
Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений.
О библиотеке FastStream
Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а о Quix Streams – здесь. Сегодня хочу рассказать о FastStream — еще одной интересной библиотеке для создания потоковых конвейеров на Python. Этот простой, но очень мощный фреймворк облегчает разработку продюсеров и потребителей, предоставляя унифицированный API для работы с несколькими брокерами сообщений: Kafka, RabbitMQ, NATS и Redis. Взаимодействие с Apache Kafka реализуется на основе библиотек AIOKafka и Confluent. Однако, в отличие от AIOKafka и Confluent, в FastStream основным объектом, вокруг которого строится потоковый конвейер, является брокер.
Брокеры FastStream предоставляют удобные декораторы функций: @broker.subscriber(…) и @broker.publisher(…), которые автоматизируют следующие функции при разработке кода:
- публикация и потребление сообщений в очереди событий;
- кодирование и декодирование сообщений в формате JSON;
Эти декораторы брокеров упрощают определение логики обработки для продюсеров и потребителей, позволяя сосредоточиться на основной бизнес-логике потокового приложения. Также FastStream использует Pydantic трансформации входных данных в формате JSON в объекты Python, что упрощает работу со структурированными данными, позволяя сериализовать входные сообщения, просто используя аннотации типов.
FastStream позволяет обрабатывать большие объемы данных с минимальными задержками, а также поддерживает многопоточность и параллельную обработку данных, что значительно ускоряет выполнение задач на многоядерных системах. Кроме того, фреймворк можно можно использовать как часть библиотеки FastAPI для быстрого создания веб-приложений в стиле REST. Для этого нужно всего лишь импортировать необходимый StreamRouter и объявить обработчик сообщений с теми же параметрами и декораторами: @router.subscriber(…) и @router.publisher(…). Об этом я расскажу в другой раз, а пока рассмотрим пример публикации данных в топик Kafka с помощью FastStream.
Пример публикации данных в Kafka
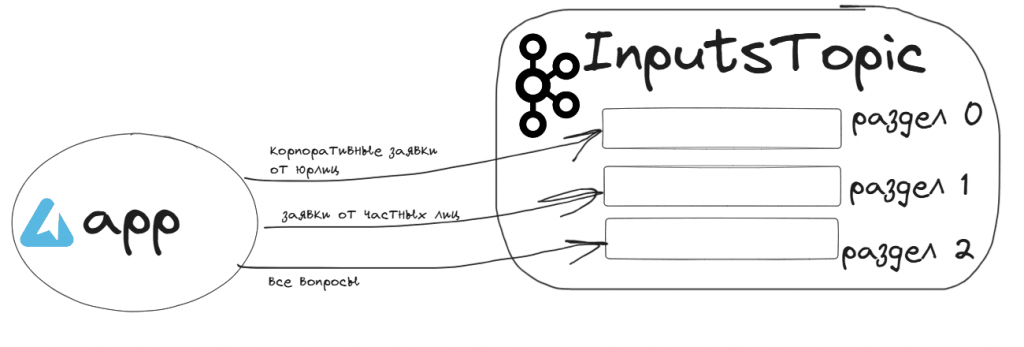
Как обычно, в качестве примера возьму публикацию клиентских обращений в топик InputsTopic: заявки на покупку продуктов в интернет-магазине от физических или юридических лиц или вопросы покупателей. Топик InputsTopic разделен на 3 раздела, маршрутизация сообщений по которым зависит от типа обращения:
- корпоративные заявки от юрлиц публикуются в раздел 0;
- заявки от частных лиц публикуются в раздел 1;
- все вопросы публикуются в раздел 2.
Данные обращений в формате JSON имеют похожий, но немного отличающийся набор полей.
Чтобы вы могли легко повторить это упражнение, буду писать и запускать Python-код в интерактивной среде Google Colab. Сперва установим нужные пакеты и импортируем модули:
Затем зададим списки значений и определим параметры подключения к Kafka.
В этот раз параметры для подключения к Kafka (URL-адрес bootstrap-сервера, логин и пароль) я сохранила в хранилище секретов Google Colab, получая в коде значения этих ключей.
Далее напишем код асинхронной публикации сообщений в Kafka, используя API FastStream на основе AIOKafka – python-клиента, который базируется на библиотеке kafka-python. Но, в отличие от kafka-python, AIOKafka работает асинхронно благодаря использованию asyncio, что позволяет выполнять операции без блокировки основного потока. Это особенно полезно для приложений, требующих высокой производительности и параллельности. AIOKafka предоставляет асинхронные интерфейсы для продюсеров и потребителей, что требует использования синтаксиса async/await.
Для типизации публикуемых данных будем использовать классы, чтобы избежать дублирования кода и поддерживать единообразие между различными типами клиентских обращений.
В этом коде асинхронная функция publish_data() постоянно в бесконечном цикле каждые 2 секунды генерирует фейковые данные и вычисляет номер раздела топика Kafka, преобразует сообщение в JSON-строку, выводит информацию о публикации данных и, при возникновении ошибки логирует её.
Благодаря методу asdict из модуля dataclasses, объекты классов легко преобразуются в словари, что упрощает их сериализацию в формат JSON для отправки в брокер. Аннотации типов в @dataclass также используются для автоматической генерации спецификации AsyncApi, что я показываю здесь. А в заключение отмечу, что сообщения успешно опубликованы в Kafka.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"



















