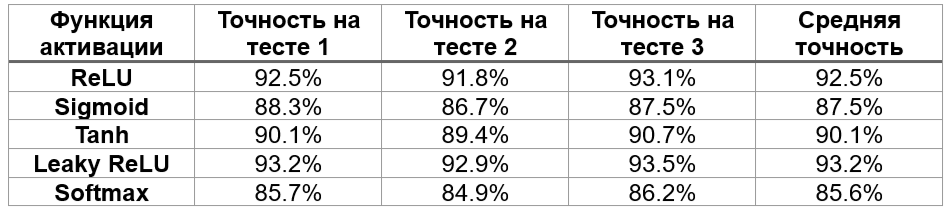
3.2 Точность модели
Точность модели также зависит от выбора функции активации. Например:
- ReLU: Обычно обеспечивает высокую точность в глубоких сетях, но может страдать от проблемы "умирающего ReLU".
- Leaky ReLU и ELU: Эти модификации ReLU могут улучшить точность, особенно в задачах, где ReLU "умирает".
- Сигмоида и tanh: Могут быть полезны в специфических задачах, таких как классификация с двумя классами, но в глубоких сетях их точность часто ниже.
3.3 Проблемы, связанные с функциями активации
- Исчезающий градиент: Возникает, когда градиенты на начальных слоях становятся слишком малыми, что делает обучение невозможным. Сигмоида и tanh особенно подвержены этой проблеме.
- Умирающий ReLU: Нейроны могут "застревать" в нулевых значениях и переставать обучаться. Это происходит, когда большая часть входных данных для ReLU отрицательна.
4. Аппаратные ресурсы и функции активации
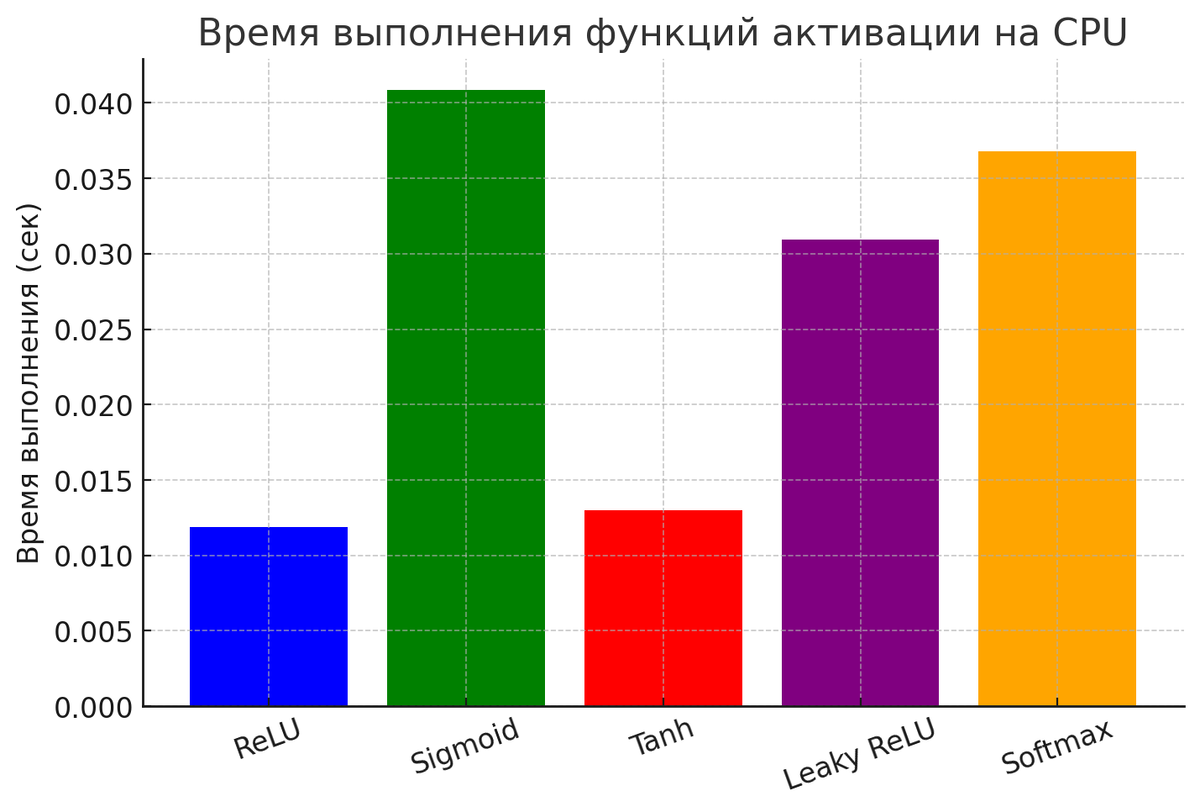
4.1 Влияние функций активации на CPU
На процессорах (CPU) вычисления функций активации, таких как сигмоида или tanh, могут быть более затратными из-за необходимости вычисления экспоненты. В таких случаях ReLU может быть более предпочтительным, так как он требует только простых операций сравнения и сложения.
Пример:
- ReLU: f(x)=max(0,x)f(x)=max(0,x) — одна операция сравнения.
- Сигмоида: f(x)=11+e−xf(x)=1+e−x1 — вычисление экспоненты и деление.
4.2 Влияние функций активации на GPU
На графических процессорах (GPU) вычисления функций активации могут быть значительно ускорены благодаря параллельной архитектуре. Однако даже на GPU функции, требующие сложных вычислений (например, экспоненты), могут быть более затратными по сравнению с ReLU.
Пример:
- На GPU ReLU выполняется быстрее, чем сигмоида, из-за отсутствия сложных математических операций.
4.3 Распределенные вычисления и серверы
В распределенных системах, где данные обрабатываются на нескольких серверах, выбор функции активации может повлиять на скорость передачи данных между узлами. Функции, требующие меньше вычислений, могут снизить нагрузку на сеть и ускорить процесс обучения.
Пример:
- Использование ReLU вместо сигмоиды может снизить объем данных, передаваемых между серверами, что особенно важно для больших моделей.
В этой части мы рассмотрели, как выбор функции активации влияет на производительность модели, включая скорость обучения, точность и требования к аппаратным ресурсам. Мы также обсудили проблемы, связанные с функциями активации, такие как "исчезающий градиент" и "умирающий ReLU". В следующей части мы перейдем к практическим рекомендациям по выбору функций активации и рассмотрим примеры их использования в реальных задачах.