Используйте следующие методы API-интерфейсов фреймворка:
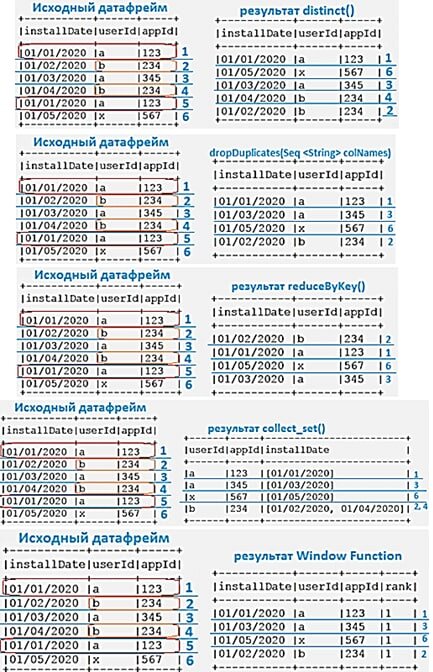
• distinct() ¬- самый простой и часто использующийся способ убрать из датафрейма идентичные повторяющиеся строки
• dropDuplicates() – в отличие от distinct(), который не принимает аргументов вообще, в аргументах dropDuplicates() можно указать подмножество столбцов для удаления повторяющихся записей. Поэтому dropDuplicates(Seq <String> colNames) больше подходит, когда нужно обработать только некоторые столбцы из исходного набора данных.
• reduceByKey() – возвращает новый RDD - распределенный набор данных из пар «ключ-значение» (K, V), в котором все значения для одного ключа объединяются в кортеж - ключ и результат выполнения функции reduce для всех значений, связанных с этим ключом. Этот метод удаления дублей ограничен размером Scala-кортежа, который содержит от 2 до 22 элементов. Поэтому reduceByKey() не стоит использовать, когда в ключах или значениях Spark RDD более 22 столбцов.
• collect_set() - функция из API-интерфейса Spark SQL собирает и возвращает набор уникальных элементов. Она не является детерминированной, т.к. порядок результатов зависит от порядка строк, который может измениться после перемешивания, и представляет собой не «настоящую» дедупликацию. По сути, collect_set() – это сворачивание записей путем выполнения groupBy() и сбора уникальных значений для столбца, относящегося к каждой группе.
• написать собственную оконную функцию, чтобы обойти ограничение размера кортежей Scala. Например, разделить RDD по столбцам, отсортировать их и отфильтровать нужные значения.