Идея, лежащая в основе MASE, заключается в том, чтобы масштабировать ошибки на основе оценки MAE, полученной на обучающей выборке с помощью методов наивного прогноза или наивного сезонного прогноза. Для временного ряда без сезонности формула MASE выглядит следующим образом:
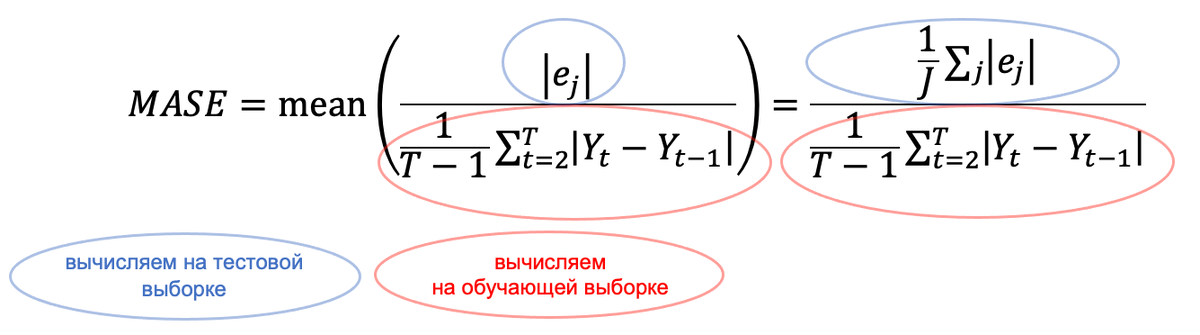
Здесь числитель – средняя абсолютная ошибка, полученная на тестовой выборке. В ее основе лежит |e_j| – абсолютная ошибка прогноза для данного момента времени в тестовой выборке (где J – количество прогнозов). Речь идет об абсолютной разнице между фактическим значением (Y_j) и прогнозом (F_j) для данного момента времени в тестовой выборке: |e_j|= |Y_j - F_j|. Знаменатель – средняя абсолютная ошибка, полученная на обучающей выборке (здесь она задана как t=1…T) с помощью одношагового метода наивного прогноза, который использует в качестве прогноза последнее фактическое значение: F_t = Y_t-1. Проще говоря, оценку MAE, полученную с помощью прогнозов рабочей модели, делим на оценку MAE, полученную с помощью наивных прогнозов.
Для временного ряда с сезонностью формула MASE выглядит следующим образом:
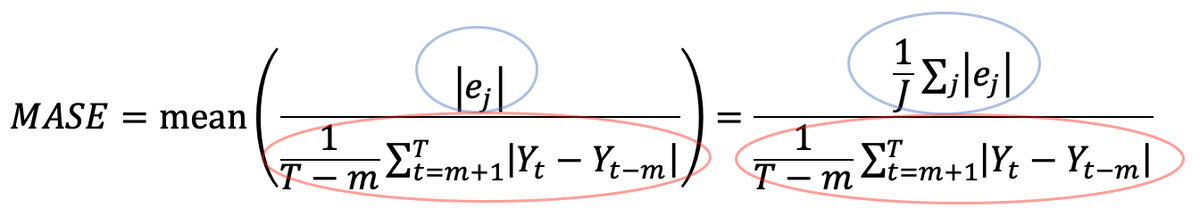
Здесь числителем по-прежнему является средняя абсолютная ошибка, полученная на тестовой выборке. Мы опять вычисляем абсолютную разницу между фактическим значением (Y_j) и прогнозом (F_j) для данного момента времени в тестовой выборке: |e_j|= |Y_j - F_j|. Знаменатель – средняя абсолютная ошибка, полученная на обучающей выборке (здесь она задана как t=1…T) с помощью одношагового метода наивного сезонного прогноза, который использует в качестве прогноза последнее фактическое значение для того же времени года: F_t = Y_t-m, где m – количество периодов в полном сезонном цикле. Таким образом, оценку MAE, полученную с помощью прогнозов рабочей модели, делим на оценку MAE, полученную с помощью наивных сезонных прогнозов.
Чем меньше значение метрики, тем лучше качество модели.
По мнению Роба Хайндмана и Анне Келер, MASE имеет ряд следующих желательных свойств.
1. Инвариантность к масштабу: MASE не зависит от масштаба данных, поэтому метрику можно использовать при сравнении прогнозов для наборов данных с разными масштабами;
2. Предсказуемое поведение, когда y_t -> 0: процентные метрики качества прогнозов типа средней абсолютной процентной ошибки (MAPE), основаны на делении на y_t, искажая распределение MAPE для значений y_t, близких к 0 или равных 0. Вспомним, что это особенно проблематично для данных, у которых шкала не имеет естественной нулевой точки (например, температура в градусах Цельсия или Фаренгейта).
3. Симметрия: средняя абсолютная масштабированная ошибка одинаково штрафует как положительные, так и отрицательные ошибки прогнозов, а также штрафует за ошибки при прогнозировании как маленьких, так и больших чисел.
4. Интерпретируемость: среднюю абсолютную масштабированную ошибку можно легко интерпретировать.
Если MASE=1, то рассматриваемые прогнозы работают так же, как одношаговые прогнозы на основе обучающей выборки, полученные с помощью наивного метода.
Если MASE<1, то рассматриваемые прогнозы работают лучше, чем одношаговые прогнозы на основе обучающей выборки, полученные с помощью наивного метода.
Если MASE>1, то рассматриваемые прогнозы работают хуже, чем одношаговые прогнозы на основе обучающей выборки, полученные с помощью наивного метода.
Можно еще дать такую интерпретацию: MASE показывает, во сколько раз ошибка прогноза оказалась выше среднего абсолютного отклонения ряда в первых разностях.
5. Асимптотическая нормальность: для проверки статистической значимости разницы между двумя наборами прогнозов можно использовать критерий Диболда-Мариано для одношаговых прогнозов. Для проверки гипотезы с помощью статистики Диболда-Мариано желательно, чтобы DM ~ N(0,1) , где DM – значение статистики Диболда-Мариано. Philip Hans Franses (Филип Ханс Франсес) в своей статье «A note on the Mean Absolute Scaled Error» показал, что статистика Диболда-Мариано для MASE аппроксимирует это распределение, чего нельзя сказать о MAPE и SMAPE.
Таким образом, эту независимую от масштаба метрику можно использовать для сравнения методов прогноза по одному ряду, а также для сравнения качества прогнозов между рядами. Эта метрика хорошо подходит для серий с прерывистым спросом, поскольку она никогда не дает бесконечных или неопределенных значений, за исключением маловероятного случая, когда все значения в исторической выборке будут равны друг другу.
Давайте напишем собственную функцию для вычисления MASE.
Допустим, мы прогнозируем количество туристов в тысячах, которое посетит страну в ближайшие семь месяцев. У нас есть фактические значения для обучающей выборки, а также фактические значения и прогнозы для тестовой выборки.
Значение MASE, близкое к 1, указывает на то, что наша модель прогнозирует на уровне модели наивного прогноза.