
Моделирование оттока (Churn Modeling, Churn Prediction) – одна из популярнейших задач Машинного обучения (ML), нацеленная на удержание пользователей с определенными поведением и характеристиками. Рассмотрим в качестве примера кейс американского провайдера услуг связи Telco. Мы будем использовать JavaScript.
«Предсказывайте поведение, чтобы удерживать клиентов. Вы можете анализировать все соответствующие данные о клиентах и разрабатывать целенаправленные программы их удержания».
Датасет (Dataset) имеет 7044 записи и 21 столбец:
- customerID: идентификатор клиента
- Gender: является ли клиент мужчиной или женщиной
- SeniorCitizen: является ли клиент пожилым гражданином (да, нет)
- Partner: есть ли у клиента партнер (да, нет)
- Dependents: есть ли у клиента иждивенцы (да, нет)
- Tenure: количество месяцев, в течение которых клиент оставался в компании
- PhoneService: есть ли у клиента телефония (да, нет)
- MultipleLines: есть ли у клиента несколько линий (да, нет, нет телефонии)
- InternetService: интернет-провайдер клиента (DSL, оптоволокно, нет)
- OnlineSecurity: есть ли у клиента онлайн-безопасность (да, нет, нет интернет-сервиса)
- OnlineBackup: есть ли у клиента онлайн-резервное копирование (да, нет, нет интернет-сервиса)
- DeviceProtection: есть ли у клиента защита устройства (да, нет, нет интернет-сервиса)
- TechSupport: есть ли у клиента техническая поддержка (да, нет, нет интернет-сервиса)
- StreamingTV: есть ли у клиента потоковое телевидение (да, нет, нет интернет-сервиса)
- StreamingMovies: есть ли у клиента потоковые фильмы (да, нет, нет интернет-сервиса)
- Contract: срок контракта клиента (ежемесячно, один год, два года)
- PaperlessBilling: есть ли у клиента безбумажный биллинг (да, нет)
- PaymentMethod: способ оплаты клиента (электронный чек, чек по почте, автоматический банковский перевод, автоплатеж с карты)
- MonthlyCharges: сумма, взимаемая с клиента ежемесячно
- TotalCharges: общая сумма, списанная с клиента
- Churn: ушел ли клиент или нет (да или нет)
Мы будем использовать Papa Parse для загрузки данных:
const prepareData = async () => {
const csv = await Papa.parsePromise(
"https://raw.githubusercontent.com/curiousily/Customer-Churn-Detection-with-TensorFlow-js/master/src/data/customer-churn.csv"
);
const data = csv.data;
return data.slice(0, data.length - 1);
};
Обратите внимание, что мы игнорируем последнюю строку, так как она пуста.
Разведочный анализ данных
Давайте поизучаем наш набор данных. Сколько клиентов ушло?
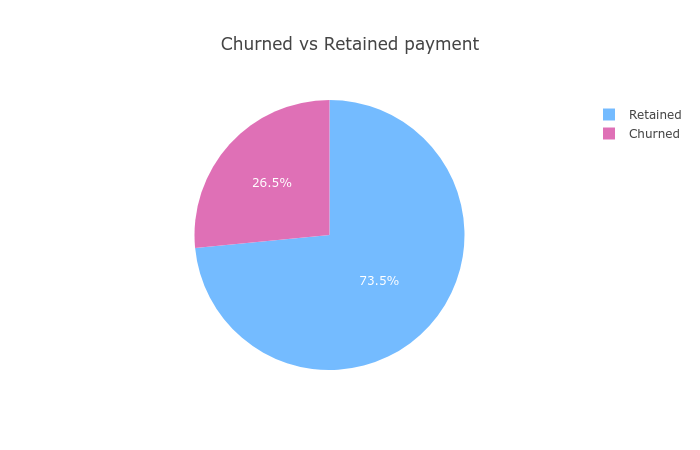
Около 74% клиентов продолжают пользоваться услугами компании. У нас очень несбалансированный набор данных.
Влияет ли пол на вероятность ухода?
Кажется, нет. У нас примерно одинаковое количество клиентов женского и мужского пола. Как насчет возраста?
Около 20% клиентов – пожилые, и они гораздо чаще уходят.
Как долго клиенты остаются в компании?
Кажется, что чем дольше вы остаетесь, тем больше вероятность, что вы останетесь с Telco и дальше.
Как ежемесячные платежи влияют на отток?
Покупатель с низкими ежемесячными платежами (<30 долларов США) с гораздо большей вероятностью будет удержан.
Как насчет общей суммы, взимаемой с клиента?
Чем выше общая списанная сумма средств, тем больше вероятность того, что этот клиент останется.
В нашем наборе данных всего 21 Признак (Feature), и мы не просматривали их все. Тем не менее, мы нашли кое-что интересное.
Мы узнали, что столбцы SeniorCitizen, tenure, MonthlyCharges и TotalCharges в некоторой степени коррелируют со статусом оттока. Мы будем использовать их для нашей модели.
Глубокое обучение
Глубокое обучение (Deep Learning) — это подраздел Машинного обучения, связанный с алгоритмами, основанными на структуре и функциях мозга – искусственными Нейронными сетями (Neural Network).
Чтобы получить глубокую нейронную сеть, возьмите нейронную сеть с одним скрытым слоем (мелкая нейронная сеть) и добавьте больше слоев: это определение глубокой нейронной сети.
В глубоких нейронных сетях каждый слой обучается на выходных данных предыдущего слоя. Таким образом, мы можем создать иерархию функций-столбцов с возрастающей абстракцией и изучать сложные концепции.
Эти сети очень хорошо обнаруживают закономерности в необработанных данных (изображениях, текстах, видео- и аудиозаписях), а это самый большой объем данных, который у нас есть. Например, Deep Learning может взять миллионы изображений и разделить их на фотографии вашей бабушки, забавных кошек и вкусных тортов.
Глубокие нейронные сети – передовой метод решения целого ряда проблем, таких как распознавание изображений, их сегментация, распознавание звука, рекомендательные системы, обработка естественного языка и т. д.
Таким образом, глубокое обучение — это большие нейронные сети. Почему сейчас? Почему глубокое обучение не было практичным раньше?
- Для большинства реальных приложений глубокого обучения требуются большие объемы размеченных данных: для разработки беспилотного автомобиля могут потребоваться тысячи часов видео.
- Обучающие модели с большим количеством параметров требуют значительных вычислительных мощностей: аппаратное обеспечение специального назначения в форма GPU и TPU предлагает массовые параллельные вычисления.
- Крупные компании уже некоторое время хранят ваши данные: они хотят их монетизировать.
- Мы узнали (вроде как), как инициализировать Веса (Weights) нейронов в моделях нейронной сети: в основном, используя небольшие случайные значения.
- У нас есть лучшие методы Регуляризации (Regularization)
И последнее, но не менее важное: у нас есть программное обеспечение, которое является производительным и простым в использовании. Такие библиотеки, как TensorFlow, PyTorch, MXNet и Chainer, позволяют специалистам-практикам разрабатывать, анализировать, тестировать и развертывать модели различной сложности, а также повторно использовать результаты работы других специалистов-практиков и исследователей.
Прогнозирование оттока клиентов
Давайте воспользуемся механизмом глубокого обучения, чтобы предсказать, какие клиенты собираются уйти. Во-первых, нам нужно выполнить некоторую предварительную обработку данных, поскольку многие столбцы являются категориальными.
Предварительная обработка данных
Мы будем использовать все числовые (кроме customerID) и следующие категориальные признаки:
const categoricalFeatures = new Set([
"TechSupport",
"Contract",
"PaymentMethod",
"gender",
"Partner",
"InternetService",
"Dependents",
"PhoneService",
"TechSupport",
"StreamingTV",
"PaperlessBilling"
]);
Давайте создадим наборы данных для обучения и тестирования из наших данных:
const [xTrain, xTest, yTrain, yTest] = toTensors(
data,
categoricalFeatures,
0.1
);
Вот как мы создаем наши Тензоры (Tensor) - многомерные массивы чисел:
const toTensors = (data, categoricalFeatures, testSize) => {
const categoricalData = {};
categoricalFeatures.forEach(f => {
categoricalData[f] = toCategorical(data, f);
});
const features = [
"SeniorCitizen",
"tenure",
"MonthlyCharges",
"TotalCharges"
].concat(Array.from(categoricalFeatures));
const X = data.map((r, i) =>
features.flatMap(f => {
if (categoricalFeatures.has(f)) {
return categoricalData[f][i];
}
return r[f];
})
);
const X_t = normalize(tf.tensor2d(X));
const y = tf.tensor(toCategorical(data, "Churn"));
const splitIdx = parseInt((1 - testSize) * data.length, 10);
const [xTrain, xTest] = tf.split(X_t, [splitIdx, data.length - splitIdx]);
const [yTrain, yTest] = tf.split(y, [splitIdx, data.length - splitIdx]);
return [xTrain, xTest, yTrain, yTest];
};
Во-первых, мы используем функцию toCategorical() для преобразования категориальных признаков в векторы с использованием Быстрого кодирования (One-Hot Encoding). Мы делаем это, конвертируя строковые значения в числа и используя tf.oneHot() для создания векторов.
Мы создаем двумерный тензор из наших признаков (категориальных и числовых) и нормализуем его. Другой тензор с горячим кодированием сделан из столбца Churn.
Наконец, мы разделяем набор на Тренировочные данные (Train Data) и Тестовые (Test Data) и возвращаем результаты. Как мы кодируем категориальные переменные?
const toCategorical = (data, column) => {
const values = data.map(r => r[column]);
const uniqueValues = new Set(values);
const mapping = {};
Array.from(uniqueValues).forEach((i, v) => {
mapping[i] = v;
});
const encoded = values
.map(v => {
if (!v) {
return 0;
}
return mapping[v];
})
.map(v => oneHot(v, uniqueValues.size));
return encoded;
};
Сначала мы извлекаем вектор всех значений признака. Затем мы получаем уникальные значения и превращаем строковые значения в целочисленные.
Обратите внимание, что мы проверяем пропущенные значения и кодируем их как 0. Наконец, мы кодируем каждое значение.
Вот остальные служебные функции:
// нормализованное_значение = (значение − минимум) / (максимум − минимум)
const normalize = tensor =>
tf.div(
tf.sub(tensor, tf.min(tensor)),
tf.sub(tf.max(tensor), tf.min(tensor))
);
const oneHot = (val, categoryCount) =>
Array.from(tf.oneHot(val, categoryCount).dataSync());
Создание глубокой нейронной сети
Мы завершим построение и обучение нашей модели в функцию с именем trainModel():
const trainModel = async (xTrain, yTrain) => {
// Сейчас подробно рассмотрим, что внутри
...
return model;
};
Давайте создадим глубокую нейронную сеть, используя API последовательной модели в TensorFlow:
const model = tf.sequential();
model.add(
tf.layers.dense({
units: 32,
activation: "relu",
inputShape: [xTrain.shape[1]]
})
);
model.add(
tf.layers.dense({
units: 64,
activation: "relu"
})
);
model.add(tf.layers.dense({ units: 2, activation: "softmax" }));
Наша глубокая нейронная сеть имеет два скрытых слоя с 32 и 64 нейронами соответственно. Каждый слой имеет Функция активации выпрямителя (ReLU).
Время скомпилировать нашу модель:
model.compile({
optimizer: tf.train.adam(0.001),
loss: "binaryCrossentropy",
metrics: ["accuracy"]
});
Мы будем обучать нашу модель с помощью оптимизатора "Адаптивная оценка момента" (Adam) и измерять нашу ошибку с помощью бинарной Кросс- энтропии (Cross-Entropy).
Обучение
Наконец, мы передадим обучающие данные нашей модели и обучимся на них в течение 100 эпох, перемешаем данные и используем 10% для проверки. Визуализируем ход обучения с помощью tfjs-vis:
const lossContainer = document.getElementById("loss-cont");
await model.fit(xTrain, yTrain, {
batchSize: 32,
epochs: 100,
shuffle: true,
validationSplit: 0.1,
callbacks: tfvis.show.fitCallbacks(
lossContainer,
["loss", "val_loss", "acc", "val_acc"],
{
callbacks: ["onEpochEnd"]
}
)
});
Давайте обучим нашу модель:
const model = await trainModel(xTrain, yTrain);
Похоже, что наша модель обучается в течение первых десяти эпох и выходит на плато после этого.
Оценка модели
Оценим нашу модель на тестовых данных:
const result = model.evaluate(xTest, yTest, {
batchSize: 32
});
// Потери
result[0].print();
// Точность
result[1].print();
Модель имеет точность 79,2% на тестовых данных:
Tensor 0.44808024168014526
Tensor 0.7929078340530396
Давайте посмотрим, какие ошибки он допускает, используя Матрицу ошибок (Confusion Matrix):
const preds = model.predict(xTest).argMax(-1);
const labels = yTest.argMax(-1);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = document.getElementById("confusion-matrix");
tfvis.render.confusionMatrix(container, {
values: confusionMatrix,
tickLabels: ["Retained", "Churned"]
});
Похоже, что наша модель слишком самоуверенна в прогнозировании удержания клиентов. В зависимости от потребностей мы можем перенастроить модель и улучшить ее предсказательную способность.
Песочница, не требующая дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Venelin Valkov
Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.