Легко понять, почему компании, работающие с данными, используют аналитику самообслуживания; когда люди имеют автономный доступ к аналитическим данным, более эффективные решения могут приниматься быстрее — по крайней мере, теоретически. На команды BI ложится роль посредников между необработанными данными и полученными на их основе аналитическими данными. Из бесед с этими командами следует, что это сопряжено с некоторыми довольно серьезными проблемами.
В настоящее время организации переполнены требовательными "клиентами" данных, которые привыкли полагаться на данные при выполнении своей работы. Обеспечение их безопасности при одновременном соблюдении других соображений, таких как конфиденциальность и безопасность, может оказаться непростой задачей, особенно в условиях ужесточения регулирования конфиденциальности и растущей угрозы кибератак.
“Действовать быстро и ломать вещи” - это не так уж круто, когда речь идет об утечке конфиденциальных и персональных данных, или неправильном представлении цифр совету директоров.
Каков ответ? Компании всех размеров, включая стартапы и стартапы, стремятся внедрить ту или иную форму управления данными.
Управление данными: максимальный доступ к высококачественным данным, необходимым заинтересованным сторонам для повышения ценности бизнеса, при минимизации рисков.
В настоящее время инструменты, которые пытаются решить эти проблемы, ориентированы на предприятия; комплексные функции, высокая цена, длительная настройка и много обслуживания. Эти инструменты на самом деле не подходят для целей быстрого масштабирования, компаний, испытывающих нехватку времени, и часто оказываются бесполезными, когда дело доходит до решения реальных, "еще вчера нужно было", проблем.
Демократия данных без управления данными — анархия данных?
Переход к самостоятельной аналитике это часто называют ‘демократизацией данных’. Некоторые компании внедрили каталоги данных для продвижения этой культуры, делая ресурсы данных доступными для поиска по группам и отделам и предоставляя дополнительные условия, такие как чувствительность и качество. Каталоги корпоративных данных существуют уже некоторое время, но мы также видели, как компании, работающие с данными, такие как Lyft (Amudsen), LinkedIn (DataHub) и Netflix (Metacat), создают свои собственные решения с открытым исходным кодом, не найдя на рынке ничего, что отвечало бы их потребностям.
Итак, какова связь между управлением данными и демократией данных? Если провести аналогию, то в любой демократии роль правительства заключается в создании правил и структур, необходимых для обеспечения ее выживания, и то же самое можно сказать об управлении данными. Без управления вы получаете ‘анархию данных’; бесплатно для всех и практически без контроля.
Даже при простой настройке, состоящей из хранилища данных (например, Snowflake) и инструмента визуализации данных (например, незнакомый нам пока Looker), без надлежащего управления ситуация может быстро выйти из-под контроля. Неиспользуемые и похожие версии таблиц и панелей мониторинга могут загромождать среду, вызывая недостаток доверия, без единого источника достоверности, а также увеличивая затраты на хранение и вычисления.
Отслеживание того, какие столбцы и панели мониторинга содержат конфиденциальные данные, и кто имеет к ним доступ, становится серьезной проблемой. Когда изменения приводят к поломке важной информационной панели, инженеры BI могут ожидать потока сообщений от напряженных коллег.
С чего начать автоматизацию управления данными? узнайте и фиксируйте свои потоки данных.
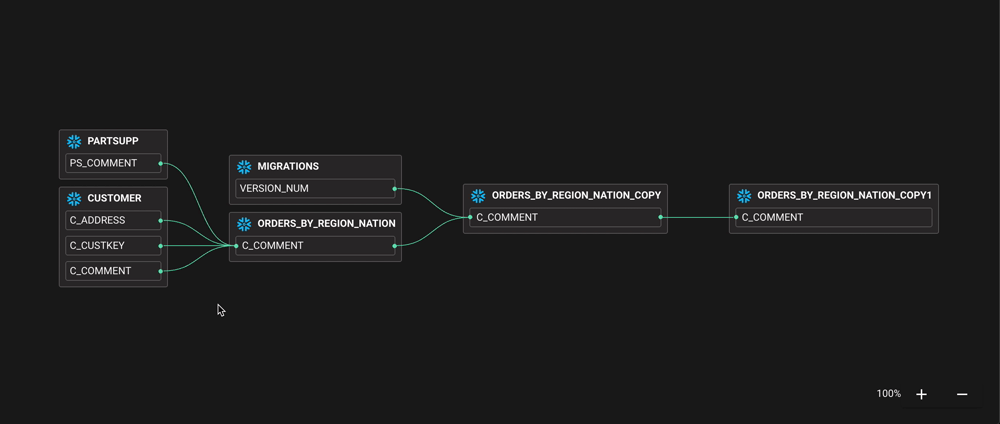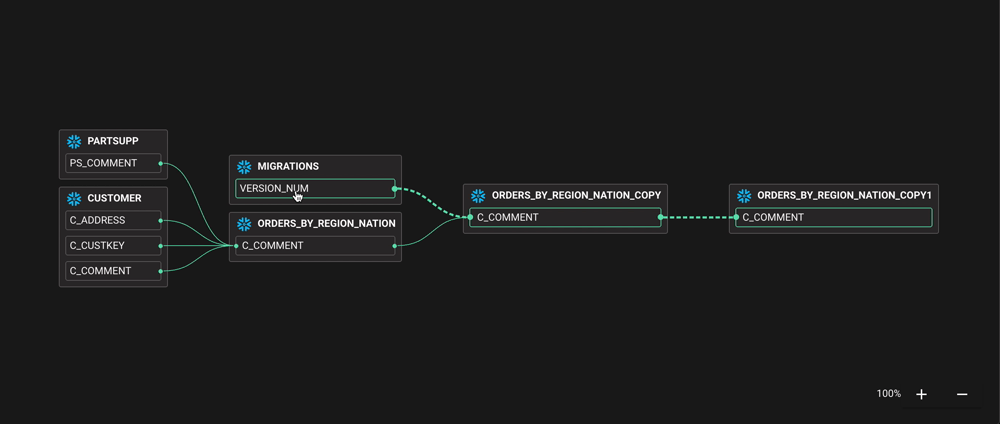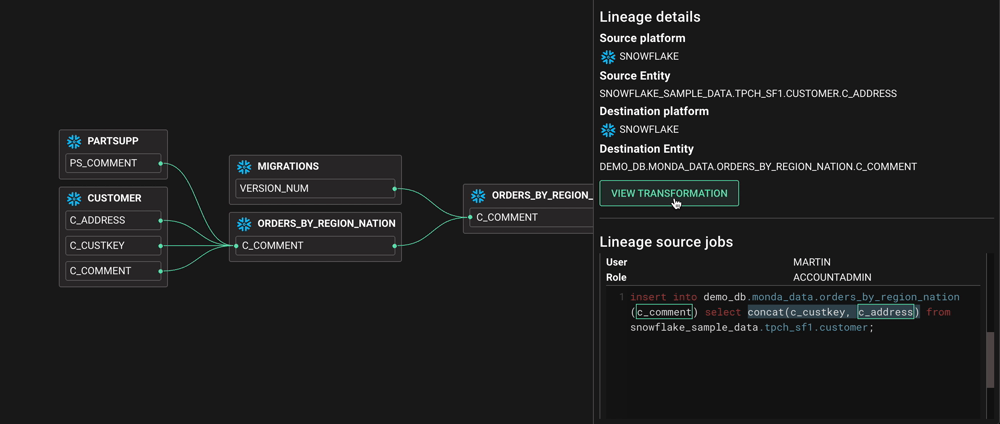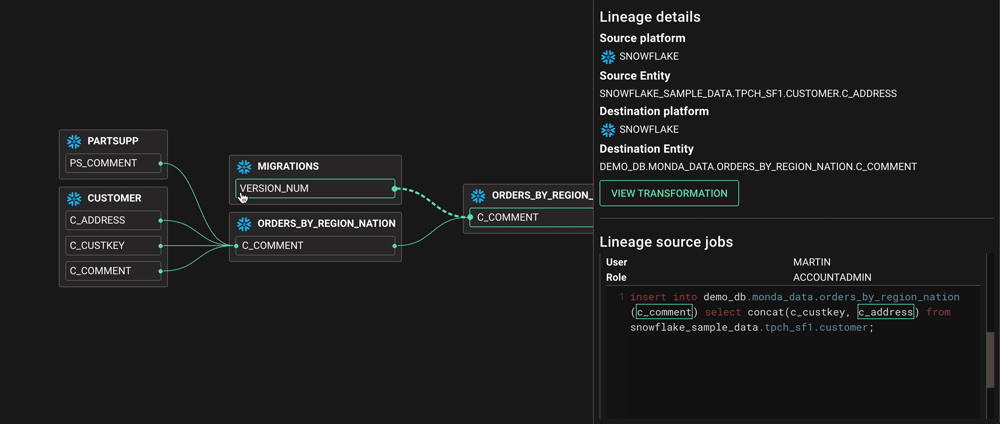
Для эффективной работы команд BI им необходимо понимать, как передаются данные. Например, они могут захотеть удалить столбец, который больше не является актуальным. Однако это может привести к нарушению конвейера ETL или информационной панели уровня C. Без инструмента, который может выполнять анализ воздействия, командам BI приходится выбирать между кропотливым составлением карт потоков данных вручную, внесением изменений и надеждой на лучшее или просто полным отказом от изменений!
В большинстве случаев команде BI не нужен общекорпоративный каталог корпоративных данных со всеми прибамбасами - им нужно понимать, как передаются данные, куда они поступают и кто их использует. В каталогах корпоративных данных такие важные функции, как межсистемная и линейная привязка данных на уровне столбцов, либо отсутствуют, либо включены только в цены верхнего уровня. Каталоги данных с открытым исходным кодом стремятся к этому, но это технически сложная проблема (как мы знаем по опыту!).
Конечно, есть чему поучиться у каталогов данных и сообщества разработчиков с открытым исходным кодом - фактически, любой полезный продукт с метаданными нуждается в каталоге в своей основе. Поскольку потоки данных можно рассматривать как граф с ребрами между узлами, очевидно, что вы не можете говорить о потоках без индекса объектов данных, таких как таблицы, столбцы и панели мониторинга. Поток данных происходит на временной шкале по мере выдачи инструкций или заданий, что приводит к перемещению данных между объектами. Это становится по-настоящему эффективным, когда объекты данных помечены, например, местоположением или чувствительностью. Внезапно мы можем начать автоматически отслеживать, откуда персональные данные поступают на информационные панели и в специальные запросы.
Чтобы по-настоящему понимать потоки данных, к данным об использовании следует относиться как к первоклассному гражданину. Запросы, задания и панели мониторинга должны быть проанализированы и структурированы. Данные об использовании - это то, что делает продукт самоуверенным. Это аналогично тому, как Amazon выдает вам предложения на основе истории ваших поисков и покупок.
До нас дошло, что сама передача данных - это вовсе не проблема; это технология. Вопрос: является ли для вас проблемой происхождение данных? на самом деле ничем не отличается от вопроса, являются ли graph баз данных проблемой для вас? Для нас data lineage - это структура данных в реальном времени, которая отображает зависимости между столбцами, таблицами, панелями мониторинга, заданиями и людьми. Это такой же набор данных, как и любой другой, и схематически это только один из способов его представления.
Одна из причин, по которой современный инструментарий только поцарапал поверхность проблемы управления данными, когда дело доходит до цепочки данных, заключается в том, что он был частью нисходящего подхода к управлению данными. Технология (и решения) были навязана инженерам по обработке данных, иногда создавая больше головной боли, чем решая. Мы обнаружили, что в сообществе данных мало любви к корпоративным каталогам данных.
На самом деле именно инженеры по обработке данных каждый день сталкиваются с проблемами обеспечения надлежащего управления. Благодаря правильному пониманию технических вариантов использования, лучшие практики управления данными могут быть интегрированы в их рабочие процессы, вызывая радость вместо страха. Давайте теперь обсудим некоторые из основных вариантов использования data lineage, которые возникают в наших беседах с инженерами по обработке данных, прежде чем вернуться к главному вопросу о том, является ли диаграмма лучшим способом их решения.
Анализ воздействия
Без использования данных о происхождении внесение изменений в инфраструктуру данных (даже в относительно простой среде) было названо огромной проблемой. Такая невинная вещь, как добавление столбца в таблицу, может иметь серьезные последствия для последующего использования. В одной компании, с которой мы разговаривали, это привело к тому, что показатель, используемый в финансовой отчетности, отсутствовал в течение нескольких месяцев (ого!). Чтобы попытаться избежать этого, обычно вручную проверяются журналы SQL, базы данных Airflow, файлы LookML и файлы Github. Это не только невероятно утомительно и является огромной тратой времени высококвалифицированного инженера, но и несовершенно. Тревожное ожидание некоторой слабой реакции после внесения изменений является нормой. Или, что еще хуже, финансовый директор появляется у вашего стола!
Из наших бесед мы даже начали классифицировать разных персонажей среди инженеров по обработке данных.
‘Картограф’(MAPPER) тщательно проверяет журналы и отображает нижестоящие зависимости, прежде чем вносить какие-либо изменения.
‘Ловкач’(DODGER) избегает внесения изменений без крайней необходимости.
"Надеющийся" (HOPER) настолько загружен другими задачами, что они полагаются на то, что у них в голове, и надеются на лучшее. Как вы можете видеть из наших рейтингов, ни один из них не идеален:
Отслеживание проблем
Большинство вопросов (и жалоб), связанных с данными, адресованы инженерам по обработке данных. Почему эта панель управления сломана? Где самые последние данные? Можете ли вы проверить, верен ли этот показатель? Даже после выполнения анализа воздействия могут возникать ошибки в конвейере данных. Потребитель данных часто обнаруживает их, и расследование зависит от инженера по обработке данных.
Другой слой к этому заключается в том, что часто после изучения данных инженеры вообще не находили ошибок. Например, маркетолог, который считал, что метрика отсутствует, когда кампания просто не показала результатов. Или аналитик, запрашивающий самые последние данные до запуска запланированного задания. Со многими потребителями данных связана большая ответственность.
Для инженеров по обработке данных нет ничего сложного в том, чтобы быстро расставлять приоритеты в этих специальных задачах наряду с основной работой без ущерба для безопасности и конфиденциальности. Без данных о происхождении отслеживание проблемы является исключительно ручным и в основном достигается за счет сочетания предварительных знаний и догадок; особый кошмар для новичков.
Очистка хранилищ данных (DATA ASSETs)
Когда дело доходит до среды аналитики, инженеры по обработке данных постоянно заявляли о недостаточной осведомленности о том, какие ресурсы данных используются. Без регулярного внимания неиспользуемые таблицы и панели мониторинга могут быстро накапливаться.
Таблицы "одноразового использования" для нерегламентированного анализа появляются быстрее, чем их можно заметить и удалить, что немного похоже на игру в "Вжик-моль" с завязанными глазами. Информационные панели, созданные для кампаний, часто имеют ограниченный жизненный цикл, но кому придет в голову удалять их, когда они перестанут быть полезными?
Вот почему люди должны быть включены в любой график происхождения. Перед удалением столбца или таблицы инженеры по обработке данных должны знать не только, какие ресурсы данных зависят от них, но и какие люди. В хранилище данных это могут быть специальные запросы, в средствах просмотра инструментальной панели BI. Этот контекст помогает инженерам по обработке данных очистить среду аналитики и почувствовать себя в полном дзен.
В рамках этой категории мы определили несколько различных вариантов использования:
- Периодическая очистка: подобно весенней уборке, инженеры по обработке данных хотят избавиться от ‘устаревших’ ресурсов за один раз.
- Поиск ресурсов: специалист по обработке данных хочет знать, используется ли конкретный ресурс данных и как это использование изменилось с течением времени.
Доверие к данным
Помощь потребителям данных в понимании того, могут ли они доверять данным, обычно обрабатывается инженерами по обработке данных на специальной основе. Общие вопросы здесь могут включать в себя: как вычисляется это поле? Должен ли я использовать поле ЗНАЧЕНИЕ или ЦЕНА? Откуда берутся эти данные? Такого рода вопросы чаще всего возникают при работе с новыми наборами данных.
Каталоги данных с открытым исходным кодом, такие как Amundsen (Lyft) и DataHub (Linkedin), были основаны на том факте, что в них была масса полезных данных, которые не использовались, потому что люди не могли их найти. Но новые наборы данных не так полезны, если им нельзя доверять.
Каталоги данных решают эту проблему с помощью метаданных (владельцы, описания, рейтинги и т.д.). Но источник данных, способ вычисления полей и то, как они используются, регулярно рассматриваются как наиболее важные факторы доверия. Данные о происхождении, безусловно, могут помочь trust стать более самообслуживаемыми и снизить нагрузку на инженеров по обработке данных для выполнения этой роли.
Отслеживание личных данных
Инженеры по обработке данных описывают конфиденциальность как назойливую, вызывающую стресс проблему, с которой им приходится учиться жить. Большая часть работы, необходимой для соблюдения последних, более строгих правил конфиденциальности, таких как GDPR в Европе и CCPA в СЩА, ложится на их плечи.
В современной среде обработки данных конфиденциальные данные будут (по замыслу) поступать из источника во множество различных таблиц, панелей мониторинга, записных книжек, электронных таблиц, моделей машинного обучения и многого другого. Вручную отслеживать, где заканчивается PII, со 100% точностью практически невозможно.
Возьмем конкретный пример: если клиент воспользуется своим правом на удаление в соответствии с GDPR, как бы вы отследили и удалили все его данные? Учитывая штрафы и риск для репутации, нет места для ошибок. Технология Lineage может быть чрезвычайно ценной здесь, отслеживая конфиденциальные данные, где бы они ни находились, даже в самых темных уголках хранилища данных.
Будущее передачи данных
Для нас совершенно очевидно, что при применении технологии передачи данных к каждому из этих вариантов использования отдельно решение будет другим. Попытки решить их все сразу на диаграмме, как правило, выглядят как горсть спагетти, брошенных в стену; что, конечно, ничего не решает.
Давайте увеличим первый вариант использования, который мы рассмотрели: анализ воздействия. Как правило, инженеры по обработке данных хотят знать, каковы последующие последствия выполнения этого оператора SQL? Итак, является ли переход от вашего редактора запросов, поиск по каталогу данных и попытка определить влияние сложной диаграммы происхождения данных оптимальным решением? Вы, вероятно, поняли из формулировки вопроса, что мы так не думаем!
Поскольку автоматизация становится все более распространенной во всех аспектах разработки программного обеспечения, естественно, что разработка данных использует одни и те же методы; от DevOps до DataOps. Высококачественные исходные данные позволят использовать аналогичные варианты в разработке данных. Компании уже проводят тесты для конвейеров данных, а также тестирование качества, и мы видим здесь некоторые интересные возможности, когда дело доходит до анализа воздействия.
Изолируя нижестоящие зависимости для данного столбца, мы в некоторой степени упростили анализ влияния в нашей бета-версии. Мы рады, что это оказалось полезным, хотя нам еще предстоит пройти определенный путь для реализации целей, изложенных в этой статье. Но с сообществом инженеров по обработке данных, постоянно продвигающих наше мышление вперед, мы настроены оптимистично, что сможем достичь этого.
В подавляющем большинстве случаев человеческим компонентом управления данными является инженер по обработке данных. Технология передачи данных обладает потенциалом для создания целого ряда функций, которые дополняют и даже заменяют части их рабочего процесса, позволяя им сосредоточить свое время на деятельности по созданию ценности. Управление данными становится все более сложным, но мы верим, что инструменты, основанные на вариантах использования, основанные на технологии lineage, помогут инженерам по обработке данных справиться с этой задачей.