Фейковые новости распространяются так же активно, как лесной пожар - в различных СМИ, социальных сетях и в том числе из уст в уста. Это очень серьезная и тревожная проблема, поскольку она наносит большой ущерб как обществу, так и государству. Интернет, как мы все знаем, является одним из самых масштабных изобретений в истории, и многие люди используют его для различных целей и задач. Существует множество социальных медиа-платформ, где пользователи могут размещать и делиться различными новостями, которые чаще всего не проверяются. Этими фейковыми новостями в основном делятся для того, чтобы очернить чей-то имидж, распространить слухи, спровоцировать споры и так далее.
В результате для оперативной оценки и распознавания фейковых новостей требуется классификатор машинного обучения, поскольку существует большая вероятность человеческой ошибки. За прошедшие годы было проведено много исследований и усилий по выявлению фейковых новостей; в этой статье мы рассмотрим, как использовать модель машинного обучения для определения того, является ли новость ложной. Мы будем использовать очень большой набор данных для модели машинного обучения, чтобы найти взаимосвязь между заголовками или названиями фейковых новостей и определить фейковые новости.
Следует также подчеркнуть, что это не универсальное решение, и это далеко не единственный метод выявления фейковых новостей используя Python. Другие подходы включают использование PassiveAggressiveClassifier и таких алгоритмов, как Random Forests, K-Nearest Neighbors (KNN), Naive Bayes, Decision Trees и Support Vector Machines. Для отображения результатов анализа набора данных с использованием различных подходов можно использовать матрицу смешения. Поэтому я настоятельно советую вам провести собственное исследование, собрать информацию, а затем выбрать лучший для вас вариант.
Наивные байесовские классификаторы - популярный статистический инструмент для фильтрации электронной почты. Они были одной из первых попыток решить проблему фильтрации спама, когда они только появились в середине 1990-х годов. Наивные байесовские классификаторы использует стратегию мешка слов, которая распространена в текстовой классификации, для идентификации спама в электронной почте. Спам и не спам различаются по лексемам (обычно это слова, но иногда и другие синтаксические или несинтаксические компоненты), а теорема Байеса используется для определения того, является ли письмо спамом или нет.
Тип фейковых новостей
1. Кликбейт: Кликбейт - это популярный метод распространения ложных новостей (и других типов материалов). Это выдуманные истории, которые используются для увеличения посещаемости сайта и доходов от рекламы.
2. Заголовки, вводящие в заблуждение: Статьи и материалы, которые не являются полностью фейковыми, могут быть искажены за счет использования сенсационных или обманчивых заголовков.
3. Сатира или пародия: Контент, который часто пародирует новостные шоу и использует комедийные приемы для установления контакта с аудиторией, без цели навредить, но с возможностью обмануть.
4. Ложный контент: Это, в основном, когда подлинные или истинные источники выдаются за фейковые, ложные и сфабрикованные источники или публикации.
Необходимые требования:
- 1. Python3
- 2. Jupyter Notebook
- 3. Sci-kit learn
Установите Sci-kit learn:
Введите этот код в терминале или командной строке, чтобы установить Sci-kit learn.
pip install -U scikit-learn
Установите Jupyter Notebook:
Скопируйте и вставьте этот блок кода в терминал или командную строку, чтобы установить Jupyter Notebook.
pip install notebook
Запустите его с помощью этой команды:
jupyter notebook
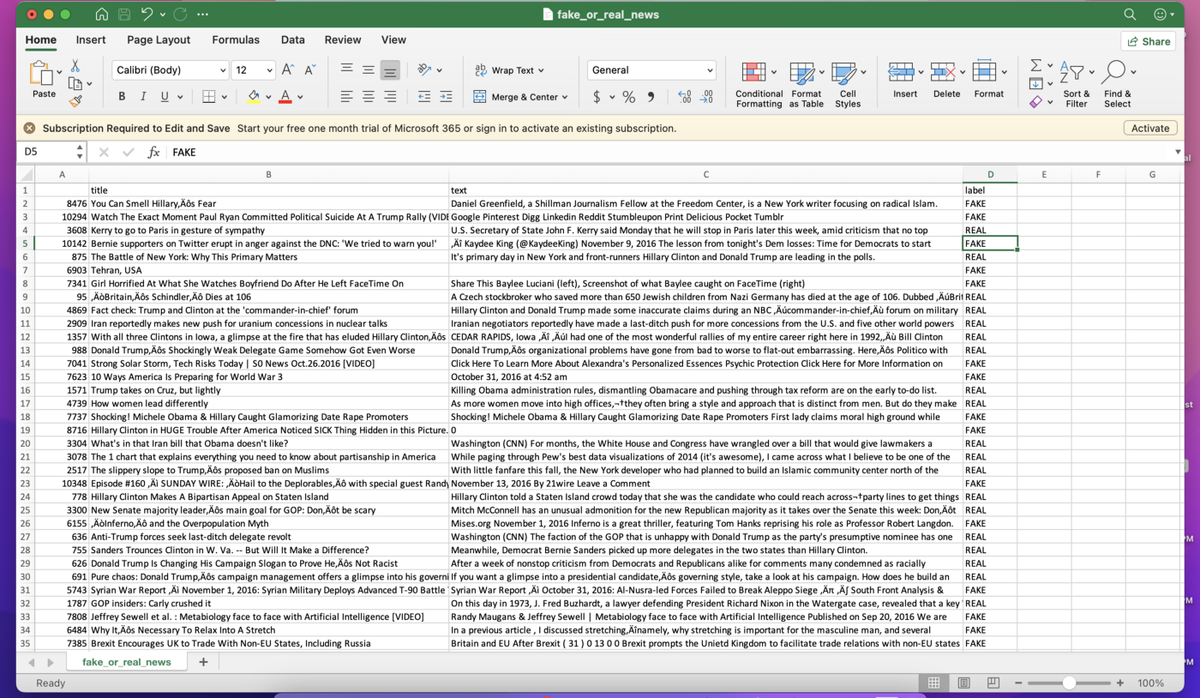
Набор данных, который мы используем для обнаружения фейковых новостей, включает информацию о заголовке новости, ее содержании и колонку label, которая указывает, является ли новость фейком или нет.
Теперь давайте импортируем все библиотеки, необходимые для этого урока.
Нам понадобится pandas для импорта данных и эффективной обработки большого набора данных. Мы также будем импортировать другие библиотеки, такие как NumPy и библиотека Sci-kit learn.
Большинство проектов терпят неудачу, так и не добравшись до производства. Ознакомьтесь с нашей бесплатной электронной книгой, чтобы узнать, как реализовать жизненный цикл MLOps для лучшего мониторинга, обучения и развертывания моделей машинного обучения для повышения производительности и итеративности.
Импортируйте набор данных:
На этом этапе мы будем импортировать загруженный набор данных. Посмотрите на первые 5 строк набора данных, чтобы получить краткое представление о том, как выглядит набор данных.
Давайте получим больше информации о наборе данных.
В принципе, причина получения структуры нашего набора данных заключается в том, чтобы получить размеры DataFrame, а на выходе мы получаем такой набор.
Проверка наличия отсутствующих значений в наборе данных:
Отсутствующие данные определяются как значения или данные для переменной, которые не хранятся (или отсутствуют) в указанном наборе данных. Они часто представлены NaN или пустой ячейкой, и вызваны более ранними данными, которые могли быть уничтожены из-за ненадлежащего ухода, или пользователь мог намеренно дать неверную информацию. Если отсутствующие значения не обрабатываются должным образом, в итоге вы можете получить необъективную модель машинного обучения, которая дает ошибочные результаты. Неточности в статистическом анализе могут быть следствием отсутствия данных. Для определения отсутствующих значений в каждом столбце можно использовать функцию TheDataSet.isnull().sum.
Как вы можете видеть, в наборе данных нет отсутствующих значений.
Давайте проверим имеющиеся у нас столбцы, чтобы очистить набор данных.
Это шаг, который я лично рекомендую при подготовке данных, поскольку он помогает удалить ненужные столбцы из набора данных.
list(dataset.columns)
Нам не нужен столбец 'Unnamed: 0' в нашей модели, поэтому давайте отбросим его.
Столбец label будет использоваться для прогнозирования значений, а столбец title - для обучения модели машинного обучения.
Разделите набор данных на обучающий и тестовый наборы, а затем обучите модель обнаружения фейковых новостей, используя метод наивных байесовских классификаторов. Мы используем наивные байесовские классификаторы, потому что среди всех различных используемых моделей точность обнаружения спамеров составляет 70%, а мошенников - 71,2%. Используемые модели достигли низкого уровня промежуточной точности для отделения спамеров от не-спама, по-разному идентифицируя фейковые новости.
Техника нормализации является важным этапом в очистке данных перед использованием машинного обучения для категоризации данных. Результаты показали, что точность наивных байесовских классификаторов составляет 96,08% для обнаружения фейковых сообщений.
<script src="https://gist.github.com/KTsvetkov/25ea6f327b2a469d18bec128e460ed2c.js"></script>
Давайте протестируем модель, я просто введу любой заголовок новости в Google news и посмотрим, предскажет ли обученная модель, что она настоящая или фейковая.
Давайте проверим, будет ли он предсказывать фейковые новости как ложные, я просто напечатаю случайный заголовок новости.
Заключение
Мы рассмотрели, что такое фейковые новости и как они распространяются по интернету как лесной пожар благодаря платформам социальных сетей, которые не могут заметить их самостоятельно. Мы рассмотрели, как создать систему обнаружения фейковых новостей с помощью огромного набора данных и подхода наивных байесовских классификаторов для обучения модели обнаружения фейковых новостей, и нам удалось отличить фейковые новости от настоящих.
Следует отметить, что определение фейковых новостей - это все еще продолжающаяся борьба, и хотя эта модель не может заменить старое доброе исследование, она может помочь сократить количество заголовков, которые мы видим ежедневно.
Чтобы проверить эту модель на практике, просто измените текст переменной news_headline. Ссылка на код находится здесь, убедитесь, что вы прочитали файл Read.me в репозитории Github.
#machinelearning #artificialintelligence #ai #datascience #python #programming #technology #deeplearning #coding #bigdata