Удивительная вещь эта схема Бернулли! Все о ней слыхали, у кого был хоть краткий курс вероятности. Но даже выпускник математического факультета не всегда может объяснить, что к чему. Помнит наизусть, как стихи Пушкина, но и только. Я проверял. Хотя там всё просто...

Итак, есть однотипные "испытания", в которых с одной и той же вероятностью и независимо от других испытаний может наблюдаться некоторое событие, с вероятностью р. Испытаний n штук. Надо определить вероятность того, что в этой серии будет ровно m событий.
Нам надо m успехов и n-m неуспехов, независимо, так что вероятности можно перемножать. Получается вероятность m успехов подряд и затем n-m неудач подряд, равная pᵐ(1-p)ⁿ⁻ᵐ. Однако это только один вариант; а всего их больше: надо распределить m успехов по n позициям. То есть, выбрать m позиций из n возможных, при этом позицию можно выбрать один раз и порядок позиций роли не играет. Число вариантов равно "числу сочетаний из n по m", которое мы обозначим С(n,m) и для него есть общеизвестная формула. В итоге вероятность, что будет ровно m успехов из n попыток равна
C(n,m)pᵐ(1-p)ⁿ⁻ᵐ
Небольшой комментарий по поводу "порядок позиций не играет роли". Конечно, у позиции только и есть, что порядковый номер, но речь идет о порядке выбора позиций! Например, мы выбрали из ряда 1..5 позиции 2, 4 и 5, но ровно тот же выбор получится, если мы выбрали 5, 2 и 4.
Формула прекрасная, но пользоваться ею можно только в случае небольших m. Да и для больших n тоже не очень удобно. Формально-то она верна при любых n и m, но вот С(1000, 365) считать сложно. К тому же нам редко нужно что-то вроде вероятности ровно сорока двух успехов из шестьсот шестидесяти шести попыток. Чаще нужна вероятность, что число успехов между тридцатью и пятьюдесятью. А это означает применение формулы более двадцати раз. В каждой цикл считает С, и это довольно быстро может стать проблемой даже для мощного компьютера.
Кстати, при вычислении С ни в коем случае не надо вычислять факториалы и потом делить! Во-первых, вам может не хватить размера машинного целого, и получится чушь. Даже вещественного может не хватить, попробуйте вычислить факториал хотя бы от 200 (а С(200,199)=200, никаких астрономических чисел). Во-вторых, при делении может возникнуть потеря точности - но это зависит от языка, на котором вы программируете. Там в числителе стоят множители от n вниз, а в знаменателе - от 1 вверх. Вот так и надо считать. И следить, чтобы делилось все не целочисленно и без потери точности.
Однако есть удобные аппроксимации.
Прежде всего заметим, что есть такое распределение вероятностей: полиномиальное. Ненулевую вероятность имеют числа от 0 до n, и вероятность числа m вычисляется по схеме Бернулли. Число р служит параметром распределения, наряду с n. Математическое ожидание, очевидно, равно np. Это можно вычислить, но это и так ясно, поскольку вероятность - это и есть среднее число событий из большого числа попыток; из n попыток и должно быть в среднем np успехов.
Дисперсия равна np(1-p). Дисперсия - это мера разброса, случайности случайной величины. Понятно, что если р близко к 0, то есть успех нереален, то и дисперсия мала: всё предсказуемо. Аналогично и если р близко к 1. А вот любопытно тут то, что дисперсия растет линейно по n, а корень из нее - среднеквадратическое отклонение - растет медленнее. А именно среднеквадратическое отклонение важно, так как оно, а не дисперсия, имеет ту же размерность, что и сама случайная величина.
Теперь посмотрим на распределение Пуассона. Оно задает вероятность неотрицательных целых чисел i от 0 и далее формулой
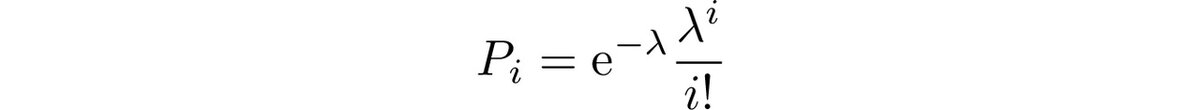
Число λ - параметр распределения.
Какой смысл у такого распределения? Оно описывает вероятность наблюдать данное число i событий за заданный интервал времени при условии, что события независимы и в среднем их происходит λ за этот интервал. Матожидание распределения равно, разумеется, λ. Менее очевидно, что такова же и дисперсия.
Распределение совсем другое, но смысл, как видно, сходен. И там, и там речь идет о каких-то успехах, которые могут наблюдаться в разном количестве. Только у Пуассона возможны любые числа, а у Бернулли нет.
Однако если р мала, и n велико, так, что λ=np имеет не слишком большое и не слишком малое значение, то Пуассон неплохо приближает Бернулли. Можно сказать, что Бернулли пренебрегает маловероятной возможностью наблюдать более, чем n событий за заданный интервал времени.
Итак, мы получили приближение. Давайте его проверим на примере.
Какова вероятность, что из тысячи гостей на свадьбе ровно у двоих дни рождения совпадут с днем рождения невесты? А ровно у одного? А что совпадений не будет?
Две последние задачи мы решили в предыдущей заметке, но решим ещё раз, иным способом. У нас n=1000, p=¹/₃₆₅, i равно 2, 1 и 0, λ=np=2.7397, exp(-λ)=0.064588. Пуассон даёт, соответственно, 0.242402, 0.176954 и 0.064588. Наиболее вероятное значение: 2. Два совпадения наиболее вероятны, 2.74 примерно в среднем.
Точные (округлённые) значения этих вероятностей 0.242578, 0.176774 и 0.064346.
То есть, на сотню свадеб с тысячей гостей на каждой примерно в четверти найдутся ровно два гостя, чьи дни рождения совпадают с невестой. Неожиданно, на мой взгляд.
Теперь зайдем с другой стороны. Отдельное испытание - это случайная величина со значениями 0 и 1 и вероятностями этих значений 1-р и р. Число успехов в n попытках есть сумма этих величин, а они по условию независимы. Это похоже на Центральную предельную теорему, согласно которой сумма независимых одинаково распределенных случайных величин распределена приблизительно нормально (и предел в некотором смысле именно и есть нормальное распределение).
Опираясь на эту теорему, можно приблизить схему Бернулли нормальным распределением. Это приближение работает при больших n. И ценно не столько возможностью получить вероятность P(42, 1000) ровно сорока двух успехов из тысячи попыток, сколько интегральной формулой, по которой можно узнать вероятность P(700, 1000, 5000) попасть в диапазон: от семисот до тысячи успехов из пяти тысяч попыток.
Это формулы Муавра-Лапласа. Которые студенты учат наизусть, но не понимают их ЦПТ-шного смысла.
Здесь надо учитывать четность φ и нечетность Ф, а также тот факт, что φ быстро убывает, так что Ф(5)=½ и для всех значений выше пяти тоже.
Давайте попробуем. Делается сто попыток, вероятность успеха в каждой равна 0.8. Какова вероятность, что успехов ровно 70 и между 70 и 80?
У нас n=100, m=70, p=0.8, 1-p=0.2, x=-2.5, φ(x)=φ(2.5)=0.0175, P(70,100)=0.0044.
Вероятность очень маленькая, потому что это вероятность одного исхода, а их много.
Теперь диапазон. У нас n=100, m₁=70, m₂=80, p=0.8, 1-p=0.2, x₁=-2.5, x₂=0, Ф(x₁)=-Ф(2.5)=-0.4938, Ф(x₂)=Ф(0)=0, P(70,80,100)=0.4938.
Обратите внимание: почти половина. Если мы вычислим Р(70,90,100), то мы получим вдвое больше, то есть 0.4938+0.4938=0.9876. Получается, что вероятность НЕ попасть в диапазон между 70 и 90 всего 0.0124! То есть теоретически может быть и сто успехов, и ноль, но практически возможен лишь диапазон 70-90.
Хотя игнорировать "черных лебедей" тоже неправильно. Но этот вопрос весьма сложен математически и частью вообще не относится к теории вероятностей. Это тема для отдельной беседы.