В прошлой части статьи по динамической маршрутизации мы рассмотрели протокол OSPF. А теперь – обещанное нами продолжение о протоколе BGP. Как обычно, глубоко углубляться в теорию мы не будем, т.к. в интернете присутствует большое количество материалов, которые подробно описывают протокол BGP, к примеру здесь и здесь. Мы остановимся лишь на базовых понятиях и принципах работы.
BGP - протокол динамической маршрутизации, основная его часть описана в RFC 4271. Главная задача протокола состоит в том, чтобы обмениваться маршрутами между автономными системами (eBGP), а также в пределах одной системы (iBGP). BGP – один из самых главных протоколов маршрутизации в сети Internet, который поддерживается большинством L3-устройств, в том числе и L3-коммутаторами SNR. В качестве транспортного протокола BGP использует TCP (port 179).
Принцип работы протокола BGP довольно прост. Изначально между двумя маршрутизаторами, каждый из которых имеет свой уникальный номер автономномной системы, устанавливается TCP-соединение. Далее происходит обмен сообщениями для согласования и подтверждения параметров соединения. И затем, для поддержания соединения, происходит передача KEEPALIVE-сообщений. Обмен маршрутами между автономными системами происходит с помощью отправки UPDATE-сообщений, а сами маршруты хранятся в базах маршрутных данных RIB (routing information
Базовая настройка BGP
В качестве самого простого примера возьмем L3-коммутаторы SNR-S300X-24FQ, которые будут выступать в роли пограничных коммутаторов на сети оператора связи. Коммутатор SNR-S4650X-48FQ будет задействован как магистральный “Uplink”. Установим между устройствами 2 BGP-сессии.
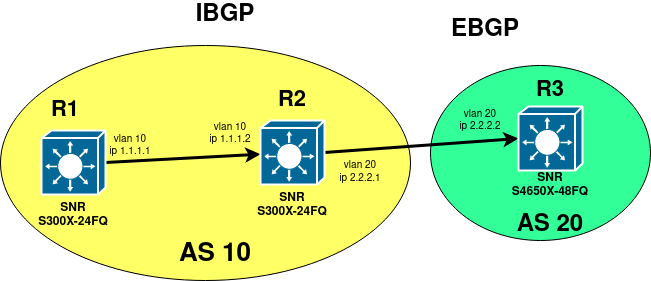
Конфигурация коммутаторов
Между R1 и R2-коммутаторами сети оператора связи будет установлена iBGP-сессия, а между коммутатором R2 и коммутатором R3, принадлежащему другой AS, условно, магистральным Uplink’ом будет eBGP-сессия. После применения конфигурации, приведенной выше, коммутаторы устанавливают BGP-соседство и анонсируют друг другу указанные маршруты. Процесс установления соединения происходит следующим образом:
- начальное состояние - IDLE;
- происходит установка TCP-сессии между устройствами, состояние сессии: ACTIVE;
- сессия установлена, происходит обмен OPEN-сообщениями для согласования параметров;
- после всех согласований сессия переходит в состояние ESTABLISHED. Это говорит нам о том, что BGP сессия успешно установлена;
- далее, происходит обмен UPDATE-сообщениями, в которых устройства обмениваются известными им маршрутами, вследствие чего происходит заполнение таблицы маршрутизации BGP. Важно отметить, что именно сами маршруты содержатся в поле NLRI сообщения UPDATE. До отправки UPDATE- сообщений в таблицу маршрутизации будут добавлены только локальные маршруты.
Убедимся, что соседства между устройствами были установлены и посмотрим маршруты:
Выводы команд “show ip bgp summary” и “show ip route”
BFD (Bidirectional Forwarding Detection)
Стоит учитывать, что при падении линка или потере связности между устройствами, BGP-сессия исчезает не сразу. Она остается активной еще некоторое время. Для быстрой сходимости сети в данном случае используют протокол BFD (RFC 5880). Данный протокол обнаруживает проблемы связности на IP-уровне и обеспечивает быструю сходимость сети. Рассмотрим ниже пример настройки. Обращаем внимание на то, что для каждого соседа он включается отдельно, при этом настройка таймеров производится на VLAN-интерфейсе:
Конфигурация коммутаторов
Вывод команды “show ip bgp summary” до использования протокола BFD
Теперь проверим то же самое, но уже после применения BFD. До применения команды сессия была активна еще порядка 4-х минут, хотя линк между коммутаторами уже отсутствовал. Только спустя это время, в логах коммутатора появляется информация о том, что не удалось установить соседство:
Логи коммутатора до и после применения протокола BFD
Примеры управления BGP-маршрутизацией
Для управления политикой маршрутизации в BGP, существует несколько способов. В данном примере мы остановимся на таких атрибутах BGP как Weight, Community, MED. Для примера всех атрибутов, будет собрана одинаковая схема:
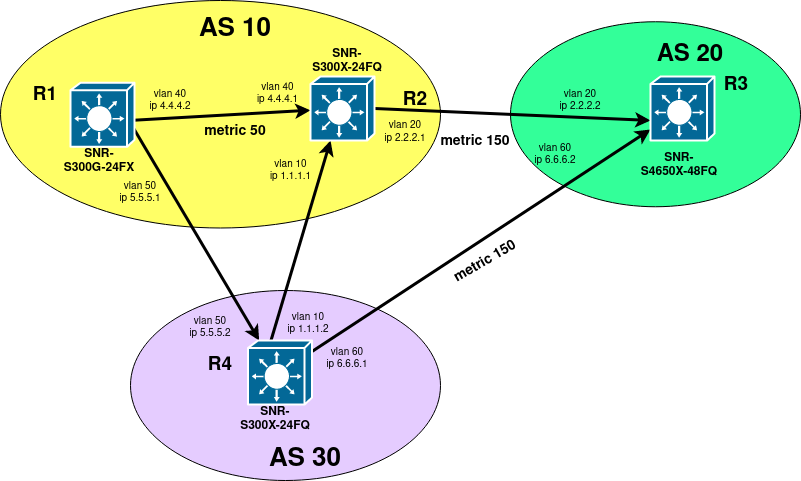
MED (multi-exit discriminator)
Атрибут MED (RFC 4451) предназначен для определения наилучшего пути, по которому другие AS могут взаимодействовать с нашей AS. Данный атрибут не локальный, он передается между AS. При сравнении с другими атрибутами он будет менее весомым. Если вам требуется чтобы всегда происходило сравнение значения метрики между разными AS, то необходимо добавить в конфигурацию команду “bgp always-compare-med”.
Конфигурация устройств
Вывод таблицы маршрутизации до добавления метрики
Атрибут MED по умолчанию равен нулю. Изменим данное значение, создав route-map и добавив его к необходимым соседям. Сущность route-map - это набор правил, по которым маршрутизируется трафик. После применения данной политики правил, изменится Next Hop для подсетей на каждом устройстве. К примеру, ранее на R4 для подсети 1.1.1.0/30 Next Hop был 5.5.5.1, но после задания метрики он изменился на 6.6.6.2. Аналогично изменился Next Hop на других устройствах.
Посмотрим выводы таблицы маршрутизации:
BGP community
Атрибут BGP community (RFC 4360) предназначен для маркировки маршрутов с целью последующей их обработки по специальным правилам. У маршрутов может быть несколько community. К примеру, на основе данного атрибута можно фильтровать трафик. Также, данный атрибут применяется для балансировки и распределения нагрузки. Принцип его работы почти аналогичен работе ip access-list:
Конфигурация Community на R2
Вывод команд
Как можно заметить из выводов команд выше, после настройки на R3 приходит атрибут Community 0:1111, а на остальные адреса данный атрибут не распространяется, т.к. они не подходят под созданный нами ACL. Маршрут может иметь и другие атрибуты Community, здесь разобран лишь пример самой простой настройки.
Weight
Атрибут Weight применяется в тех случаях, когда устройство имеет более одного выхода в другие AS. Логика работы данного атрибута очень проста - чем больше его численное значение, тем выше его приоритет. Важно отметить, что данный атрибут локальный, он не передается другим BGP-соседям.
Конфигурация R3
Атрибут можно указать непосредственно на соседе, а также это можно сделать с помощью route-map. Когда префикс генерируется локально, то по умолчанию его значение будет равно 32768.
BGP Confederation
Для масштабирования сети можно использовать функционал BGP Confederation (RFC 3065). Суть заключается в том, чтобы разделить большую автономную систему AS на несколько подсистем (подуровней AS). Это позволяет всем iBGP-соседям изучить все iBGP-маршруты в AS, не используя при этом полносвязную топологию между всеми L3-коммутаторами в сети. Для других AS конфедерация будет отображаться только под своим глобальным номером AS. В основном, BGP confederation используется на крупных сетях, где необходимо использовать крупную AS для захвата малых, более управляемых sub-AS. Важно отметить, что при настройке “bgp confederation peers” внутри конфедерации, нужно указывать номер sub-AS соседа. Рассмотрим пример настройки:
Конфигурация коммутаторов
Как можно заметить из вывода команд ниже, для R3 не будут видны номера sub-AS устройств в BGP confederation. Ему будет известна только непосредственно AS конфедерации, которая в нашем случае имеет идентификатор 100. R1, соответственно, видит в таблице маршрутизации только номер sub-AS, но если к нему присоединить еще одну BGP конфедерацию, то он также будет видеть только AS самой конфедерации.
Просмотр маршрутов и проверка связности
Route Reflector
Еще одним способом масштабирования сети будет использование коммутатора как Route Reflector (RFC2796). К примеру, если в AS будет использоваться большое количество устройств, то выглядит нелогично и неудобно прописывать множество соседей на каждом устройстве. Route Reflector будет выступать в роли "зеркала" и каждый коммутатор будет связан с ним только одним линком. При такой схеме мы получаем, что Route Reflector отправляет своим клиентам маршруты, а клиент не пересылает их дальше, т.к. является конечной точкой, ведь у него нет ни с кем более линков. RR-устройств может быть несколько, но в нашей схеме для примера мы будем использовать всего один. Логика работы этого устройства будет следующей:
- Если маршрут был получен от своего клиента, то маршрут будет отправлен всем.
- Если RR получил маршрут не от клиента, то такой маршрут будет отправлен только своим клиентам.
- Если RR получил маршрут от eBGP-соседа, то он пересылает этот маршрут всем.
Конфигурация устройств
В качестве RR был выбран коммутатор SNR-S300X-24FQ, а клиентами были выбраны три других коммутатора SNR-S300X-24FQ и SNR-S300G-24FX . Как можно заметить, нам не требуется соединять каждое устройство с каждым, т.е использовать Full-Mesh-топологию. Все клиенты подключаются к центральной точке RR и получают всю информацию о маршрутах через него. Это сильно упрощает конфигурацию, особенно на сети оператора, где в схеме участвует гораздо больше устройств. Убедимся, что каждое устройство доступно друг для друга и посмотрим их таблицу маршрутизации:
Выводы команд
На R2 и R3 таблицы маршрутизации выглядят аналогично, за исключением того, что будет другая подсеть directly connected.
BGP VPN
Часто для изоляции трафика используется VPN, а для их обслуживания создаются VRF. В данном разделе мы рассмотрим пример настройки MPLS VPN (RFC 7432). С принципом работы MPLS можно более подробно ознакомиться в нашем вебинаре. На схеме, разобранной нами ниже, будет рассмотрен только пример общей конфигурации MPLS-домена.
MPLS L3VPN-инфраструктура предполагает обеспечение изоляции клиентских IP-сетей в рамках VPN. VRF определяет принадлежность в VPN подсети за узлом клиентского оборудования, подключенного к граничному маршрутизатору. Интерфейсы граничных маршрутизаторов, обращенные к клиентскому оборудованию, логически связаны с персональными VRF. Для обмена маршрутной информацией между VRF разных граничных маршрутизаторов применяется протокол BGP, а сам BGP в свою очередь оперирует VPN-IPv4 маршрутами. Важно отметить, что VRF - локален для каждого маршрутизатора. Для определения VRF, в который требуется передать маршрут, используется уникальный идентификатор RT. Данный атрибут анонсируется в обновлениях BGP, как атрибут BGP extended community. А чтобы отличать принадлежность маршрута к определенному VPN, к префиксу подсети также добавляется идентификатор RD, который также передается в BGP extended community.
Конфигурация R1 и R2
Рассмотрим содержание таблицы маршрутизации на коммутаторах:
Вывод команды "show ip route"
Вывод команды "show ip route vrf VRF-A"
Вывод команды "show ip route vrf VRF-B"
Как можно заметить из вывода команд, мы изолировали данные маршруты между собой. Они будут недоступны для друг друга, т.к. находятся в разных VRF.
Подводя итог, BGP - основной связующий протокол в сети Internet. Де-факто он является стандартом для маршрутизации в сети Internet и, соответственно, необходим для большинства поставщиков Интернет-услуг. Кроме того, данный протокол может использоваться не только крупными операторами связи, но и большими частными IP-сетями. Есть множество способов и политик управления маршрутизацией, также изменяющих принцип работы протокола BGP. В данной статье мы затронули только основные принципы работы протокола BGP, его базовую настройку и примеры использования на коммутаторах SNR.