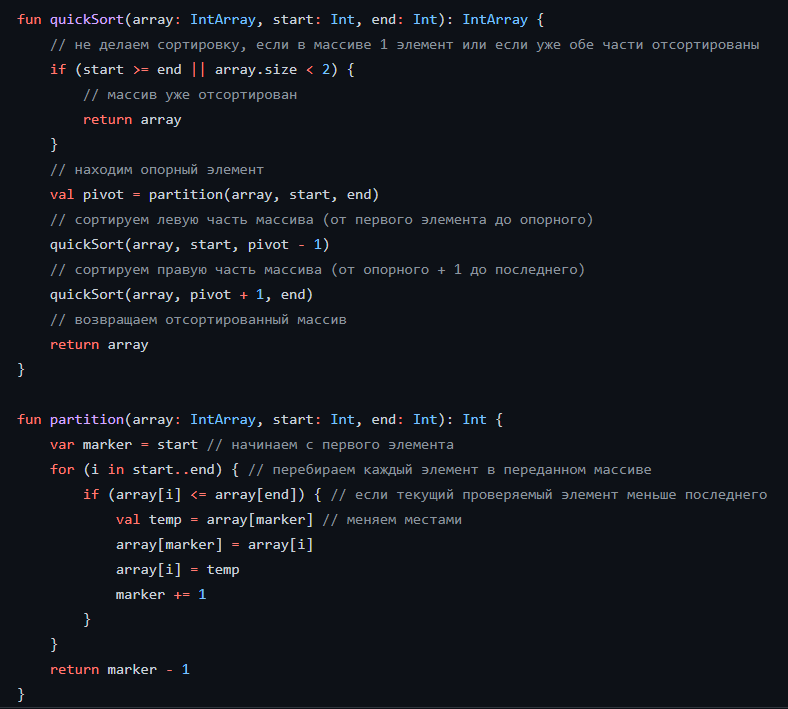
Заметки:
Эта сортировка намного быстрее сортировки выбором (когда делим пополам всегда). И используется во многих библиотеках (например, метод sort). Но и понять её гораздо сложнее. Тут уже прям придётся вникать.
- Сначала в массиве выбирается элемент, который называется опорным. В книге пишут, что опорным элементом надо выбирать случайный.
- Теперь у нас есть слева массив и справа. Сортируем их, находя элементы, который больше опорного, и, которые меньше опорного. Это процесс разделения.
Сложность зависит от выбора опорного элемента. В худшем будет O(n^2). В лучшем и в среднем — O(n logn). Существует ещё сортировка слияниям и она по сложности примерно такая же. Тогда почему быстрая сортировка считается лучше? Разница в константе: O(n) — это на самом деле c*n, где с — фиксированный промежуток времени, который обычно отбрасывается. И тут быстрая сортировка быстрее чем слияние, потому что константа у нее меньше.
А почему мы в других сортировках отбрасываем константу? Если сравнивать с бинарной сортировкой, то константа вообще не имеет значения, потому что и без константы гораздо быстрее.
Как выглядит сама сортировка: