Привет, коллеги! Мы уже обсуждали возможности Вим по сбору статистики по файлу: как встроенное средство, так и простые команды подсчета слов, предложений, строк и чего угодно. Давайте разовьем эту мысль и научимся подсчитывать всё, что захотим. Например, часто надо написать текст с определенным числом непробельных символов. Или посчитать русские буквы. Или предложения. Или всё это в произвольном куске текста. А ещё научимся делать это на лету и отображать статистику в строке информации.
Сначала напишем функцию, которая будет получать текст и подсчитывать в нём всё, что нам надо:
function! Stat(s)
let as = split(a:s,'\zs')
let symb = len(as)
let nonblank = len(filter(as, 'v:val=~"\\S"'))
let alphanum = len(filter(as, 'v:val=~"\\c[a-zа-яё0-9]"'))
let alpha = len(filter(as, 'v:val=~"\\c[a-zа-яё]"'))
let cyr = len(filter(as, 'v:val=~"\\c[а-яё]"'))
let as = split(a:s,'\zs')
let digits = len(filter(as, 'v:val=~"\\d"'))
let as = split(a:s,'\_s')
let word = len(filter(as, 'v:val=~"\\S"'))
let as = split(a:s,'\_s')
let numb = len(filter(as, 'v:val=~"\\c\\d\\+\\.\\?\\d*\\([ed][+-]\\?\\d\\+\\)\\?"'))
let as = split(a:s,'[.!?]\+')
let sent = len(filter(as, 'v:val=~"\\S"'))
let res = {'symb':symb, 'nonblank':nonblank, 'word':word, 'sent':sent, 'alpha':alpha, 'alphanum':alphanum, 'digits':digits, 'numb':numb, 'cyr':cyr}
return res
endfunc
Мы используем функцию split, которая разделяет текст на части по регулярному выражению. Например, split(a:s,'\zs') разделит строку на символы. Число символов - это просто длина полученного списка.
Функция filter просеивает список через фильтр, оставляя только то, что подходит под выражение. Тестируемый элемент хранится в переменной v:val. Сравнение с выражением делает =~. Первая фильтрация отсеивает пробельные символы. Вторая оставляет только алфавитно-цифровые. Третья - только буквы. Четвертая - только кириллицу. Помните, что сам список уменьшается, поэтому потом мы делаем новый и отсеиваем всё, кроме цифр. Обратите внимание на символ \c, которые отключает учет регистра символов, если он вдруг включён.
Также обратите внимание на удвоение слешей!
Далее мы делим строку по пробелам (символ \_s включает сюда и конец строки) и отсеиваем пустые "слова". Получаем список слов и запоминаем его длину. Восстанавливаем список и высеиваем числа. Для них довольно сложное выражение: "хотя бы одна цифра, потом может быть точка и ещё цифры, потом может идти экспонента типа E-042".
Наконец, мы делим строку по символам, оканчивающим предложение, и считаем число предложений.
Всё подсчитанное сохраняем в словарь и возвращаем его.
Теперь создадим маленькую функцию-обертку, которая будет забирать весь текст и собирать статистику:
function! StatText()
return Stat(join(getline(1,'$'),' '))
endfunc
Здесь все строки текста склеиваются в одну через пробел, так что символ конца строки считается как пробел. Можете заменить $ на точку (.) и тогда получите статистику от начала файла до строки под курсором.
Наконец, сделайте привязки
:vmap bb "yy:echo Stat(@y)<CR>
:map bb echo StatText()
Вместо bb можете что-то своё, что там у вас свободно. Выделенное копируется в регистр y, а он передаётся на анализ. А без выделения получите статистику всего текста.
Этим уже можно пользоваться. Но давайте добавим подсчет на лету:
:set statusline = %{string(StatText())}
Словарь надо превратить в строку функцией string. Конечно, для большого текста всё это будет тормозить, зато для набора аннотации с нуля очень удобно: сразу видно, сколько ещё слов/символов/предложений надо вымучить.
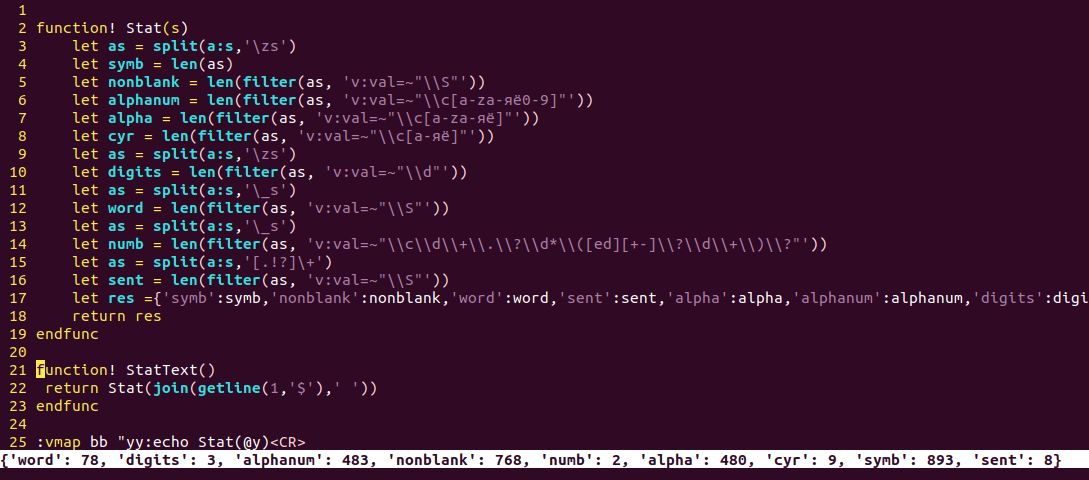
Недостаток, который я нашел, это неправильный подсчет предложений для выделения из нескольких строк. Последний перенос строки после точки дает пустое предложение, которое войдет в счёт. Это легко исправить, но не вижу необходимости. Также возможны сюрпризы, если у вас есть слова из не-букв или вы используете точки и восклицательные знаки для иных целей. Как на скриншоте. Но тут уж сами смотрите, что вы хотите. Еще одна мелочь: StatText заменяет концы строк на пробелы, возможно, вы не этого хотели. Это можно поправить, но мне это тоже уже не так интересно. Кроме того, сейчас мы не можем считать строки и абзацы. Но и это тоже легко делается при желании.
Удачи, коллеги!