Реализована модель для соревнований на Кагл
https://www.kaggle.com/c/real-estate-price-prediction-moscow
Задача - предсказать цены на квартиры в датасете test.csv. Даны два датасета: train.csv (содержит признаки и цены на квартиры) и test.csv (только признаки).
Реализованы следующие шаги:
Загрузка данных
1. EDA
2. Обработка выбросов
- поле Rooms
** Создаем вспомогательный столбец с признаком выброса
** присваиваем среднее количество комнат 3 для площади больше 200
** присваиваем среднее количество комнат 1 для площади меньше = 55
** присваиваем среднее количество комнат 2 для площади от 55 до 100
** 'Rooms' >= 6 Судя по площади, тут везде 1 комната
- поле KitchenSquare
** заполнили поле KitchenSquare_outlier
** замедианим то, что больше 30
** заполнили поле KitchenSquare_outlier
** замедианим то, что меньше 4
- поле Square
** делим выбросы на 10, т.к. похоже, что ошиблись в запятой
* Создадим поле DELETE Там отметим все подозрительные строки, в достоверности которых я сильно сомневаюсь
** Для порядка скорректируем кол-во комнат в квартирах < 20 м
** делать с этими квартирами < 15 м ничего не будем, но запишем их в поле DELETE
- поле LifeSquare
- поле Floor
- поле HouseYear
- поле Ecology_1
- поле Ecology_2
- поле Ecology_3
- поле Social_1
- поле Social_2
- поле Social_3
- поле Healthcare_1
- поле Shops_1
- поле Shops
3. Построение новых признаков - Генерация новых фич
- * 1_Target encoding - целевое кодирование # District, Rooms
- 2_Target encoding # floor, year
- Binary features -- переводим в бинарные признаки
- примерживаем district_size
- More categorical features переводим в категорию этажи и года
- Target encoding примердживаем таргет инкодинги
- 3. Отбор признаков
- 4. Разбиение на train и test
- 5. Построение модели
- 6. Прогнозирование на тестовом датасете
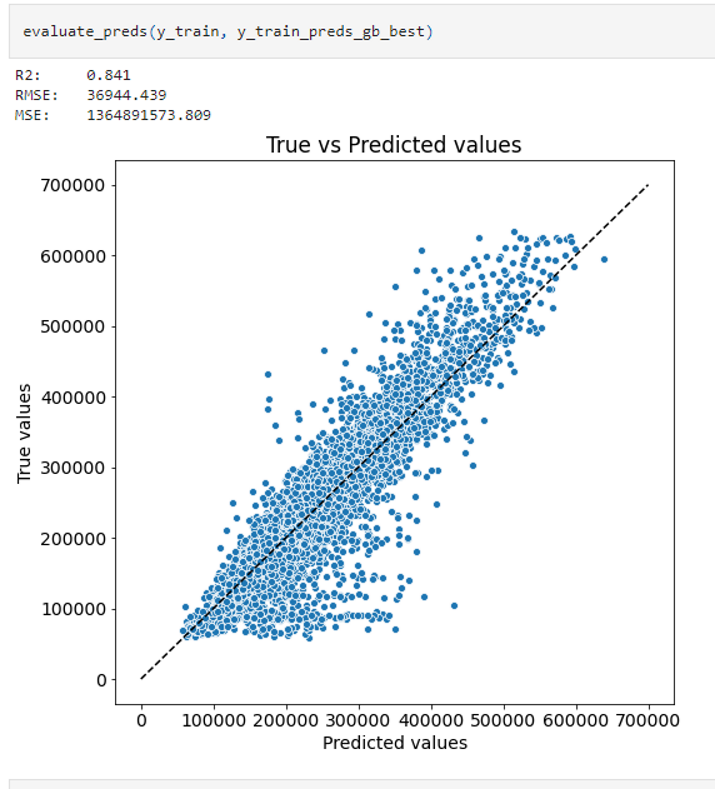
Обучал с использованием разных алгоритмов: линейная и логистическая регрессия, дерево решений, случайный лес. Проводил поиск по сетке параметров. Лучший результат показал градиентный бустинг.
На трейне получен следующий результат. Метрика - коэффициент детерминации R2 = 0,841
Отзыв куратора:
Добрый день!
- Провели отличный разведочный анализ данных, очень красивые и понятные графики отрисовали
- Хорошая работа с признаками, связанными с площадью квартиры
- Здорово, что еще и работали с признаками по типу Social и Shops
- Очень классно, что заполняете пропуски в Healthcare_1, а не стали выбрасывать эти данные
- Значения, которые используете для заполнения пропусков (к примеру, ['Rooms'].mean()) лучше считать на обучающем наборе данные, а использовать на тестовом
Private LB на kaggle:
место 156
метрика R2 = 0.71725



















