Суть парсимониального анализа, и чем с эволюционной точки зрения он лучше, чем метод максимального сходства, и разобрала в прошлый раз.
Давайте разберемся, как выбор наиболее экономного дерева происходит на практике. Конечно, вряд ли вам придется строить деревья вручную, но чтобы уметь интерпретировать тот или иной результат, выданный программой, надо понимать, что она делает.
Основное правило метода максимальной парсимонии - мы выбираем наиболее экономное дерево. В этом правиле скрыты два логичных вопроса. 1) Как мы выбираем? 2) Что значит самое экономное? Давайте, разбираться.
Я сделала простую маленькую матрицу для данной темы. Вот она.
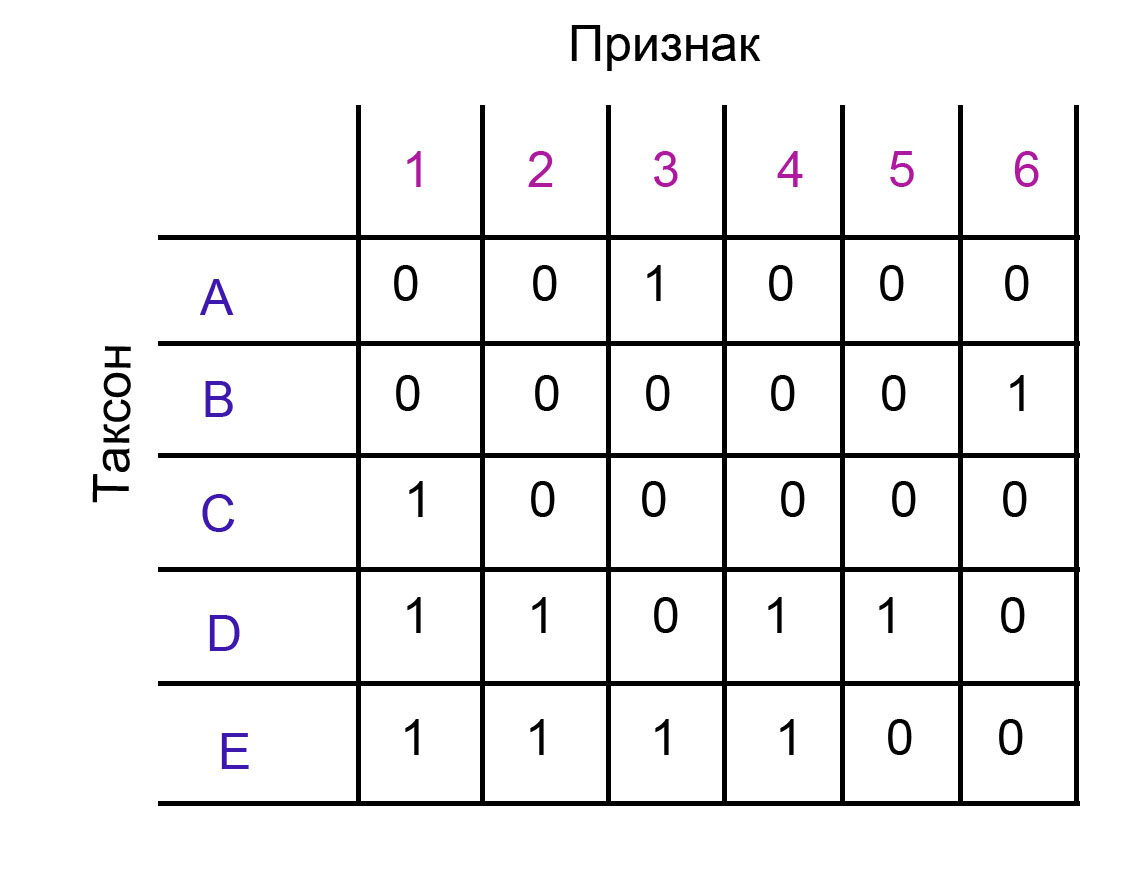
Признаки 5 и 6 обладают двумя состояниями, и только одно из них встречается у двух и более таксонов. Как я уже объясняла. для филогении такие признаки смысла не несут (Кодирование морфологических признаков Часть 1 и Часть 2). Я их специально добавила, чтобы теперь уже на примере показать, почему так происходит.
Сразу же скажу, что существует два варианта ручного анализа. Я обсужу оба. Это первый.
Начинаем с того, что рисуем вот такой неразрешенный куст
И начинаем по очереди примерять на него признаки. В этом примере мы начнем с признака 1, но можно с любого. Помните, что на данный момент мы работаем с неукорененной филогенией, и любой таксон потенциально может быть корнем. Номер признака я пишу слева, а номер состояния - справа, то есть в записи 1/0, номер признака - 1, а состояния - 0.
Нужно перебрать все возможные варианты деревьев, и подсчитать, сколько раз на каждом из них появляется анализируемый признак. Тут я привела всего четыре варианта дерева, но, понятно, что их гораздо больше. Например, в варианте когда у нас два таксона группируются вместе (номера 3 и 4), у нас 10 подвариантов, в зависимости от расположения таксонов. В варианте, когда у нас три таксона группируются вместе (номера 1 и 2), у нас тоже 10 подвариантов. В таком случае, нам надо перебрать 20 вариантов топологий и на каждой из них самым оптимальным способом разместить появление признака. Я не буду приводить все возможные деревья, но суть должна быть ясна.
Каждое появление признака на дереве - это один шаг. Количество шагов, суммированных по всем признакам, - это и есть длина дерева.
Например, на дереве 1 признак появился всего один раз. Он сгруппировал таксоны C, D и E, и в данном случае это самый экономный вариант. У этого дерева на данный момент длина 1.
В других деревьях признак должен появляться по крайней мере дважды, их длина - 2. Например, в варианте 3, состояние 1/1 группирует таксоны D и E, но это же состояние есть и у таксона C, поэтому специально для него он появляется еще один раз.
В вариантах 2 и 4 состояние 1/1, кажется, ничего не группирует, но мы тоже должны их рассмотреть. Дело в том, что мы разместили появление признака в данном случае наиболее экономным образом, предположив, что состояние 1/1 было изначально, а у таксонов A и B перешло в состояние 1/0. Но в реальности может быть и иначе, и это будет видно уже в конце, когда филогения будет укоренена и поляризована.
Давайте добавим признак 2, и посмотрим, что произойдет. Однако я разберу это только на примере варианта 1 по признаку 1. Тут у нас получается три дополнительных варианта (но если сложить все варианты по признаку 2, которые получатся из всех 20 вариантов по признаку 1, это будет гораздо больше).
Самый оптимальный вариант - это сгруппировать таксоны D и E c помощью состояния 2/1. Длина дерева при этом получится - 2. В других двух возможных вариантах - 3.
Признак 3 добавит всем по два шага, но ничего не изменит в этой линии.
Однако в линиях, которые пошли от других вариантов по признаку 1, признак 3 может играть существенную роль.
Аналогичная ситуация с признаком 4. Он распространен также, как и признак 2, то есть у таксонов D и E, но он увеличил количество шагов только на 1 в варианте 1, и на 2 - в остальных вариантах.
Осталось обсудить признаки 5 и 6, в которых 5/1 встречается только у таксона D, и 6/1 - только у таксона B.
Заметьте, что эти признаки никогда не группируют вместе никакие таксоны, у них нет такого потенциала. Они одинаково распределяются на всех деревьях (то есть встречаются только один раз у одного таксона). Однако эти признаки тоже сказываются на длине, просто потому что программа включает туда все признаки в матрице, и всегда увеличивают длину на 1. Таким образом, у нас могут быть признаки, не влияющие на топологию, но тем не менее они увеличат результирующую длину вашего дерева.
Продолжение следует.