
#sql #оконные функции #анализ данных #БАЗЫ ДАННЫХ
Предложение OVER помогает «открыть окно», т.е. определить строки, с которым будет работать та или иная функция.
Предложение PARTITION BY не является обязательным, но дополняет OVER и показывает, как именно мы разделяем строки, к которым будет применена функция.
ORDER BY определит порядок обработки строк.
В одном SELECT может быть больше одного OVER, эта прекрасная особенность упростит выполнение аналитической задачи в дальнейшем.
Итак, оконные функции делятся на:
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
Агрегатные оконные функции:
Собственно, те же, что и обычные, только встроенные в конструкцию с OVER
SUM/ AVG / COUNT/ MIN/ MAX
Для наглядности работы данных функций воспользуемся базовым набором данных (T)
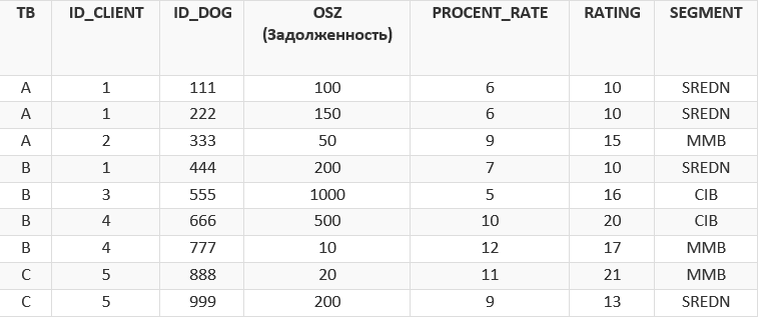
Задача:
Найти максимальную задолженность в каждом банке.
Для чего тут оконные функции? Можно же просто написать:
SELECT TB, max(OSZ) OSZ
FROM T
group by TB
В данном контексте, действительно, применение оконных функций нецелесообразно, но, когда речь заходит о задаче:
Собрать дэшборд, в котором содержится информация о максимальной задолженности в каждом банке, а также средний размер процентной ставки в каждом банке в зависимости от сегмента, плюс еще количество договоров всего всем банкам, в голове рисуются множественные джойны из подзапросов и как-то сразу тяжело на душе. Однако, как я говорил выше, в одном SELECT можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
SELECT TB, ID_CLIENT, ID_DOG, OSZ, PROCENT_RATE, RATING, SEGMENT
, MAX(OSZ) OVER (PARTITION BY TB) 'Максимальная задолженность в разбивке по банкам'
, AVG(PROCENT_RATE) OVER (PARTITION BY TB, SEGMENT) 'Средняя процентная ставка в разрезе банка и сегмента'
, COUNT(ID_DOG) OVER () 'Всего договоров во всех банках'
FROM T
На примере AVG(PROCENT_RATE) OVER (PARTITION BY TB, SEGMENT) подробнее:
- Мы применяем AVG – агрегатную функцию по подсчету среднего значения к столбцу PROCENT_RATE.
- Затем предложением OVER определяем, что будем работать с некоторым набором строк. По умолчанию, если указать OVER() с пустыми строками, то этот набор строк равен всей таблице.
- Предложением PARTITION BY выделяем разделы в наборе строк по заданному условию, в нашем случае, в разбивке на ТБ и Сегмент.
- В итоге, к каждой строке базовой таблицы применится функция по подсчету среднего из набора строк, разбитых на разделы (по ТБ и Сегменту).
Другой тип оконных функций, надо признать, мой любимый и был использован для решения многих задач. Функции ранжирования для каждой строки в разделе возвращают значение рангов или рейтингов. Все ведь любят рейтинги, правда…?
Базовый набор данных: банки, отделы и количество ревизий.
Сами ранжирующие функции:
ROW_NUMBER – нумерует строки в результирующем наборе.
RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается с пропуском.
DENSE_RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается без пропуска.
NTILE – помогает разделить результирующий набор на группы.
Для понимания написанного, проранжируем таблицу по убыванию количества ревизий:
SELECT *
, ROW_NUMBER() OVER(ORDER BY count_revisions desc)
, Rank() OVER(ORDER BY count_revisions desc)
, DENSE_RANK() OVER(ORDER BY count_revisions desc)
, NTILE(3) OVER(ORDER BY count_revisions desc)
FROM Table_Rev
ROW_NUMBER – пронумеровал столбцы в порядке убывания количества ревизий.
RANK – проранжировал отделы во всех банках в порядке убывания количества ревизий, но как только встретились одинаковые значения (количество ревизий 95), функция присвоила им ранг 4, а следующее значение получило ранг 6.
DENSE_RANK – аналогично RANK, но как только встретились одинаковые значения, следующее значение получило ранг 5.
NTILE – функция помогла разбить таблицу на 3 группы (указал в аргументе). Так как в таблице 18 значений, в каждую группу попало по 6.
Задача:
Найти второй отдел во всех банках по количеству ревизий.
Можно, конечно, воспользоваться чем-то вроде:
SELECT MAX(count_revisions) ms
FROM Table_Rev
WHERE count_revisions!=(SELECT MAX(count_revisions) FROM Table_Rev)
Но если речь идет не про второй отдел, а про третий?.. уже сложнее. Действительно, никто не списывает со счетов OFFSET, но в этой статье говорится об оконных функциях, так почему бы не написать так:
With T_R as
(
SELECT *
, DENSE_RANK() OVER(ORDER BY count_revisions desc) ds
FROM Table_Rev
)
SELECT * FROM T_R
WHERE ds=3
Как и во всех других типах функций, здесь можно выделять разделы с помощью PARTITIONBY. Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по TB, сортируем по возрастанию:
With T_R as
(
SELECT *
, DENSE_RANK() OVER(PARTITION BY tb ORDER BY count_revisions) ds
FROM Table_Rev
)
SELECT tb,dep,count_revisions
FROM T_R
WHERE ds=1
Получаем:
Оконные функции смещения помогут нам, когда необходимо обратиться к строке в наборе данных из окна, относительно текущей строки с некоторым смещением. Проще говоря, узнать, какое значение (событие/ дата) идет после/до текущей строки. Похоже на отличную штуку в предобработке лога данных.
LAG — смещение назад.
LEAD — смещение вперед.
FIRST_VALUE — найти первое значение набора данных.
LAST_VALUE — найти последнее значение набора данных.
LAG и LEAD имеют следующие аргументы:
- Столбец, значение которого необходимо вернуть
- На сколько строк выполнить смешение (дефолт =1)
- Что вставить, если вернулся NULL
Как обычно, на практике проще:
Базовый набор данных, содержит id задачи, события внутри нее и их дату:
Применяя конструкцию:
SELECT *
, LEAD (Event, 1, 'end') OVER (PARTITION BY ID_Task ORDER BY Date_Event) as Next_Event
, LEAD (Date_Event, 1, '2099-01-01') OVER(PARTITION BY ID_Task ORDER BY Date_Event) as Next_Date
FROM Table_Task
Получаем набор данных, который хоть сейчас в graphviz (нет).
Аналитические оконные функции подходят под специфичные задачи и описывать их здесь я, пожалуй, не буду. Но, возможно, вы решите ознакомиться с ними самостоятельно, а значит будете более подготовлены к решению хитрозакрученных задач.
Тем, кто слышит про данные функции впервые, надеюсь, статья окажется полезной, а, кто уже со всем этим знаком, простите, потраченное время никто не вернет.
Читайте также: