
Большие языковые модели (LLM) стремительно захватывают мир технологий, помогая решать самые разнообразные задачи: от написания кода и обработки математических формул до сочинения поэтических строк. Однако за кулисами таких проектов стоит огромная работа по отладке, обучению и проверке—и тут на сцену выходит DeepSeek-R1. Этот проект впечатлил многих тем, что обучился «думать» и рассуждать в ходе чистого обучения с подкреплением (reinforcement learning RL) и продемонстрировал, что сложные цепочки логики можно формировать без стандартного этапа SFT (supervised fine-tuning - тонкая настройка с учителем).
В данной статье я поделюсь своим взглядом на DeepSeek-R1, а также расскажу о некоторых технических подробностях и возможностях проекта.
Ключевые особенности DeepSeek-R1
Чтобы лучше понять новизну и уникальность этого решения, давайте взглянем на несколько интересных деталей (используем эмоджи вместо цифр):
🔬 Уникальное обучение (RL без предварительного SFT)
Разработчики из команды DeepSeek решили пропустить привычный этап «предварительного обучения с учителем» (SFT) и сразу применить масштабное обучение с подкреплением (RL). Обычно RL используют как финишный этап, когда модель уже знает базовые принципы языка и логику. Но в DeepSeek-R1-Zero (предварительной версии модели) RL стал основным «строителем» навыков. Благодаря этому модель научилась применять сложные цепочки рассуждений (chain-of-thought, CoT), что позволило ей решать нестандартные задачи и формировать довольно развернутые ответы.
🛠️ Исправление «капризов» модели
Первая версия (DeepSeek-R1-Zero) показала немало интересного, однако у неё были проблемы: повторение одних и тех же фрагментов текста, нестабильная структура предложений, смешение языков. Чтобы устранить эти шероховатости, авторы ввели ряд дообучений и доработок—добавили холодный старт с небольшим корпусом данных и дообучили модель заново, уже учитывая предпочтения пользователей. Так родилась финальная версия DeepSeek-R1, которая показывает достойную производительность даже в сравнении с проприетарными моделями.
🔥 Дистилляция: большие модели учат маленькие
Не все компании и исследователи могут позволить себе огромные вычислительные мощности для запуска гигантских LLM, особенно если речь идёт о моделях с «трёхзначным» количеством миллиардов параметров. Поэтому авторы проекта показали, как можно «скопировать» навыки из DeepSeek-R1 в меньшие модели (например, на базе Qwen или Llama), используя технику дистилляции. В результате сообщество получило несколько компактных вариантов (от 1.5B до 70B параметров), которые, по данным авторов, превосходят свои аналоги, обученные «с нуля».
👨🔧 Технические нюансы реализации
DeepSeek-R1 построена на архитектуре MoE (Mixture-of-Experts - Модель смеси экспертов): это значит, что модель имеет «экспертов» внутри себя, и во время генерации текста «активируется» лишь часть параметров (примерно 37 млрд из общей 671 млрд). Подход, когда не все параметры задействуются одновременно, помогает экономить вычислительные ресурсы и получать более гибкие ответы.
- Для оценки производительности модели использовался целый набор бенчмарков: от математических (AIME, MATH-500) до кодерских (LiveCodeBench, Codeforces) и языковых (MMLU, SimpleQA).
- Кроме того, в проекте доступен увеличенный контекст (до 128K токенов)—это позволяет «читать» и «понимать» очень длинные тексты за один раз.
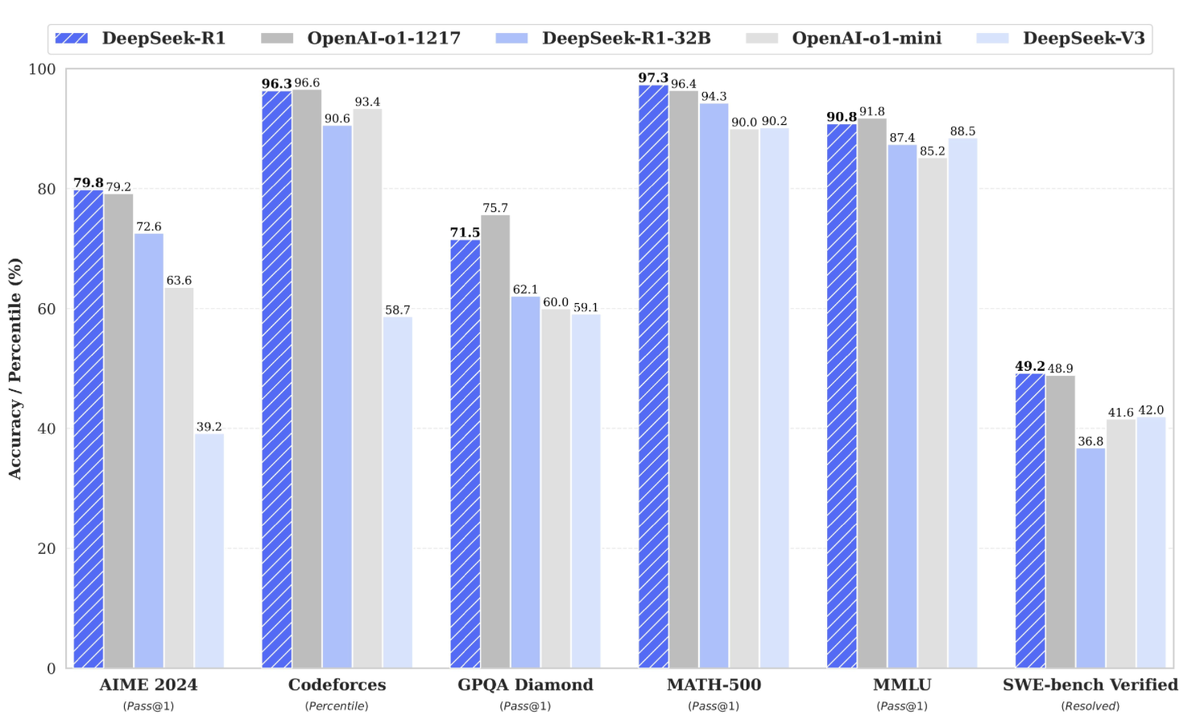
Почему это важно с практической точки зрения
🤝 Удобная интеграция в бизнес
Модели уровня DeepSeek-R1 позволяют создать интеллектуальных помощников, которые умеют выполнять нетривиальные задачи (генерация кода, разбор статистики, анализ контекста). Благодаря прогрессивному лицензированию (MIT License + особенности лицензий Qwen и Llama) многие компании могут смело пробовать интегрировать DeepSeek-R1 в свою инфраструктуру для коммерческого использования.
🔒 Гибкость и прозрачность
Открытый код (GitHub-репозиторий) даёт возможность исследователям и разработчикам понять, как именно внутри устроен механизм обучения с подкреплением, а также модифицировать пайплайн под свои задачи. За счёт этого усиливается доверие к модели и появляется простор для экспериментов.
⚙️ Эффективное масштабирование
Благодаря дистилляции можно обучить более компактные версии модели, которые сохранят большую часть логических и языковых навыков. Это снижает требования к аппаратным ресурсам, что упрощает внедрение в те области, где нет «фермы GPU» под рукой.
Личное мнение и немного размышлений
Мне кажется особенно ценным тот факт, что DeepSeek-R1-Zero удалось обучить исключительно с помощью RL без SFT. Ведь многие крупные модели, вроде GPT, опираются на огромные датасеты с человеческой разметкой. Это, конечно, даёт сразу приличный базис, но в будущем мы рискуем всё сильнее ограничивать креативность и способность модели «изобретать» собственные подходы к решению. Если RL «с нуля» станет стандартной практикой, у нас появятся модели, способные открывать новые паттерны мышления, а не только следовать за человеческими метками.
С другой стороны, большие языковые модели по-прежнему требуют гигантских вычислительных ресурсов, и не каждый может позволить себе держать модель масштабов DeepSeek-R1. Тем не менее, дистилляция—это один из самых перспективных путей распространения достижений больших LLM в более узкие, но массовые приложения, будь то чат-боты для обучения, специализированные виртуальные ассистенты или даже роботы-собеседники для психологической помощи.
Где пощупать DeepSeek-R1
🖥️ Онлайн-демо: вы можете пообщаться с DeepSeek-R1 прямо на официальном сайте chat.deepseek.com. Там есть специальная кнопка «DeepThink», которая включает расширенный режим reasoning.
🔑 OpenAI-совместимый API: если хочется интегрировать модель в свой сервис, авторы предоставляют удобную платформу с OpenAI-совместимым API на platform.deepseek.com.
⚙️ Локальный запуск: для любителей «пощупать всё своими руками» в репозитории проекта есть инструкции, как установить DeepSeek-R1-Distill модели, в частности на Qwen или Llama, и запустить их через vllm или SGLang.
Ссылки на новости и дополнительные ресурсы
- Hugging Face-репозиторий с моделями:
(Упоминается в официальном README DeepSeek-R1; конкретные ссылки можно найти по названиям, например: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B)
Заключение
DeepSeek-R1—яркий пример того, как прогрессивные методы RL способны шагнуть вперёд и показать мощь самообучающихся алгоритмов. Да, технология ещё не идеальна: от длинных повторений и «самоповторов» никуда не деться, но команда DeepSeek уже сделала большой шаг к созданию моделей, которые могут по-настоящему размышлять. А с учётом возможностей дистилляции, многие разработчики (и даже энтузиасты) теперь смогут использовать эти достижения в собственных проектах.
Будущее обещает быть интересным, ведь каждая такая модель—это эксперимент, который открывает всё новые и новые горизонты в понимании того, как «машинное мышление» может соседствовать с человеческим.