В предыдущих частях мы рассмотрели основы функций активации, их влияние на производительность модели и связь с аппаратными ресурсами. Теперь мы перейдем к практическим аспектам: как выбрать функцию активации для конкретной задачи, как использовать их в реальных проектах и какие тенденции ожидаются в будущем.
5. Практические рекомендации по выбору функций активации
5.1 Для глубоких нейронных сетей
В глубоких нейронных сетях рекомендуется использовать ReLU или его модификации (Leaky ReLU, ELU), так как они позволяют избежать проблемы "исчезающего градиента" и ускоряют обучение.
Пример:
- В сверточных нейронных сетях (CNN) для обработки изображений ReLU является стандартным выбором.
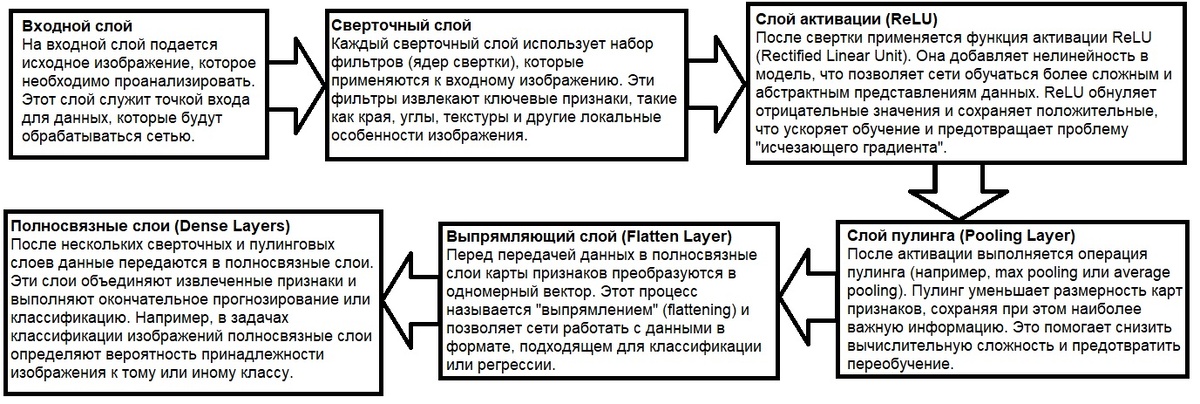
5.2 Для задач классификации
Для задач классификации в выходном слое рекомендуется использовать функцию Softmax, так как она преобразует выходные значения в вероятности, что удобно для интерпретации результатов.
Пример:
- В задачах классификации изображений (например, распознавание рукописных цифр) Softmax используется в выходном слое для определения вероятности принадлежности к каждому классу.
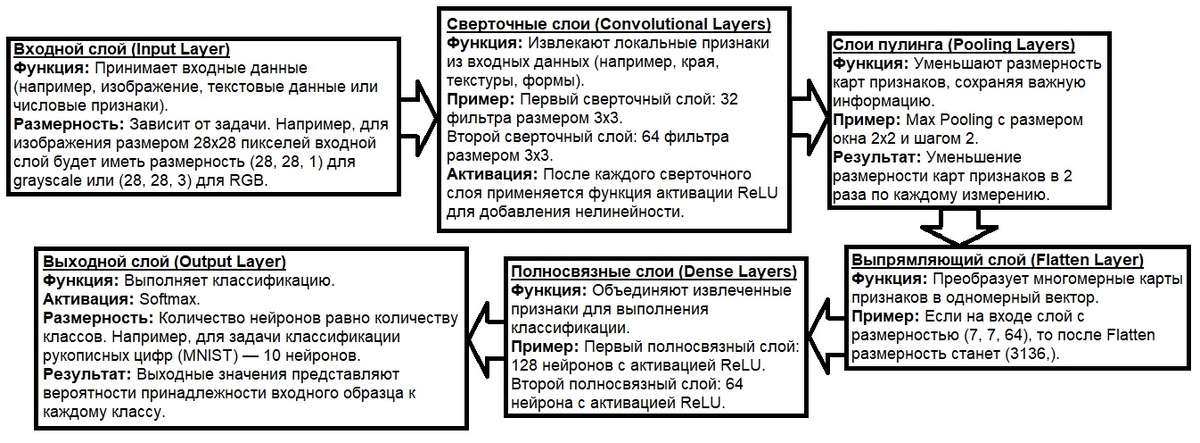
5.3 Для задач регрессии
Для задач регрессии в выходном слое можно использовать линейную функцию активации, так как она не ограничивает диапазон выходных значений.
Пример:
1. Описание задачи
Модель регрессии используется для предсказания непрерывных значений. В данном случае линейная функция активации в выходном слое позволяет модели выдавать предсказания в виде непрерывной линии.
2. Данные
Входные данные: Независимая переменная (например, площадь дома).
Целевые данные: Зависимая переменная (например, цена дома).
Пример данных:
Вход: [50, 100, 150, 200, 250] (площадь в м²).
Целевые значения: [100, 200, 300, 400, 500] (цена в тыс. долларов).
3. Модель
Архитектура:
Входной слой: 1 нейрон (площадь дома).
Скрытый слой: 10 нейронов с активацией ReLU.
Выходной слой: 1 нейрон с линейной функцией активации (предсказание цены).
Обучение: Модель обучена на данных, минимизируя среднеквадратичную ошибку (MSE).
4. График
Ось X: Независимая переменная (площадь дома).
Ось Y: Зависимая переменная (цена дома).
Элементы графика:
Исходные данные: Точки, представляющие реальные значения (например, синие точки).
Предсказания модели: Линия, показывающая предсказания модели (например, красная линия).
5. Пример графика
Исходные данные:
Точки: (50, 100), (100, 200), (150, 300), (200, 400), (250, 500).
Предсказания модели:
Линия, проходящая через точки: (50, 110), (100, 210), (150, 310), (200, 410), (250, 510).
6. Интерпретация
График показывает, насколько хорошо модель предсказывает значения.
Линия предсказаний должна быть как можно ближе к реальным точкам.
Если линия сильно отклоняется от точек, это может указывать на недообучение или переобучение модели.
5.4 Учет аппаратных ресурсов
При выборе функции активации следует учитывать доступные аппаратные ресурсы. Например, если вы работаете на слабом оборудовании, возможно, стоит избегать функций, требующих сложных вычислений (например, экспоненты).
Пример:
- На устройствах с ограниченными ресурсами (например, мобильные телефоны) предпочтение отдается ReLU из-за его простоты.
6. Примеры использования функций активации в реальных задачах
6.1 Пример 1: Классификация изображений с использованием ReLU
Задача: Распознавание рукописных цифр (MNIST).
Архитектура: Сверточная нейронная сеть (CNN).
Функция активации: ReLU в скрытых слоях, Softmax в выходном слое.
Что делает этот код?
Загрузка данных MNIST:
Данные загружаются и нормализуются (значения пикселей приводятся к диапазону [0, 1]).
Метки преобразуются в one-hot encoding.
Создание архитектуры CNN:
Три сверточных слоя с ReLU.
Два слоя Max Pooling.
Полносвязный слой с ReLU.
Выходной слой с Softmax для классификации.
Обучение модели:
Модель компилируется с оптимизатором Adam и функцией потерь categorical_crossentropy.
Обучение выполняется в течение 10 эпох с размером пакета (batch size) 128.
Оценка модели:
Модель оценивается на тестовых данных, и выводится точность.
Визуализация архитектуры:
Используется библиотека visualkeras для графического представления архитектуры.
Построение графиков:
График точности (accuracy) на обучении и валидации.
График потерь (loss) на обучении и валидации.
Результат:
1. Точность модели
На тестовых данных модель достигла точности 99.11%. Это свидетельствует о том, что модель успешно справляется с задачей классификации изображений рукописных цифр (MNIST).
Высокая точность на тестовых данных подтверждает, что модель хорошо обобщает и не переобучается на тренировочных данных.
2. График точности
Точность на обучении: Кривая точности на обучении быстро растет и достигает значения, близкого к 1.0 (100%), уже к 5-й эпохе. Это говорит о том, что модель эффективно обучается на тренировочных данных.
Точность на валидации (Validation Accuracy): Кривая точности на валидации также растет. Уже ко 2-й эпохе она достигает значения около 99%. Это указывает на хорошую обобщающую способность модели.
Разрыв между точностью на обучении и валидации: Небольшой разрыв между кривыми (около 1%) свидетельствует о том, что модель не переобучается.
3. График потерь
Потери на обучении (Training Loss): Кривая потерь на обучении быстро уменьшается и стабилизируется на низком уровне (около 0.02) к 5-й эпохе. Это подтверждает, что модель успешно минимизирует ошибку на тренировочных данных.
Потери на валидации (Validation Loss): Кривая потерь на валидации также уменьшается, но стабилизируется на чуть более высоком уровне (около 0.05). Это нормально, так как валидационные данные модель видит только во время оценки.
Разрыв между потерями на обучении и валидации: Небольшой разрыв между кривыми (около 0.03) подтверждает, что модель не переобучается.
4. Общие выводы
Модель демонстрирует высокую точность как на тренировочных, так и на тестовых данных, что подтверждает её эффективность для задачи классификации изображений MNIST.
Отсутствие значительного разрыва между точностью и потерями на обучении и валидации указывает на то, что модель не переобучается.
Архитектура CNN с использованием ReLU в скрытых слоях и Softmax в выходном слое хорошо подходит для данной задачи.
Для дальнейшего улучшения модели можно:
Увеличить количество эпох обучения, чтобы проверить, не начнет ли модель переобучаться.
Добавить регуляризацию (например, Dropout), чтобы повысить устойчивость модели к переобучению.
Использовать аугментацию данных (например, повороты, сдвиги изображений), чтобы увеличить разнообразие тренировочных данных.
Попробовать более сложные архитектуры (например, ResNet или EfficientNet), если точность на более сложных данных окажется недостаточной.
6.2 Пример 2: Обработка естественного языка с использованием Softmax
Задача: Классификация текстовых данных (например, определение тональности отзывов).
Архитектура: Рекуррентная нейронная сеть (RNN) или трансформер.
Функция активации: Softmax в выходном слое.
Что делает этот код?
Загрузка и предобработка данных:
Текстовые данные токенизируются и преобразуются в последовательности чисел.
Последовательности дополняются до одинаковой длины.
Метки преобразуются в one-hot encoding.
Создание архитектуры RNN:
Слой Embedding для преобразования слов в векторы.
Слой LSTM для обработки последовательностей.
Полносвязный слой с ReLU.
Выходной слой с Softmax для классификации.
Обучение модели:
Модель компилируется с оптимизатором Adam и функцией потерь categorical_crossentropy.
Обучение выполняется в течение 20 эпох с размером пакета (batch size) 2.
Оценка модели:
Модель оценивается на тестовых данных, и выводится точность.
Построение графиков:
График точности (accuracy) на обучении и валидации.
График потерь (loss) на обучении и валидации.
Результат:
1. Точность на обучении растет, а на валидации остается низкой.
2. Потери на обучении продолжают уменьшаться, а на валидации начинают расти.
Всё это явный признак - это признак переобучения.
Вывод: Модель переобучается на тренировочных данных и плохо обобщает.
Общие рекомендации
- Если модель переобучается:
Увеличьте количество данных (например, с помощью аугментации).
Добавьте регуляризацию (например, Dropout или L2-регуляризацию).
Уменьшите сложность модели (например, уменьшите количество слоев или нейронов). - Если модель недообучается:
Увеличьте сложность модели (например, добавьте больше слоев или нейронов).
Улучшите качество данных (например, очистите данные или добавьте новые признаки).
Увеличьте количество эпох обучения. - Если модель работает хорошо:
Проверьте модель на тестовых данных, чтобы убедиться в её обобщающей способности.
Сохраните модель для дальнейшего использования.
7. Будущие тенденции в разработке функций активации
Новые функции активации
В последние годы появились новые функции активации, такие как Swish и GELU, которые показывают promising результаты в глубоких нейронных сетях.
- Swish: f(x)=x⋅σ(x), где σ(x) — сигмоидальная функция.
- GELU (Gaussian Error Linear Unit): f(x)=x⋅Φ(x), где Φ(x) — функция распределения стандартной нормальной величины.
Адаптивные функции активации
Адаптивные функции активации, такие как PReLU (Parametric ReLU), позволяют модели обучать параметры функции активации в процессе обучения. Это может улучшить производительность модели, особенно в сложных задачах.
Влияние квантовых вычислений
С развитием квантовых вычислений могут появиться новые подходы к функциям активации, которые будут учитывать особенности квантовых алгоритмов.
В этой части мы рассмотрели практические рекомендации по выбору функций активации, примеры их использования в реальных задачах и будущие тенденции в этой области. Выбор функции активации — это важный шаг в проектировании нейронных сетей, который может существенно повлиять на производительность модели.