Привет! В этой статье мы поговорим о функционале и том технологическом стеке, к которому мы пришли сейчас.
Как всегда начнем с истории и накопленного опыта...
Когда мы только начинали выгружать данные для применения их в отчетности в первых проектах (2014-15гг.), логичным было просто копировать поведение других ETL-инструментов, которые в тот момент времени уже существовали на западном рынке. Использовать их мы не могли, в них не хватало источников, которые были необходимы на нашем рынке. Поэтому мы и решили делать собственные выгрузки, которые будут отвечать нашим интересам. Оглядываясь на существующие аналоги ETL-сервисов и, смещая акцент на наш рынок, мы "запилили" десятка два коннекторов… прежде чем поняли, что что-то пошло не так.
В то время мы сами уже активно использовали Power BI для создания отчетов, поэтому предположили что функционала, заложенного в PBI, будет достаточно, чтобы выгруженные нами данные привести к подходящему для работы виду. На практике же оказалось все не так просто. Тогда в основу мы заложили более популярный и привычный нам принцип OLTP и работать с такими данными было практически невозможно. Обработка таких таблиц в Power Query усложнялась в десятки раз, а при росте объема это приводило к непредсказуемым последствиям. И даже после таких преобразований не получалось собрать нормальную модель, приходилось реализовывать сложные вычисления на DAX.

После непродолжительного мучения мы решили полностью менять подход к тому, что делаем. Переключились на методологию OLAP и
сконцентрировали внимание на стеке Microsoft, начали методочино прорабатывать все моменты от сбора данных до визуализации. В конечном счете мы “сломали старый заборчик и построили новый”: структура всех выгрузок была полностью изменена и в основу них была положена "звезда", PostgreSQL мы заменили на SQL Server и, как результат, "переехали" в Azure, минимизировали обработку данных на PQ и начали более детально прорабатывать модели, что в значительной степени упростило написание мер.
К запуску сервиса myBI Connect мы подошли уже в полной мере подготовленными, успели набить шишек и выгрузке и в работе с этими данными, чтобы предоставить пользователям наиболее оптимальный и рабочий функционал: облако Azure, СУБД MS SQL для удобной работы вместе с Power BI.
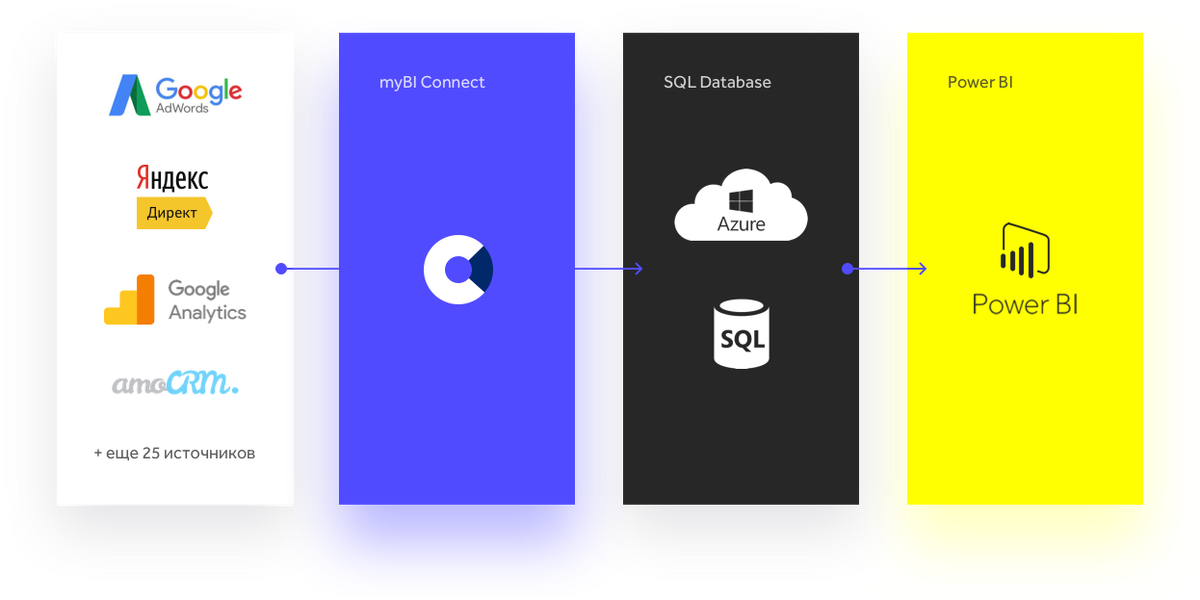
В таком виде мы работали и развивались на протяжении нескольких лет и даже можно сказать, что успешно;). Конечно, периодически мы пытались рассматривать альтернативные инструменты для работы с данными, но это не вызывало серьезного интереса от пользователей, и мы возвращались к Power BI... пока с использованием Microsoft не возникли определенные трудности, после чего мы серьезно задумались над тем, чтобы найти альтернативу этому стеку.
Под "стеком" в данном случае мы имеем в виду всю цепочку инструментов, которые необходимы для достижения конечного результата. В общих чертах его можно представить в виде нескольких укрупненных блоков:
- первоначальный сбор данных;
- выгрузка данных с помощью API из источника;
- хранение собранных данных;
- преобразование данных под конкретную задачу;
- разработка визуализаций и отчетов;
- предоставление доступа к отчету пользователям.
Нетрудно догадаться что myBI Connect в данном случае закрывает только 2-й пункт и формально 3-й, а остальные последующие блоки легко собирались на основе “экосистемы”:
- первоначальный сбор данных! На всякий случай напомню, что если вы не настроили корректный сбор данных в первоисточнике (CRM, GA или где-то еще), то и выгрузка, отчеты и остальное бесполезно;
- третий блок реализуется на основе Azure в котором очень удобно работать с базами на SQL Server, наш сервис же просто “нарезает” базы и предоставляет их пользователям. ;
- учитывая что Power BI Desktop - это полноценный self-service BI, то четвертый и пятый блоки вполне могут быть реализованы на нем;
- за шестой блок отвечает онлайн-сервис Power BI.
Кроме этого необходимо отметить и тот факт, что использование продуктов от Microsoft позволяет реализовать достаточно бюджетное решение, которое вполне будет доступно и малому бизнесу. Поэтому альтернативный стек должен закрывать задачи из блоков со второго по пятый и быть не очень дорогим.
Изучив ситуацию с локальными BI системами у нас чуть было не опустились руки... так как найти какую-либо альтернативу Microsoft нам не удалось. Да, у нас существуют различные продукты для работы с данными, но решения, которое могло бы в полной мере заменить стек Microsoft - нет. У всех продуктов есть какие-либо ограничения: либо они специализируются только на обработке данных, либо только на визуализации, но большая часть из них выглядит, как кот в мешке, которого умеют превращать в конечный продукт только разработчики этих решений.
Пока мы искали решение, мы пообщались с одним знакомым экспертом и это подтолкнуло нас посмотреть на ситуацию немного с иной стороны: почему нам необходимо искать подходящий стек или собирать его из числа коммерческих продуктов, возможно, есть смысл посмотреть на open source инструменты, среди которых, могут быть подходящие?
Эта идея импонировала нам еще и тем, что мы уже на протяжении нескольких лет ходили вокруг да около подобных инструментов и даже имели наработки с их интеграциями почти со всеми, но раньше этот пазл все не складывался, мы не планировали формировать из них полноценный стек, а по отдельности они были менее интересны и понятны для конечного пользователя сервиса.
После некоторых раздумий мы решили попробовать, несмотря на то что весь груз разработки ложится на нас. В тоже время, это сулило дать нам значительную свободу - мы можем реализовать все так как мы хотим, а не подстраиваться под сторонние инструменты, с которыми, как оказалось, достаточно сложно долго договориваться, даже когда все сделано по их требованиям.
В результате мы сформировали такой стек:
- myBI Connect - сбор данных и формирование единого хранилища;
- dbt - дополнительная обработка, по мере ее необходимости;
- Cube.js - доступ к данным;
- Vega-Lite - визуализация данных.
Сразу хотелось бы попросить не кидать в нас камнями;) Мы не сошли с ума и не пытаемся сделать полноценный self-service BI для замены Power BI или какого-либо иного инструмента. Мы остаемся ETL-сервисом, но расширение функционала сервиса это нормальный процесс, а наличие под рукой полного набора инструментов, хоть и не очень сложного, это хорошая подушка безопасности на черный день.
Далее мы обзорно рассмотрим для чего нужны эти инструменты, как они могут взаимодействовать друг с другом и что это дает пользователям. Рекомендуем дочитать до конца там еще и скринкаст, а сейчас небольшой спойлер :) или пример -
Детально описывать функции myBI Connect мы не будем сейчас, чтобы не повторяться -
Он предназначен для извлечения данных из различных онлайн-сервисов и загрузки их в БД... сейчас рассмотрим лишь то, как эти данные у нас хранятся.
Один раз мы уже ошиблись с формированием структуры хранения и использованием классического OLTP, набили шишек и перешли к классическому OLAP (моделям вида Звезда или Снежинка). Поэтому сейчас практически в каждой статье мы ссылаемся на этот теоретический материал, потому что модели такого типа лежат в основе сервиса.
OLAP в значительной мере упрощает дальнейшую работу с данными, но не в полной мере. В некоторых сервисах есть возможность использования произвольных данных, в качестве примера удобнее всего взять CRM, в которых пользователи могут создавать и удалять пользовательские поля, а так же существует возможность хранения данных полученных из других сервисов (чаще всего в виде JSON).
Для такого вида данных мы решили использовать видоизмененную "снежинку", которая похожа на "снежинку" лишь по форме, но не по содержанию. В результате мы имеем таблицы фактов (оранжевая), таблицы измерений (зеленые) и вспомогательные таблицы (голубые), связанные с таблицами измерений:
Именно вспомогательные таблицы позволяют хранить плохо структурированные данные оптимально, но в большинстве случаев требуют дополнительной обработки при использовании для аналитических целей. Сами по себе операции преобразования не очень сложные, в основном это транспонирование или разбор JSON, и если в случае с Power BI это довольно просто решалось на этапе импорта данных, то в случае с другими инструментами такими как DataLens или Metabase, это может вызвать трудности. Конечно, эти преобразования можно выполнять и при помощи SQL, но это довольно ресурсоемкие операции особенно на больших объемах данных, так что выполнение подобных запросов тем более с некоторой периодичностью становится практически невозможно... и здесь к нам на помощь приходит dbt.
dbt - инструмент с открытым исходным кодом предназначенный для преобразования данных. Основной принцип его работы заключается в том, что на вход он получает правила преобразования данных, которые в дальнейшем, в виде SQL выполняются в базе данных. В случае интеграции с сервисом он интересен тем, что им сможем пользоваться не только мы для базовых преобразований типа тех, что описаны выше, но и пользователи самостоятельно смогут описывать необходимые им преобразования, сохранять и выполнять их в своих БД. На данный момент эта интеграция пока только в планах, но мы надеемся, что она появится уже в скором времени.
После того как мы привели данные к виду, который наиболее нам удобен для дальнейшего использования, стоит задуматься, как именно мы будем с ними работать? Учитывая, что для хранения данных используются обычные реляционные СУБД, то наиболее простой способ - это подключиться к базе данных и использовать SQL. Вот только тут сразу возникает ряд проблем:
- для написания и выполнения запросов требуется отдельный инструмент. Конечно, их много, они доступны, но все же это дополнительный фактор усложняющий доступ к данным;
- далеко все знают SQL, даже, если считают, что знают;) всегда существует человеческий фактор, который может привести к ошибке и не важно по какой именно причине, ошибки мы хотим минимизировать;
- но даже, если пользователь все это умеет, написал запрос и получил данные, то встает логичный вопрос - а дальше то что? Не будет же он копировать эти данные в какой-нибудь табличный процессор и уже пытаться работать в нем, тем более если данных много и проект не один...
В данном случае нам может помочь еще один интересный инструмент - Cube,js.
Если не вдаваться в технические особенности его работы и сильно упростить, то можно сказать, что это инструмент для выполнения SQL-запросов, которые он способен генерировать автоматически, т.е. мы смело можем вычеркнуть первые два пункта описанные выше. Пользователю сервиса больше не нужно искать SQL-редактор и разбираться в написании запросов, за него все сделает сервис. myBI Connect автоматически подготавливает описания кубов, с учетом связей в таблицах, которые в дальнейшем используются Cube.js для формирования запросов к БД. Пользователю же остается только выбрать необходимые меры и измерения, после чего получить агрегированные данные.
Этот подход позволяет с одной стороны упростить с другой стороны формализовать доступ к данным. Кроме этого Cube.js имеет встроенный механизм кэширования, если запрос ранее уже выполнялся и его результат сохранен в кэше, то он будет взят из него, что позволяет значительно ускорить получение данных, снизив нагрузку на БД. Дополнительной "плюшкой" Cube.js является API, которое может быть использовано разработчиками на стороне пользователей сервиса для получения доступа к данным.
Итак, данные мы собрали и внесли в них необходимые преобразования для упрощения работы, унифицировали доступ к ним и написали меры. Теперь мы можем приступить наверное к самому интересному - визуализации, и с этим нам поможет Vega-Lite.
Отличительной чертой данного инструмента является то, что это не просто "очередная" библиотека для построения графиков (хотя против них мы ничего не имеем и сами используем), а концептуальное решение, которое предоставляет альтернативный подход к построению визуализаций, позволяющий гибко настраивать отображение данных.
Основной принцип этого инструмента в том, что описание визуализации фоормруется в виде JSON, на основании которого уже происходит его отрисовка. Описание позволяет комбинировать разные графики, которые оформляются в виде слоев и накладываются друг на друга, подключать "сигналы", которые позволяют придавать больше интерактивности визуализациям, и даже использовать дополнительное преобразование данных. В общем, это очень серьезный инструмент, который по какой-то причине не получил массового распространения, в рунете нам так и не удалось найти вменяемой информации о нем (есть предположение что это вызвано именно его сложностью;). Поэтому мы приложили еще немного усилий и создали конструктор (который мы подсмотрели в другом сервисе, будем честными), позволяющий пользователю с любым уровнем знаний создать визуализацию, пускай даже не очень сложную.
Вот такой стек мы решили реализовать. Конечно, полноценная его проработка может занять продолжительное время, но у нас уже есть что показать. Учитывая что базовая интеграция сервиса с Cube.js у нас уже была реализована несколько лет назад, хоть она и не пользовалась особой популярностью среди пользователей, мы начали именно с доработки кубов и конструктора запросов к ним. Сейчас у всех пользователей сервиса есть возможность получения данных просто указав наборы необходимых мер и измерений:
дополнительно можно задавать временные интервалы и накладывать необходимые фильтры. Необходимо учитывать, что запросы выполняемые через Cube.js должны носить аналитический характер, то есть это не фича для выгрузки гигабайтов данных, а способ получения значений мер в разрезе указанных измерений. Полученные данные:
передаются в Vega-Lite, в котором при помощи созданного нами конструктора или удобного редактора описания в JSON, уже можно построить визуализацию:
В ближайших планах у нас добавления поддержки dbt, после чего разрабатываемый стек должен будет получить завершенной вид.
Для обсуждения и развития этого фукнкционала с вами, пользователи и энтузиасты, мы завели отдельный чат в telegram - https://t.me/myBI_Gramma
В завершении небольшой скринкаст о том, где это найти в интерфейсе и как работает функционал.
upd. тут доступен и второй скринкаст про функционал -
Спасибо, не забывайте подписываться. Скоро новые материалы.