I. Машинное обучение
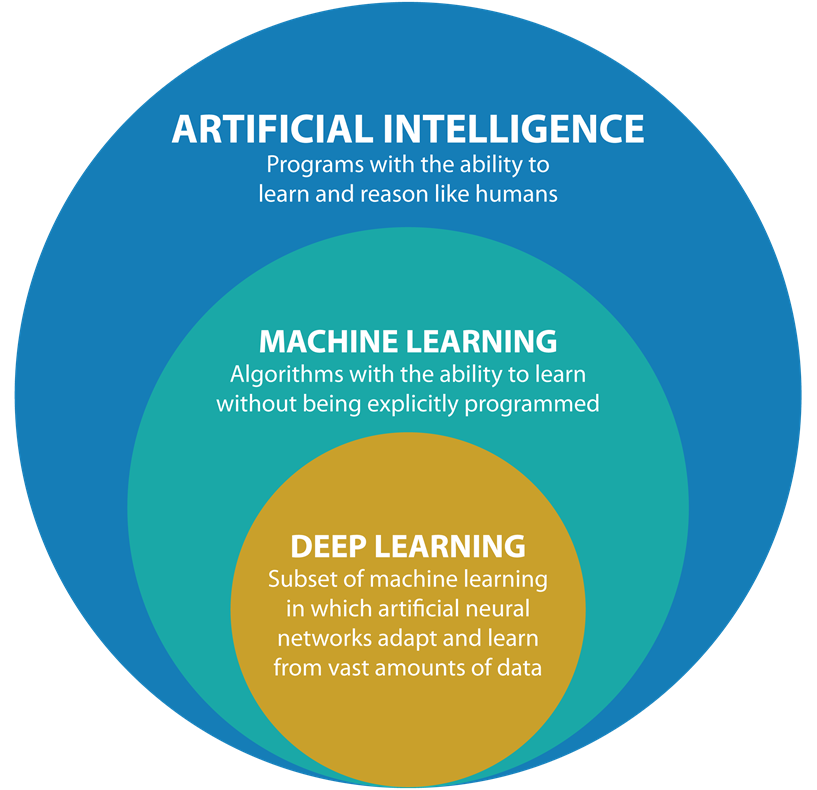
Машинное обучение (machine learning, ML) – класс методов искусственного интеллекта (ИИ, artificial intelligence, AI), характерной чертой которых является не прямое решение задачи, а обучение за счет применения решений множества сходных задач (см. рис. 1).
Типы задач машинного обучения
1) Задача регрессии (regression) – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число (2, 35, 76 и т.д.).
2) Задача классификации (classification) – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (в формате «да» или «нет»).
3) Задача кластеризации (clustering) – распределение данных на группы.
4) Задача уменьшения размерности (dimensionality reduction) – сведение большого числа признаков к меньшему (обычно 2-3) для удобства их последующей визуализации (visualization).
5) Задача выявление аномалий (anomaly detection) – отделение аномалий от стандартных случаев.
II. Нейронная сеть
Нейронная сеть (neural network, NN) – тип процесса машинного обучения, называемый глубоким обучением (deep learning, DL), который использует взаимосвязанные узлы или нейроны (neuron) в слоистой структуре, напоминающей человеческий мозг; создает адаптивную систему, с помощью которой компьютеры учатся на своих ошибках и постоянно совершенствуются.
Искусственные нейроны (artificial neuron) — это программные модули (program module), называемые узлами (nodes), а искусственные нейронные сети (artificial neural network) — это программы или алгоритмы (algorithm), которые используют вычислительные системы (computer-based systems) для выполнения математических вычислений.
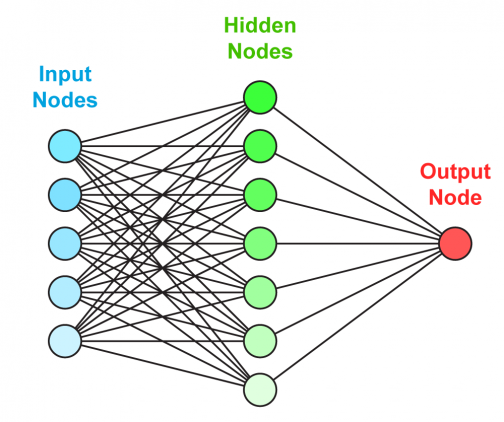
Базовая нейронная сеть содержит три слоя взаимосвязанных искусственных нейронов (см. рис.2):
1) входной слой (input nodes) – информация из внешнего мира поступает в искусственную нейронную сеть из входного слоя; входные узлы обрабатывают данные, анализируют или классифицируют их и передают на следующий слой;
2) скрытый слой (hidden nodes) – получает входные данные от входного слоя или других скрытых слоев (искусственные нейронные сети могут иметь большое количество скрытых слоев), каждый скрытый слой анализирует выходные данные предыдущего слоя, обрабатывает их и передает на следующий слой;
3) выходной слой (output nodes) – дает окончательный результат обработки всех данных искусственной нейронной сетью, может иметь один или несколько узлов. Например, при решении задачи двоичной классификации (да/нет) выходной слой будет иметь один выходной узел, который даст результат «1» или «0». Однако в случае множественной классификации выходной слой может состоять из более чем одного выходного узла.
Глубокие нейронные сети (deep neural network) имеют несколько скрытых слоев с миллионами связанных друг с другом искусственных нейронов. Число, называемое весом (weight), указывает на связи одного узла с другими. Вес является положительным числом, если один узел возбуждает другой, или отрицательным, если один узел подавляет другой. Узлы с более высокими значениями веса имеют большее влияние на другие узлы.
Искусственные нейронные сети могут изучать и моделировать отношения между нелинейными и сложными входными (data input) и выходными данными (data output). Например, могут выполнять следующие задачи:
• обобщать и делать выводы – нейронные сети могут понимать неструктурированные данные (raw data) и делать общие наблюдения без специального обучения; например, нейтронные сети могут определить, что Бакстер-роуд — это место, а Бакстер Смит — это имя человека;
• выявлять скрытые отношения и закономерности – нейронные сети могут более глубоко анализировать необработанные данные и выявлять новые сведения, для поиска которых они, возможно, не были обучены; например, нейронная сеть распознавания образов анализирует потребительские покупки, сравнивая модели покупок множества пользователей, она предлагает новые товары, которые могут заинтересовать конкретного потребителя;
• создавать автономные самообучающиеся системы (self-learning system) – нейронные сети могут обучаться и улучшаться с течением времени в зависимости от поведения пользователя; например, нейронная сеть автоматически запоминает и исправляет или предлагает часто вводимые слова при наборе текста;
• изучать и моделировать крайне изменчивые данные (modularize data), например, нейронные сети могут анализировать финансовые транзакции и помечать некоторые из них для обнаружения мошенничества, также могут обрабатывать сложные данные, которые являются ключом к решению сложных биологических задач – сворачивание белка, анализ ДНК и т. д.
Нейронные сети могут помочь в решении следующих задач:
• машинное зрение (computer vision, CV) – компьютеры могут различать и распознавать изображения так, как это делают люди;
• распознавание речи (voice recognition) – нейронный сети могут анализировать человеческую речь независимо от ее речевых моделей, высоты, тона, языка и акцента;
• обработка естественного языка (natural language processing, NLP) – нейронные сети помогают компьютерам извлекать информацию и смысл из текстовых данных и документов;
• сервисы рекомендаций (discovery engine) – нейронные сети могут отслеживать действия пользователей для разработки персонализированных рекомендаций и т.д.
Типы нейронных сетей:
1) нейронные сети прямого распространения (feed-forward neural network) – обрабатывают данные в одном направлении, от входного узла к выходному узлу, каждый узел одного слоя связан с каждым узлом следующего слоя; используют процесс обратной связи для улучшения прогнозов с течением времени;
2) алгоритм обратного распространения (back-propagation algorithm) – речь идет о данных, протекающих от входного узла к выходному узлу по множеству различных путей в нейронной сети; правильным является только один путь, который сопоставляет входной узел с правильным выходным узлом, чтобы найти этот путь, нейронная сеть использует петлю обратной связи (feedback loop);
3) сверточные нейронные сети (convolutional neural network, CNN) – скрытые слои в сверточных нейронных сетях выполняют определенные математические функции, называемые свертками. Они очень полезны для классификации изображений, поскольку могут извлекать из них соответствующие признаки, полезные для распознавания и классификации. Новую форму легче обрабатывать без потери функций, которые имеют решающее значение для правильного предположения. Каждый скрытый слой извлекает и обрабатывает различные характеристики изображения: границы, цвет и глубину.
III. Способы машинного обучения
1. Обучение с учителем (supervised learning) – система обучается по принципу «стимул-реакция» (stimulus-response).
При данном подходе существует множество реакций – откликов. Между объектами и откликами существует зависимость, которая изначально неизвестна. Задачей обучения с учителем является точное сопоставление объекта необходимому отклику (см. рис. 3).
В процессе обучения набор пар «стимул-реакция» называется «обучающей выборкой» (training set). Учителем в данной ситуации может выступать как сама выборка, так и человек.
Этот способ оптимален, если есть понимание, чему можно научить машину. Нужно познакомить компьютер с огромной обучающей выборкой данных и варьировать параметры до тех пор, пока не получатся на выходе ожидаемые результаты. Затем можно уточнить, чему научилась машина, заставив ее спрогнозировать результат для контрольных данных, с которыми компьютер еще не сталкивался.
Обучение с учителем может использоваться для решения следующих задач:
• задача регрессии (regression problem) – если требуется спрогнозировать непрерывные значения, например, попытаться спрогнозировать стоимость дома или погоду на улице в градусах;
• задача классификации (classification problem) – если требуется спрогнозировать дискретные значения (distinct states), например классифицировать что-либо по категориям: вопрос «будет ли человек делать покупку», имеет ответ, который попадает в две конкретные категории: да или нет (число допустимых ответов конечно);
• задача прогнозирования (forecasting problem) – ответы указывают на поведение процесса в будущем.
Обучение с учителем можно использовать при определении финансового риска частных лиц и организаций на основе имеющихся сведений о прошлой финансовой активности, можно неплохо прогнозировать покупательское поведение с учетом прежних закономерностей.
2. Обучение без учителя (unsupervised learning) – система обучается выполнять поставленную задачу без вмешательства эксперта. Данный подход применяется только для задач, в которых известны описания множества объектов (обучающей выборки), и требуется обнаружить внутренние зависимости, существующие между объектами (см. рис. 4). Примером этого может быть группировка клиентов на основе их прошлых покупок.
Обучение без учителя может использоваться для решения следующих задач:
• задача кластеризации (clustering problem) – поданные на вход группы объектов требуется разбить на непересекающиеся подмножества – кластеры (clusters), таким образом, чтобы объекты из одного кластера были схожи между собой и отличимыми от объектов из другого кластера; так определяются связи между элементами данных, и на основании этих отношений выявляются связи между людьми и организациями в физическом или виртуальном мире (вариант особенно полезен компаниям, которым нужно, например, объединить данные из разнородных источников или по различным структурным подразделениям, чтобы построить общую картину клиентуры);
• задача поиска ассоциативных правил (association rule learning) – правила вида «если…, то…»;
• задача заполнения пропущенных значений (filling missing values) – заполнение пропущенных значений в различных множествах, используя их средние характеристики;
• задача уменьшения размерности (dimensionality reduction) – минимизация потери информации с уменьшением размерности обозначающих ее символов;
• задача визуализации данных (data visualization) – представление многомерных данных в виде двумерном пространстве.
Обучение без учителя также можно использовать для анализа тональности высказываний (sentiment analysis), чтобы определять эмоциональное состояние людей на основе их постов в социальных сетях, сообщений электронной почты и других записей. В компаниях, специализирующихся на финансовых услугах, с помощью обучения без учителя все чаще оценивают уровень удовлетворенности клиентов.
3. Обучение с частичным привлечением учителя (semi-supervised learning, SSL) – гибрид обучения с учителем и без, для тренировки используются небольшое количество размеченных данных (labeled data) и большое количество неразмеченных данных (unlabeled data). Разметив небольшую часть данных, учитель дает машине понять, каким образом кластеризовать (clusterize) остальное.
Обучение с частичным привлечением учителя можно применять в случаях, когда есть готовые наборы частично размеченных данных, что характерно для крупных предприятий. В Amazon, например, улучшили способности цифрового ассистента Alexa понимать естественный язык, обучая алгоритмы искусственного интеллекта на сочетаниях размеченных и неразмеченных данных. Благодаря этому удалось повысить точность ответов Alexa.
4. Обучение с подкреплением (reinforcement learning) – испытуемая система обучается, взаимодействуя с экспериментальной средой (environment). Откликом среды являются сигналы подкрепления (reinforcement signal). Учителем является среда или ее модель. Система воздействует на среду и наоборот. Данную конструкцию рассматривают как единое целое (см. рис. 5).
При обучении с подкреплением машине позволяют взаимодействовать с окружением (например, сбрасывать бракованную продукцию с конвейера в корзину) и «вознаграждают», когда она правильно выполняет задание. Автоматизировав подсчет вознаграждений, можно дать возможность машине обучаться самостоятельно.
Одно из применений обучения с подкреплением — сортировка товаров в розничных магазинах. Некоторые продавцы экспериментируют с роботизированными системами сортировки предметов одежды, обуви и аксессуаров. Роботы, используя обучение с подкреплением и глубинное обучение, определяют, насколько сильно нужно сдавить предмет при хватании и какой хват будет наилучшим.
5. Глубинное обучение (deep learning) – совокупность способов машинного обучения (с учителем, с частичным привлечением учителя, без учителя, с подкреплением), основанных на обучении представлениями (representation learning), а не специализированных алгоритмах под конкретные задачи (см. рис. 6).
При глубинном обучении частично имитируются принципы обучения людей – используются нейронные сети для все более подробного уточнения характеристик набора данных.
Глубинные нейронные сети применяются для ускорения скрининга больших объемов данных при поиске лекарственных средств. Такие нейросети способны обрабатывать множество изображений за короткое время и извлечь больше признаков, которые модель в конечном счете запоминает.
6. Трансдуктивное обучение (transductive inference) – обучение с частичным привлечением учителя, когда прогноз предлагается делать только для прецедентов из текстовой выборки.
Трансдуктивное обучение может быть применено при распознавании речи – создаются последовательности текста с последовательностями аудио.
7. Многозадачное обучение (multi-task learning) – одновременное обучение группе взаимосвязанных задач, для каждой из которых задают свои пары «ситуация, требуемое решение».
Одно из применений многозадачного обучения – спам-фильтр, который можно рассматривать как отдельные, но связанные задачи классификации для разных пользователей.
8. Многовариантное обучение (multiple-instance learning) – обучение, когда прецеденты могут быть объединены в группы, в каждой из которых для всех прецедентов имеется «ситуация», но только для одного из них (неизвестно какого) имеется пара «ситуация, требуемое решение» (см. рис. 7).
IV. Основные алгоритмы моделей машинного обучения
1. Линейная регрессия (linear regression, LR) – модель зависимости переменной x от одной или нескольких других переменных (факторов, регрессоров, независимых переменных) с линейной функцией зависимости.
Линейная регрессия относится к задаче определения «линии наилучшего соответствия» (line of best fit) через набор точек данных (data point) и стала простым предшественником нелинейных методов, которые используют для обучения нейронных сетей.
Цель линейной регрессии — поиск линии, которая наилучшим образом соответствует точкам.
Для оценки регрессионной модели используется метод наименьших квадратов (ordinary least squares method, OLS method).
Линейная регрессия может быть применена, когда требуется построить какую-либо зависимость, например, цены нарезного хлеба от времени.
2. Логистическая регрессия (logistic regression) – способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы; используется для задач бинарной классификации (binary classification) (задачи, в которых на выходе получаем один из двух классов).
Логистическая регрессия похожа на линейную тем, что в ней тоже требуется найти значения коэффициентов для входных переменных (input variables). Разница заключается в том, что выходное значение (output value) преобразуется с помощью нелинейной или логистической функции (logistic function).
Логистическая функция выглядит как большая буква S и преобразовывает любое значение в число в пределах от 0 до 1 (см. рис. 9).
Логистическая регрессия используется, когда нужно отнести образец к одному из двух классов. Например, чтобы узнать, как кассовые сборы фильма зависят от бюджета, который вложили в его производство. Если классов больше, чем два, то лучше использовать линейный дискриминантный анализ.
3. Линейный дискриминантный анализ (linear discriminant analysis, LDA) – состоит из статистических свойств данных, рассчитанных для каждого класса (см. рис. 10).
Для каждой входной переменной это включает:
• среднее значение для каждого класса;
• дисперсию, рассчитанную по всем классам.
Предсказания производятся путём вычисления дискриминантного значения для каждого класса и выбора класса с наибольшим значением.
4. Дерево принятия решений (decision tree) – метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность (см. рис. 11).
Листовые узлы (leaf nodes) — это выходная переменная, которая используется для предсказания. Предсказания производятся путём прохода по дереву к листовому узлу и вывода значения класса на этом узле.
Деревья быстро обучаются и делают предсказания. Кроме того, они точны для широкого круга задач и не требуют особой подготовки данных.
Среди применений дерева решений — платформы управления знаниями для клиентского обслуживания, прогнозного назначения цен и планирования выпуска продукции.
В страховой компании дерево решений поможет выяснить, какие виды страховых продуктов и премий лучше задействовать с учетом возможного риска. Используя данные о местонахождении и сведения о страховых случаях с учетом погодных условий, система может определять категории риска на основании поданных требований и затраченных сумм. Затем, используя модели, система будет оценивать новые заявления о страховой защите, классифицируя их по категории риска и возможному финансовому ущербу.
5. Наивный Байесовский классификатор (naive Bayes classifier) – простой вероятностный классификатор, основанный на применении теоремы Байеса со строгими предположениями о независимости – теории вероятностей (probability theory).
Наивный Байес называется наивным, потому что алгоритм предполагает, что каждая входная переменная независимая.
Модель состоит из двух типов вероятностей, которые рассчитываются с помощью тренировочных данных (см. рис. 12):
• вероятность каждого класса;
• условная вероятность для каждого класса при каждом значении x.
Данный алгоритм весьма эффективен для целого ряда сложных задач вроде классификации спама или распознавания рукописных цифр.
6. К-ближайших соседей (K-nearest neighbors, KNN) – набор тренировочных данных.
Предсказание для новой точки делается путём поиска K ближайших соседей в наборе данных и суммирования выходной переменной для этих K экземпляров (см. рис. 13).
Определение сходство между экземплярами данных: если все признаки имеют один и тот же масштаб (например, сантиметры), то самый простой способ заключается в использовании евклидова расстояния (Euclidian distance) — числа, которое можно рассчитать на основе различий с каждой входной переменной.
Алгоритм К-ближайших соседей может быть применен, например, при оценки возможности просрочки платежа заемщиком банка.
7. Сети векторного квантования (learning vector quantization, LVQ) – набор кодовых векторов, которые выбираются в начале случайным образом и в течение определённого количества итераций адаптируются так, чтобы наилучшим образом обобщить весь набор данных. После обучения эти вектора могут использоваться для предсказания так же, как это делается в KNN. Алгоритм ищет ближайшего соседа (наиболее подходящий кодовый вектор) путём вычисления расстояния между каждым кодовым вектором и новым экземпляром данных. Затем для наиболее подходящего вектора в качестве предсказания возвращается класс (или число в случае регрессии). Лучшего результата можно достичь, если все данные будут находиться в одном диапазоне, например от 0 до 1 (см. рис. 14).
В сетях векторного квантования, в отличие от KNN, не нужно хранить весь тренировочный набор данных.
8. Метод опорных векторов (support vectors) – набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость (hyperplane) с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп (см. рис. 15).
Гиперплоскость — линия, разделяющая пространство входных переменных. В методе опорных векторов гиперплоскость выбирается так, чтобы наилучшим образом разделять точки в плоскости входных переменных по их классу: 0 или 1. В двумерной плоскости это можно представить как линию, которая полностью разделяет точки всех классов. Во время обучения алгоритм ищет коэффициенты, которые помогают лучше разделять классы гиперплоскостью.
Расстояние между гиперплоскостью и ближайшими точками данных называется разницей (difference). Лучшая или оптимальная гиперплоскость, разделяющая два класса, — это линия с наибольшей разницей. Только эти точки имеют значение при определении гиперплоскости и при построении классификатора. Для определения значений коэффициентов, максимизирующих разницу, используются специальные алгоритмы оптимизации (optimization algorithm).
Метод опорных векторов весьма эффективен для распознавания отдельных рукописных символов, автоматической классификации веб-страниц или текста, распознавания говорящего, обнаружения лиц и т.д.
9. Метод ансамблей (ensemble methods) – базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования.
Дополнительные алгоритмы метода ансамблей:
• бустинг (boosting) – преобразует слабые модели в сильные посредством формирования ансамбля классификаторов;
• бэггинг (bagging) – собирает усложнённые классификаторы, при этом параллельно обучая базовые (см. рис. 16);
• корректирование ошибок выходного кодирования (output encoding).
Среди применений метода ансамблей – распознавание речи, эмоций на лице, выявление мошенничества, такого как отмывание денег, подозрительной активности в банковских операциях в системах кредитных карт.
10. Метод главных компонентов (Principal Component Analysis, PCA) – статистическая операция по ортогональному преобразованию (orthogonal transformation), которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонентов – значений, которые линейно не коррелированы (см. рис. 17).
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией).
Данный метод применяется во многих областях, в том числе в эконометрике, биоинформатике, обработке изображений, для сжатия данных, в общественных науках.
11. Анализ независимых компонентов (independent component analysis, ICA) – статистический метод, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных (multifactor data). Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами (non-Gaussian signals) (см. рис. 17).
Данный алгоритм помогает выделить независимые компоненты из смеси звуков, сигналов. После разделения записанного сигнала появляется возможность удалить из него ненужные элементы – шум голосов, музыку или моргание и др. Это позволяет очистить запись от лишних данных или же выделить конкретную информацию.
Источники:
1) Веб-сайт: https://www.osp.ru/cio/2018/05/13054535
2) Веб-сайт: https://ru.wikipedia.org/wiki/Машинное_обучение
3) Веб-сайт: https://topuch.ru/obuchenie-s-uchitelem/index.html
4) Веб-сайт: https://aws.amazon.com/ru/what-is/neural-network/
5) Веб-сайт: https://habr.com/ru/post/427867/
6) Веб-сайт: https://neurohive.io/ru/osnovy-data-science/linejnaja-regressija/
7) Веб-сайт: https://tproger.ru/translations/top-machine-learning-algorithms/
Автор: Александра Поверина, IT-переводчик
Материал подготовлен для телеграм-канала по ИТ-переводу https://t.me/alliancepro