#python #nlp #textmining #nltk
Нормализация текста – это приведение каждого слова текста к его словарной форме: в именительном падеже, единственном числе (если есть) или в инфинитив для глаголов.
Окончательное качество нормализации текста зависит от каждого этапа обработки и определяется как морфологическими словарями, так и статистическими моделями. Это приводит к хорошим результатам при нормализации скорости к качеству. В этой статье мы рассмотрим начальные шаги по нормализации текста и покажем вам примеры.
Для начала нам нужно добавить несколько библиотек для работы:
import pandas as pd
from string import punctuation # сборник символов пунктуации
from nltk.tokenize import word_tokenize # для токенизации по словам
from nltk.corpus import stopwords # сборник стоп-слов
import pymorphy2 # для морфологическтого анализа текста
from nltk.probability import FreqDist # используется для кодирования «частотных распределений»
Создадим два массива для наглядности, в одном мы будет хранить начальную версию текста, а в другом итоговую.
df = pd.read_excel("file.xlsx")
df2 = pd.DataFrame(columns=['Статья'])
В дальнейшем с помощью цикла for переберем все элементы dataframe столбца «Статья» для работы с каждым элементом. Приведем все к малому регистру для удобства работы, т.к. в сборниках всё приведено к нему же.
for i in range(len(df)):
text = str(df['Статья'][i]).lower()
Для токенизации по словам, мы используем функцию word_tokenize, применив её к элементу массива. В данном случае, мы сможем разбить предложение на список слов с которыми в последствии можем работать.
token = word_tokenize(text)
Для извлечения нужных нам слов, мы должны объединить два сборника (стоп-слова и пунктуацию) в один, чтобы сравнить наши элементы с ним для получения слов (без предлогов, знаком препинания и др.)
stopword = stopwords.words('russian') + [a for a in punctuation]
token_2 = [word for word in token if word not in stopword]
Для повышения производительности дальнейшего TextMining необходимо, чтобы каждое слово приводило к своей базовой форме. В этом случае мы будем использовать процесс лематизации, так как последние символы просто удаляются во время стемминга, что приводит к неправильному значению или орфографическим ошибкам. Поэтому мы создадим экземпляр класса MorphAnalyzer и, используя метод синтаксического анализа, дадим каждое слово отдельно, не рассматривая смежные слова.
morph = pymorphy2.MorphAnalyzer()
for ii in range(len(token_2)):
token_2[ii] = morph.parse(token_2[ii])[0].normal_form
В дальнейшем добавляем наш итог в dataframe №2 для просмотра результатов нашей работы.
df2.loc[i]=' '.join(token_2)
А также в разрезе каждого элемента dataframe, основываясь на словах после проделанных ранее действий, мы можем подсчитать частоту каждого слова. Это даст нам возможность создания на их основе другими методами – меток.
fdist = FreqDist(token_2)
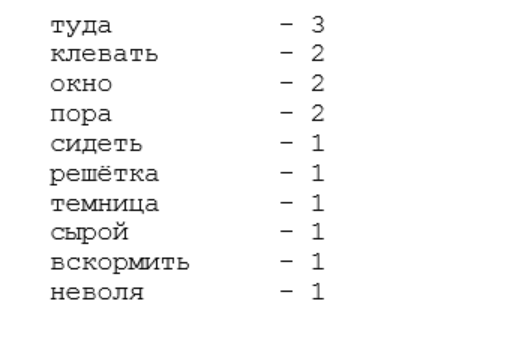
fdist1 = fdist.most_common(10)
Пример работы (до и после):
- Сижу за решеткой в темнице сырой. Вскормленный в неволе орел молодой, Мой грустный товарищ, махая крылом, Кровавую пищу клюет под окном, Клюет, и бросает, и смотрит в окно, Как будто со мною задумал одно; Зовет меня взглядом и криком своим И вымолвить хочет: «Давай улетим! Мы вольные птицы; пора, брат, пора! Туда, где за тучей белеет гора, Туда, где синеют морские края, Туда, где гуляем лишь ветер… да я!»
- cидеть решётка темница сырой вскормить неволя орёл молодая грустный товарищ махать крыло кровавый пища клевать окно клевать бросать смотреть окно я задумать один звать взгляд крик свой вымолвить хотеть « давать улететь вольный птица пора брат пора туда туча белеть гора туда синеть морской край туда гулять лишь ветер…
Пример (топ 10 слов):