Ютуб уже завален роликами, озвученными одними и теми же закадровыми робоголосами. Деградация контента - полнейшая, люди вместо профессионального закадрового перевода иностранного материала просто отдают эту рутину на откуп нейросетям. Ввиду отсутствия альтернатив, мы это хаваем. Ниже я расскажу как присоединиться к касте таких видеоблогеров контентмейкеров и тоже начать засорять всевозможные видеоплощадки, тем более сегодня - это как никогда востребовано.
Что мы имеем на сегодня? Существует несколько способов автоматической озвучки и перевода видеоконтента:
1. Озвучка в Яндекс браузере. Самый простой способ. Открываешь видео на ютубе, переводишь с помощью яндекс браузера, выкачиваешь аудиодорожку с помощью любого предназначенного для этого расширения. Это, пожалуй, лучший способ, если бы не одно НО. Лицензионное соглашение вряд ли позволяет публиковать подобные переводы. Тем, кто собирается зарабатывать на подобном, стоит опасаться, что рано или поздно такие ролики могут начать блокировать на российских площадках. Хотя может это и паранойя, все-таки сейчас такого перевода очень много..
2. Платные сервисы. Нашумевшие ElevenLabs и HeyGen и еще десятки других сервисов попроще. Способ для ленивых и богатых. Реально богатых, ценники примерно 1000 рублей и более за часовой ролик, при том не везде можно преобразовывать такие длинные ролики.
3. Сам Ютуб начал делать перевод с дубляжом своих видео, к сожалению пендосы решили не добавлять русский язык (один из международных языков, на котором общаются около 500 млн человек, между прочим, зато добавили индонезийский (40 млн) и японский (150 млн) языки).
4. Опенсорс решение. Здесь речь пойдет о программе SoniTranslate. Она представляет собой комбайн из нескольких локальных нейросетей, которые при совместной работе позволяют получать дубляж любого видео на любой язык. Если знаете другие бесплатные программы, пишите в комментарии. Главный плюс - это лицензия апач, то есть можно делать с этой программой и ее продуктом что угодно, никто не предъявит потом. Главный минус - сложности с установкой.
SoniTranslate можно попробовать онлайн на huggingface и в googlecolab (в колабе дается примерно 4 часа активного использования сервера).
Интерфейс представляет собой веб приложение и выглядит примерно так (есть и русский вариант):
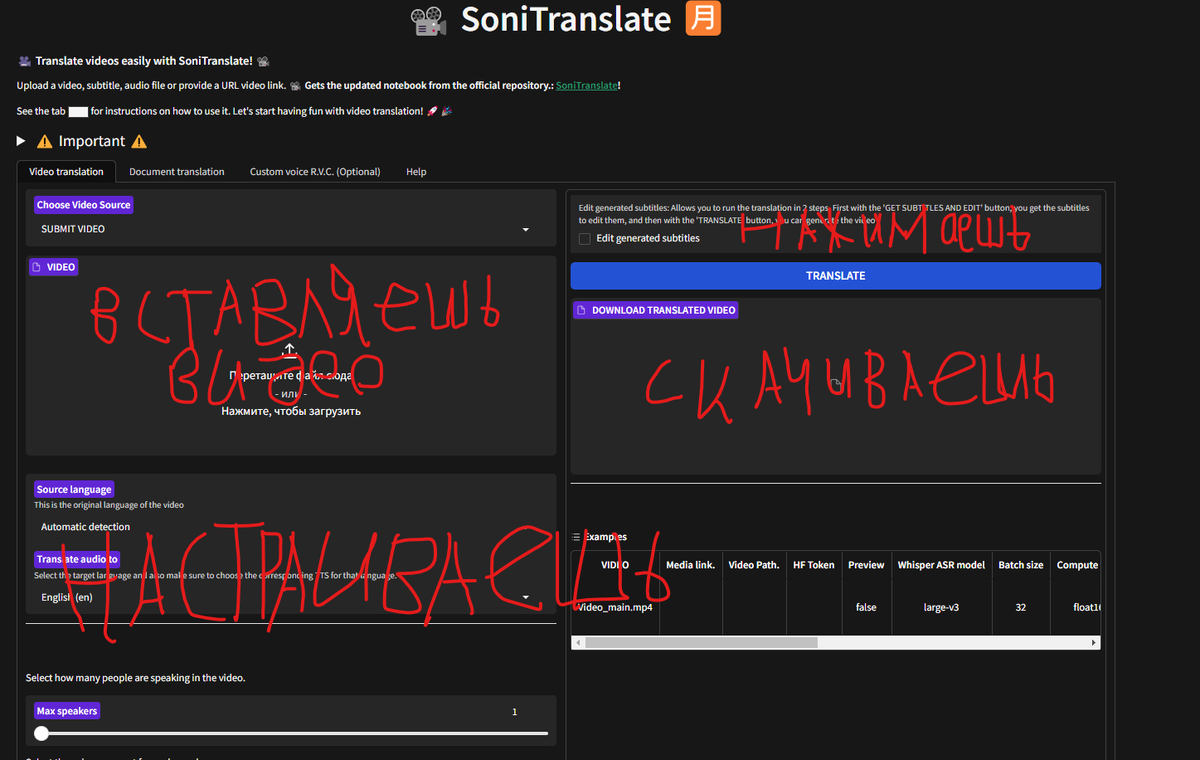
Немного информации о SoniTranslate которую выдала gemini, коротко и по делу.
________________________________________________________________________________________
Что такое SoniTranslate?
SoniTranslate - это веб-приложение с открытым исходным кодом, предназначенное для автоматического перевода видео на другие языки. В основе SoniTranslate лежит целый комплекс современных нейросетевых технологий, работающих слаженно, чтобы обеспечить качественный и быстрый перевод. Ключевые особенности SoniTranslate:
- Перевод речи с сохранением голоса: SoniTranslate не просто переводит текст, но и генерирует новую аудиодорожку, сохраняя при этом, насколько это возможно, характеристики голоса оригинального спикера, такие как тембр и интонацию.
- Синхронизация аудио: Переведенная аудиодорожка идеально синхронизируется с видеорядом, создавая ощущение естественного звучания.
- Поддержка множества языков: SoniTranslate поддерживает перевод на десятки языков, включая самые распространенные.
- Простой и удобный интерфейс: Интуитивно понятный интерфейс делает SoniTranslate доступным даже для пользователей без опыта работы с подобными инструментами.
- Открытый исходный код: SoniTranslate распространяется с открытым исходным кодом, что позволяет сообществу разработчиков вносить свой вклад в его развитие и улучшение.
- Различные варианты вывода: Программа позволяет получать результат в нескольких форматах: видео с субтитрами, видео с новой аудиодорожкой, просто аудиофайл с переводом и другие.
Как это работает?
SoniTranslate использует сложную цепочку нейросетевых моделей, каждая из которых отвечает за свой этап обработки:
- Распознавание речи (ASR): Сначала нейросеть WhisperX или её более быстрая версия faster-whisper, транскрибирует аудиодорожку из видео, преобразуя речь в текст.
- Диаризация: PyAnnote определяет, кто говорит в каждый момент времени, разделяя речь разных спикеров.
- Перевод текста: Затем текст переводится на целевой язык с помощью одной из доступных моделей перевода, таких как Google Translate, DeepL, M2M100 или даже GPT от OpenAI.
- Синтез речи (TTS): Переведенный текст озвучивается с помощью нейросетевой модели синтеза речи. SoniTranslate поддерживает различные TTS-движки, включая:
Edge-TTS: Известен своим естественным звучанием, но с ограниченным набором голосов.
Bark: Способен генерировать очень выразительную речь, но может быть медленным.
VITS: Быстрый и эффективный движок с хорошим качеством звучания.
Coqui XTTS: Позволяет клонировать голос по короткому аудиосэмплу, что открывает широкие возможности для персонализации перевода.
Piper: Легковесный и быстрый движок, оптимизированный для работы на устройствах с ограниченными ресурсами.
OpenAI-TTS: Высококачественный синтез речи от OpenAI, доступный через API. - Голосовая имитация (опционально): SoniTranslate позволяет применить модели RVC (Retrieval-based Voice Conversion) или OpenVoice для изменения тембра голоса, сгенерированного TTS, чтобы приблизить его к голосу оригинального спикера.
- Сведение аудио: Наконец, сгенерированная аудиодорожка сводится с оригинальным видео, создавая эффект дубляжа. При этом можно настроить громкость оригинального и переведенного аудио.
Преимущества использования SoniTranslate:
- Скорость и доступность: SoniTranslate позволяет переводить видео гораздо быстрее, чем традиционные методы дубляжа, и при этом значительно дешевле.
- Сохранение оригинального звучания: Благодаря использованию голосовой имитации, переведенное видео сохраняет, насколько это возможно, характеристики голоса оригинального спикера.
- Автоматизация процесса: SoniTranslate автоматизирует весь процесс перевода, от транскрипции до сведения аудио, что делает его удобным и простым в использовании.
- Широкие возможности кастомизации: Пользователь может выбирать различные модели для распознавания речи, перевода и синтеза голоса, а также настраивать параметры обработки аудио.
Недостатки:
- Зависимость от качества исходного аудио: Качество перевода напрямую зависит от качества аудиодорожки оригинального видео. Наличие шумов, помех или нечеткой речи может негативно сказаться на результате.
- Ограничения нейросетевых моделей: Несмотря на стремительное развитие, нейросетевые модели все еще имеют свои ограничения. В некоторых случаях перевод может быть неточным или неестественным.
- Необходимость мощного оборудования: Для комфортной работы SoniTranslate, особенно при использовании голосовой имитации, рекомендуется использовать компьютер с мощным процессором и видеокартой с поддержкой CUDA (не обязательно).
____________________________________________________________________________________
Вот такая чудо-программка. Как же ее использовать? Вот тут и зарыта собака. Чтобы ее установить на своем компьютере надо хорошенько по ебпрыгать с бубном. Сразу говорю, инструкция, написанная на гитхабе не работает в винде. Сама программа работает, но если следовать алгоритму шаг за шагом изложенном на гитхабе SoniTranslate, то ничего не получится, тем более там инструкция написана на для линукса. Более того, на линуксе судя по всему тоже без танцев с бубнами не обойтись из-за различных проблем с версиями пакетов.
Для себя я выбрал установку этой программы в docker контейнер. Способ хорош тем, что не надо захламлять систему кучей ненужных пакетов. И еще тем, что он будет работать у всех.
Что нам нужно для установки и использования sonitranslator?
- Гигов 40 свободного места на диске, докер неприлично требователен к дисковому пространству.
- Аккаунт на huggingface.co.
- Компьютер поддерживающий WSL2.
- Гигов 8 оперативки.
Система быстро работает с видеокартой поддерживающей CUDA, но чисто на процессоре тоже работает, правда медленно
Алгоритм установки
- Убеждаемся, что включена поддержка WSL2 в BIOS. Для этого открываем Диспетчер задач, перерходим на вкладку Производительность и смотрим внизу строчку (между логическими прцессорами и кэшом L1) под названием "Виртуализация". Если включена, то все в порядке, если нет, гуглим, как включить WSL2, возможно придется зайти в биос.
- Устанавливаем Docker Desktop с офф. сайта. Запускаем его, в настройках указываем, что хотим использовать WSL2.
- Принимаем лицензионное соглашение на страницах https://huggingface.co/pyannote/speaker-diarization и https://huggingface.co/pyannote/segmentation .
- Создаем токен доступа на huggingface. Переходим на страницу настроек токена, нажимаем "+ Создать новый токен" в открывшемся окне выбираем вкладку "Читать" и пишем название токена, нажимаем "создать токен". Получаем набор символов, его надо будет сохранить куда-нибудь в блокнот, он понадобится дальше.
- Открываем PowerShell.
- Создаем папку, переходим в нее, и создаем Dockerfile в этой директории (команды вводим последовательно в powershell:
mkdir sonitranslate
cd sonitranslate
New-Item Dockerfile
- Открываем вновь созданный Dockerfile блокнотом и вставляем в него следующие строки:
# Используем образ Python 3.10 в качестве базового
FROM pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime
# Устанавливаем часовой пояс (пример для Москвы)
ARG TZ=Europe/Moscow
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# Устанавливаем системные зависимости
RUN apt-get update && apt-get install -y --no-install-recommends \
git \
git-lfs \
ffmpeg \
wget \
g++ \
&& rm -rf /var/lib/apt/lists/*
# Устанавливаем директорию проекта
WORKDIR /app
# Клонируем репозиторий SoniTranslate с GitHub
ARG GITHUB_REPO=https://github.com/R3gm/SoniTranslate.git
ARG BRANCH=main
RUN git clone ${GITHUB_REPO} . && \
git checkout ${BRANCH}
# Устанавливаем lfs
RUN git lfs install
# Устанавливаем зависимости Python
RUN python -m pip install --upgrade pip
RUN python -m pip install pip==23.1.2
RUN pip install -r requirements_base.txt -v
# Устанавливаем fairseq из репозитория
RUN git clone https://github.com/facebookresearch/fairseq.git /tmp/fairseq && \
cd /tmp/fairseq && \
pip install --editable ./
# Устанавливаем остальные зависимости из requirements_extra.txt, исключая fairseq
RUN sed '/^fairseq/d' -e '/^#/d' requirements_extra.txt | xargs pip install -v
RUN pip install onnxruntime-gpu
# Опционально: Устанавливаем Piper TTS
ARG INSTALL_PIPER_TTS=true
RUN if [ "$INSTALL_PIPER_TTS" = "true" ]; then pip install -q piper-tts==1.2.0; fi
# Опционально: Устанавливаем Coqui XTTS
ARG INSTALL_COQUI_XTTS=true
RUN if [ "$INSTALL_COQUI_XTTS" = "true" ]; then pip install -q -r requirements_xtts.txt && pip install -q TTS==0.21.1 --no-deps; fi
# Устанавливаем переменные окружения
ARG DEFAULT_HF_TOKEN=Здесь_Вставляете_Свой_Токен
ENV YOUR_HF_TOKEN=${DEFAULT_HF_TOKEN}
# Создаем директории
RUN mkdir -p /app/downloads /app/logs /app/weights /app/clean_song_output /app/_XTTS_ /app/audio2/audio /app/audio /app/outputs
# Запуск приложения
ENTRYPOINT ["python", "app_rvc.py"]
CMD ["--theme", "Taithrah/Minimal", "--verbosity_level", "info", "--language", "russian"]
Обратите внимание на строчку:
ARG DEFAULT_HF_TOKEN=Здесь_Вставляете_Свой_Токен
в нее надо вставить ранее полученный токен. Сохраняем файл.
- Возвращаемся в powershell и вводим команду:
docker build -t sonitranslate .
- Ждем. Ждать придется долго, эта команда скачивает и устанавливает пакеты, а некоторые и собирает из исходников (я же говорил про проблемы с версиями пакетов) согласно вышеуказанному скрипту в контейнер с названием sonitranslate.
- Если все прошло успешно запускаем контейнер:
docker run -it --network host sonitranslate
Для тех у кого нет видеокарты nvidia команда:
docker run -it --network host sonitranslate --cpu_mode
Можно использовать разные аргументы:
docker run -it --network host -e YOUR_HF_TOKEN="YOUR_HUGGING_FACE_TOKEN" sonitranslate --theme Taithrah/Minimal --verbosity_level info --language russian --cpu_mode
Сразу говорю, для повторного запуска этого же контейнера, а не его копии потребуется другая команда:
Сначала смотрим ID контейнера
docker ps -a
Потом
docker start -a 91154f3ccc5b
Где 91154f3c3c5b - ID контейнера
- Если все запустилось удачно, контейнер начинает докачивать пакеты, и в конце выдает строку:
Running on local URL: http://127.0.0.1:7860
либо Running on local URL: http://127.0.0.1:7861
- Открываем указанный адрес в браузере. Программа готова к использованию.
Настройки SoniTranslator
Настроек много, обращаюсь опять к gemini, чтобы он (они или она, хз вроде и множественное число, но нейросеть - женский род) сделал небольшой ликбез по настройкам, потом расскажу какие я использую.
_______________________________________________________________________________________
Основные вкладки:
- Translate (Перевод): Основная вкладка для перевода видео.
- Docs (Документы): Вкладка для перевода текстовых документов и создания аудиокниг (экспериментальная функция).
- Custom voice R.V.C. (Optional) (Пользовательский голос R.V.C.): Вкладка для настройки моделей R.V.C., используемых для изменения тембра голоса.
- Help (Помощь): Справочная информация о программе.
Вкладка Translate (Перевод):
1. Входные данные:
- Video Source (Источник видео): Выбор источника видео.
SUBMIT VIDEO: Загрузка видеофайла с компьютера. Поддерживается загрузка нескольких файлов.
URL: Указание ссылки на видео (например, YouTube, Rutube и т.д.). Можно добавить несколько ссылок через запятую. Поддерживается скачивание плейлистов YouTube.
Find Video Path: Указание пути к папке с видеофайлами на компьютере. Можно указать несколько папок, разделяя их запятыми. - Video Input (Видео): Поле для загрузки видеофайла (при выборе "SUBMIT VIDEO").
- Link Input (Ссылка): Поле для ввода ссылки на видео (при выборе "URL").
- Directory Input (Путь к папке): Поле для ввода пути к папке с видео (при выборе "Find Video Path").
- HF Token (Токен Hugging Face): Поле для ввода токена Hugging Face. Необходим для работы с моделями, требующими аутентификации (например, PyAnnote).
- Preview (Предпросмотр): Позволяет ограничить длину обрабатываемого видео (полезно для тестирования). По умолчанию включена и ограничена 10 секундами для экономии ресурсов CPU в демо-версии.
- Whisper ASR model (Модель Whisper ASR): Выбор модели Whisper для распознавания речи.
large-v3: Наиболее точная модель (рекомендуется, если позволяет оборудование).
large-v2, large: Предыдущие версии large.
medium, medium.en: Средние по размеру и точности модели.
small, small.en: Меньшие по размеру модели, работают быстрее, но менее точные.
base, base.en: Базовые модели.
tiny, tiny.en: Самые маленькие и быстрые модели, но наименее точные.
Модели с .en: Оптимизированы для английского языка.
OpenAI_API_Whisper: Позволяет использовать платное API от OpenAI.
Можно указать адрес модели из репозитория HuggingFace (например, kotoba-tech/kotoba-whisper-v1.1 для японского языка). - Batch Size (Размер пакета): Размер пакета данных для обработки моделью Whisper. Большие значения ускоряют обработку, но требуют больше памяти.
- Compute Type (Тип вычислений):
auto: Автоматический выбор типа вычислений.
int8, int8_float16, int16, float16, float32: Типы данных для вычислений. float16 рекомендуется для GPU, float32 для CPU. - Source Language (Исходный язык): Выбор языка оригинала видео.
Automatic detection: Автоматическое определение языка (не всегда работает идеально).
Выбор языка из списка. - Target Language (Целевой язык): Выбор языка, на который нужно перевести видео.
- Min Speakers (Мин. кол-во спикеров): Минимальное количество спикеров для диаризации.
- Max Speakers (Макс. кол-во спикеров): Максимальное количество спикеров для диаризации.
2. Выбор голосов для TTS:
- TTS voice00 - TTS voice11 (Голос TTS 00 - Голос TTS 11): Выбор голоса для каждого спикера. Доступные голоса зависят от выбранных TTS-движков.
3. Настройки Voice Conversion (VC):
- Enable Voice Conversion (Включить преобразование голоса): Включает преобразование голоса с помощью R.V.C. или OpenVoice.
- Voice Conversion Method (Метод преобразования голоса): Выбор метода: freevc, openvoice, openvoice_v2.
- Voice Conversion Max Segments (Макс. сегментов для преобразования): Максимальное количество сегментов для обработки моделью VC.
- Voice Imitation Vocals Dereverb (Удаление реверберации для голосовой имитации): Позволяет улучшить качество вокала, убрав из него реверберацию, для лучшей имитации голоса.
- Voice Imitation Remove Previous (Удалить предыдущие): При включении этой опции, после обработки сегмента, временные файлы удаляются, что экономит место, но замедляет обработку.
- Dereverb Automatic XTTS (Удаление реверберации для XTTS): Автоматически удаляет реверберацию из аудио, используемых для клонирования голоса в Coqui XTTS.
- Text Segmentation Scale (Масштаб сегментации текста):
sentence: Сегментация по предложениям.
word: Сегментация по словам (для субтитров).
character: Сегментация по символам (для субтитров). - Divide Text Segments by (Разделение текстовых сегментов по): Символы-разделители, по которым можно дополнительно разбить сегменты текста.
- Soft Subtitles to Video (Мягкие субтитры): Вшивание субтитров в видео в виде отдельной дорожки (можно включать/отключать при просмотре).
- Burn Subtitles to Video (Жесткие субтитры): Вшивание субтитров в видеоряд (нельзя отключить).
4. Дополнительные настройки (Extra Setting):
- Max Audio Acceleration (Макс. ускорение аудио): Максимальная скорость ускорения аудио для компенсации разницы в длине предложений между языками.
- Acceleration Rate Regulation (Регулирование скорости ускорения): Включение регулирования скорости ускорения.
- Avoid Overlap (Избегать наложения): Предотвращает наложение переведённых сегментов друг на друга.
- Audio Mix Options (Параметры микширования аудио):
Mixing audio with sidechain compression: Использование сайдчейн-компрессии для автоматического приглушения оригинальной дорожки во время звучания перевода.
Adjusting volumes and mixing audio: Простое микширование оригинальной и переведённой дорожек с возможностью настройки громкости. - Volume Original Audio (Громкость оригинального аудио): Громкость оригинальной дорожки (для "Adjusting volumes...").
- Volume Translated Audio (Громкость переведённого аудио): Громкость переведённой дорожки (для "Adjusting volumes...").
- Voiceless Track (Безголосная дорожка): Замена оригинальной дорожки на дорожку без вокала (используется для создания караоке-версий).
- Subtitle Type (Тип субтитров): Выбор формата выходных субтитров: disable (отключить), srt, vtt, ass, txt, tsv, json, aud.
- Vocal Refinement (Улучшение вокала): Использование алгоритмов очистки вокала от шумов и реверберации.
- Literalize Numbers (Преобразование чисел): Преобразование чисел из цифровой записи в буквенную (например, 123 -> сто двадцать три).
- Segment Duration Limit (Ограничение длительности сегмента): Максимальная длительность сегмента в секундах.
- Diarization Model (Модель диаризации): Выбор модели для диаризации.
pyannote_2.1 (default): Стандартная модель.
pyannote_3.1: Новая версия (требует токен).
disable: Отключить диаризацию. - Translate Process (Процесс перевода): Выбор сервиса перевода: google_translator, google_translator_batch, m2m100_418m, m2m100_1.2b, mbart_large_50_many_to_many_mmt, marianmt, Helsinki-NLP, gpt-3.5-turbo, gpt-4 (последние два - платные API OpenAI).
- SRT file: Загрузка SRT файла с субтитрами. Если загружен, то перевод будет осуществляться по нему, а оригинал видео не потребуется
- Output Type (Тип вывода):
video (mp4): Видео с переведённой аудиодорожкой (по умолчанию).
video (mkv): Видео с переведённой аудиодорожкой в формате MKV.
video [subtitled] (mp4): Видео с вшитыми субтитрами.
video [subtitled] (mkv): Видео с вшитыми субтитрами в формате MKV.
audio (mp3): Аудиофайл в формате MP3.
audio (wav): Аудиофайл в формате WAV.
audio (ogg): Аудиофайл в формате OGG.
subtitle: Файл субтитров в выбранном формате.
subtitle [by speaker]: Файл субтитров с указанием говорящего.
raw media: Необработанный медиа-файл.
sound: Отдельные звуковые дорожки. - Output Name (Имя выходного файла): Имя выходного файла (без расширения).
- Enable Cache (Включить кэширование): Включение/отключение кэширования промежуточных результатов для ускорения обработки.
- Custom voices (Пользовательские голоса): Включение использования кастомных RVC моделей.
- Custom voices workers (Количество потоков для RVC): Количество потоков для одновременной обработки разными RVC моделями.
- Task finish sound alert (Звуковое оповещение об окончании задачи): Включение/отключение звукового сигнала по окончании обработки.
Вкладка Docs (Документы):
- Input Type (Тип ввода):
WRITE TEXT: Ввод текста вручную.
SUBMIT DOCUMENT: Загрузка документа (.txt, .pdf, .docx, .rtf).
Document Path: Указание пути к файлу документа. - Text (Текст): Поле для ввода текста (при выборе "WRITE TEXT").
- Document (Документ): Поле для загрузки документа.
- Document Path (Путь к документу): Поле для ввода пути к документу.
- TTS (Синтез речи): Выбор голоса для озвучивания текста.
- Source Language (Исходный язык): Исходный язык текста.
- Target Language (Целевой язык): Язык, на который нужно перевести текст.
- Translate Process (Процесс перевода): Выбор сервиса перевода.
- Output Type (Тип вывода):
audio: Аудиофайл.
book (txt): Текстовый файл с переводом.
videobook (mp4): Видео с изображением страниц и аудио (для PDF).
videobook (mkv): Видео с изображением страниц и аудио (для PDF) в формате MKV. - Output Name (Имя выходного файла): Имя выходного файла.
- Chunk Size (Размер фрагмента): Размер фрагмента текста для TTS (в символах).
- Start Page (Начальная страница): Номер начальной страницы для обработки (для PDF и DOCX).
- End Page (Конечная страница): Номер конечной страницы для обработки (для PDF и DOCX).
- Width (Ширина): Ширина видео (для videobook).
- Height (Высота): Высота видео (для videobook).
- Border Color (Цвет рамки): Цвет рамки вокруг страниц (для videobook).
Вкладка Custom voice R.V.C. (Optional):
Эта вкладка позволяет настроить модели R.V.C. для изменения тембра голоса. Подробное описание этой вкладки выходит за рамки данного ответа, так как требует более глубокого понимания работы R.V.C. моделей.
______________________________________________________________________________________
Исчерпывающе.
Мои настройки почти дефолтные:
Source language - Automatic detection
Translate audio to - Russian (ru)
Max speakers - 4, больше лучше, чем меньше.
TTS Speaker - ru_speaker_8-Male BARK (8, 7, 4, 3). Третий и четвертый вроде получше звучат, их стоит выбирать первыми.
Active Voice Imitation - включен. Method - freevc. Другие методы более агрессивные, голос повторяют лучше, но не всегда это хорошо.
Max sample - 3. Другие варианты пока не пробовал.
Далее по умолчанию, Batch size увеличил до 24 ГБ, но столько не надо, на скорость не влияет, потребляет всего 7 ГБ.
Output type - audio (mp3) - для экономии места, потом через видеоредактор можно объединить с оригинальным видео.. Лучше сразу выбирать видеоформат.
File name - perevod1
Retrieve Progress - вкл, важная галочка, при повторном переозвучивании, например при активации имитации голоса, программе не придется проделывать всю работу заново.
Пример
Для примера переозвучил видеоролик OpenAI день 12, тот где Сэм Альтман gpt-03 презентовал. Настройки почти дефолтные, голос Сэма Альтмана получился плохо (вероятно из-за того, что он быстро тараторит), голоса китайцев, по-моему, получились хорошо. Надо пробовать другие настройки.
Резюмируя, хочу сказать, что данное решение не идеальное, но оно работает. Сейчас мы находимся между моментами, когда коммерческие модели Sound to Sound уже есть, а открытые s2s модели еще не созданы или они очень плохи, поэтому приходится использовать такие костыли. Уверен, что скоро появятся более элегантные решения, либо TTS модели станут идеальными, в любом случае глупо жаловаться на опенсорс продукты.