Систематический обзор литературы обладает высокой научной ценностью, но техническая реализация этапов исследования обычно детально не описывает. Чек-лист дизайна исследования детально представлены на сайте проекта PRISMA http://www.prisma-statement.org/, (или здесь) а также в замечательной публикации: Середа А. П., Андрианова М. А. Рекомендации по оформлению дизайна исследования //Травматология и ортопедия России. – 2019. – Т. 25. – №. 3..
Упрощенно структуру статьи можно представить в виде:
Введение
-Целесообразность
-Цели
-Протокол и регистрация
Методы
-Критерии включения
-Источники информации
-Поиск
-Отбор исследований
-Процесс сбора данных
Данные
-Риск предвзятости в исследованиях
-Итоговые показатели
-Результаты анализа
-Дополнительные анализы
Результаты
-Отбор исследования
-Характеристика исследований
-Риск предвзятости исследований
-Результаты исследований
-Результаты анализа
-Риск предвзятости исследований
-Дополнительные анализы
Обсуждения
-Краткая оценка доказательности
Ограничения
Заключение
Финансирование
Более детальное описание структуры статьи по каждому из разделов можно прочитать в публикации Siddaway A. P., Wood A. M., Hedges L. V. How to do a systematic review: a best practice guide for conducting and reporting narrative reviews, meta-analyses, and meta-syntheses //Annual review of psychology. – 2019. – Т. 70. – С. 747-770..
Важную роль играет заполнение диаграммы, иллюстрирующей этапы исследования. Оригинальный варианты можно скачать с официального сайта http://prisma-statement.org/prismastatement/flowdiagram.aspx, также существует русскоязычная версия http://www.prisma-statement.org/documents/PRISMA%20Russian%20flow%20diagram.pdf.
Основные этапы
- Опредилитесь с целью исследования - это важно чтобы другие исследователи понимали, какие работы глобально представляют интерес;
- Определитесь с критериями включений публикаций, а также исключений;
- Необходимо выбрать базы данных в которых осуществляется поиск. PubMed - бесплатно и доступно. Scopus - требуется регистрация. ScholarGoogle - является так называемой "серой" базой данных, содержит множество ссылок не только на журналы и статьи. E-library - основная база русскоязычного сегмента. Остальные базы данных имеют ряд трудностей с доступом для обычных исследователей. Минимально приемлемым считается использование 2-х баз данных;
- Ключевые слова поиска.
Согласно мнению зарубежных журналов обязательным является использование "основных" баз данных: Medline, Embase, Cochrane library. Все остальные являются дополнительными.
1 Searching (Identification) [Поиск]
Задача поиска собрать максимальное число работ из выбранных баз данных, по ключевым словам поиска. Описание этапа поиска должно быть максимально подробным (как и всех этапов).
Существует несколько вариантов поиска. Наиболее простой в лоб - создание запросов на сайтах баз данных и скачивание результатов в готовых таблицах csv/excel, из минусов это затратно по усилиям, а также требует указание и формирования корректных запросов, обычно с использованием логики поиска и операторов OR AND и подобное. Помочь в этом могут инструкции к выбранной базе данных под названием query syntax. Главный недостаток этой методики - невозможность получить данные из Scholar Google простым решением. Весь первый этап легко осуществляется с помощью сервиса RefWorks, но доступ предоставляется только ВУЗам, заключившим с ними соглашение...
Альтернативные вариант - применение бесплатной программы Publish or Perish. Она позволяет выгружать данные в готовых форматах для программ реферирования ссылок (об этом позже) или таблицах csv, xls. Недостаток - отсутствие поиска по e-library, но можно импортировать данные первым методом. Для работы с базой данных Scopus, необходимо зарегистрироваться в ней и создать API Key, указать его в Publish or Perish и поиск заработает. Также поддерживается синтаксис поиска аналогичный таковым в поиске на страницах баз данных, детальнее https://harzing.com/resources/publish-or-perish/manual/using/use-cases/general-search. Ограничения по поиску в Scopus 200 статей, Scholar Google и PubMed по 1000. Еще одним недостатком является немного худший поиск, чем напрямую с баз данных (вывод сделан по количеству найденных публикаций). Но главное преимущество это сбор данных из Scholar Google и удобный формат вывода данных для последующего анализа.
Оптимальным является поиск по названиям, аннотациям, ключевым словам и полным текстам, начиная с 6 версии Publish or Perish - через графу Keywords. Все найденные статьи показываются ниже.
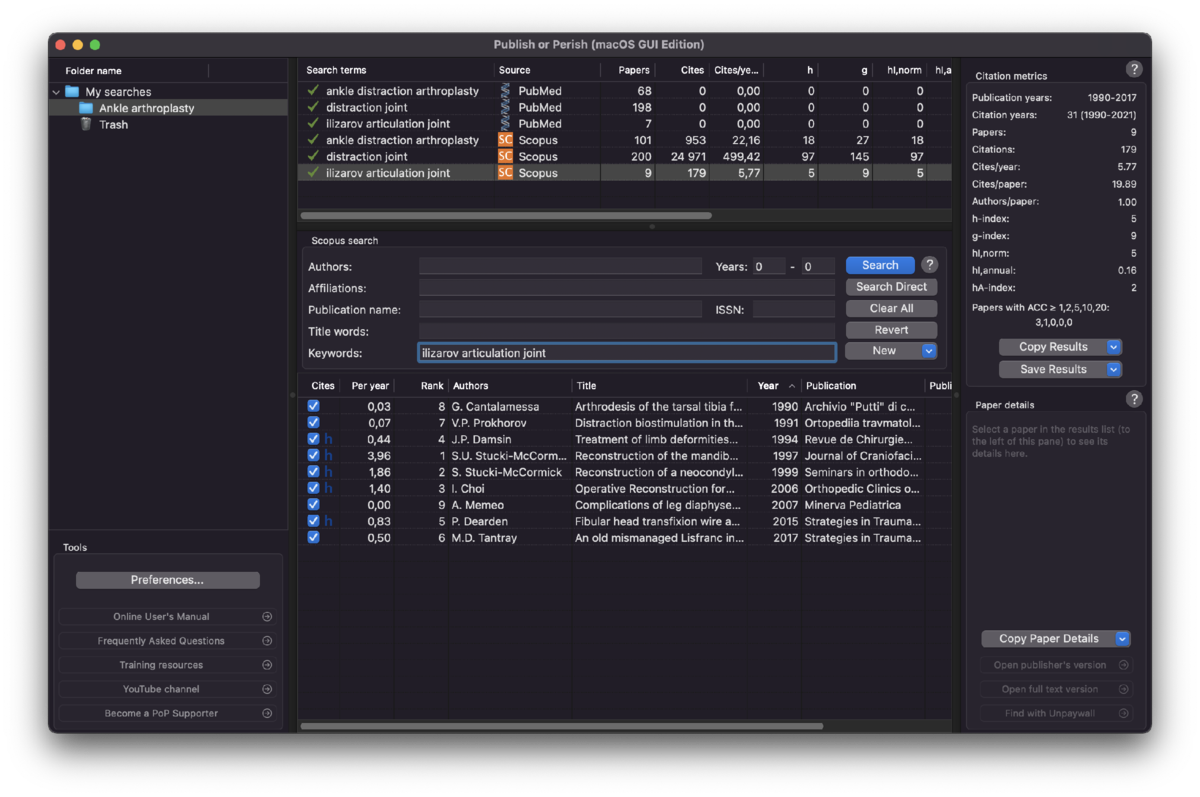
После сбора необходимых данных у нас есть первый этап в нашей диаграмме PRISMA - сколько всего публикаций мы собрали. Для окончания первого этапа осталось выгрузить результаты поиска и удалить дубликаты. Этот этап может быть очень простым, выгружаем все в EndNote и осуществляем все в 2 простых клика, получая полный перечень ссылок цитирований и убранные дубликаты, но EndNote платный и дорогой.
Альтернативный вариант использование Excel и фильтрации по столбцам. Можно удалить дубликаты и посчитать разницу между числом статей до и после. Либо использовать самописные скрипты на R, Python и подобное.
В Publish or Perish выделяем все наши запросы поиска, правой клавишей мышки, сохранить как, результаты в csv (можно и другой вариант).
После чего загружаем документ в онлайн сервис Rayyan (https://rayyan.ai/), там и удаляем дубликаты. Хотя большинство зарубежных специалистов пользуются EndNote (он платный).
2 Screening [Скрининг]
Состоит из нескольких этапов. Изначально читаем только названия статей и аннотации к ним. Обычно это делает несколько человек независимо друг от друга. Существует 3 варианта оценки каждой статьи: принимаем, не принимаем, возможно принимаем. Это основано на критериях включения и нашей цели и тематики исследования.
Осуществить это можно несколькими вариантами. Excel создаем отдельный столбец, где кодируем наши ответы 0 (-1) - не принимаем, 1 - принимаем, 2 (0) - возможно. Каждый исследователь заполняет в отдельном столбце.
Более красивый вариант использовать онлайн сервис (бесплатный, но есть и платные подписки) Rayyan. Необходима регистрация, после чего создается рабочий проект, куда добавляются исследователи и им поочереди показываются названия публикаций и их аннтоации, с возможностью принятия решения. Интеллектуальная система подсказок и прочие приятные удобные опции.
Затем проводим скрининг в Rayyan. Оставшиеся статьи после анализа названий и аннотаций отбираем в отдельную базу. Второй этап это чтение полных текстов материалов и отбор по полнотекстовым статьям аналогичным образом. Стоит уделить внимание методам и результатам в публикациях и сравнивать их с критериям включения/исключения, чтобы ускорить процесс.
По окончанию второго полнотекстового скрининга мы имеем уже окончательно отобранные публикации для проведения этапа анализа систематического обзора.
Коэна Каппа
Если в скрининге участвует 2 и более исследователя, необходимо проводить измерение межэкспертной надежности. К счастью есть онлайн калькулятор https://idostatistics.com/cohen-kappa-free-calculator/. Еще более интересный калькулятор для 2 и более исследователей https://www.graphpad.com/quickcalcs/kappa1/?K=2.
Коэна Каппа - это статистика, которая используется для измерения межэкспертной надежности качественных элементов. Обычно считается, что это более надежная мера, чем простой расчет процента согласия, поскольку Коэна Каппа учитывает возможность совпадения случайно (Википедия).
3 Analysis [Анализ]
Из оставшихся публикаций для анализа (обычно их не критически много) составляем таблицу, где указываем дизайн исследования. Это понадобится для выбора корректных чек-листов. Оценка качества публикаций является обязательным этапом систематического обзора. Единого требования к алгоритму оценки качества не существует, имеются различные чек-листы и подходы. Главное наличие этого пункта в исследовании, который к тому же поможет сократить число анализируемых работ еще больше, оставив только "высококачественные". Примеры используемых ресурсов для оценки качества:
После того, как сделали таблицу оценки качества публикаций и выбрали на основании этого то, что планировали - переходим к непосредственному анализу оставшихся работ. Извлекаем детальную информацию согласно критериям включения и вопросам исследования. Технически вносим данные в обычную таблицу. Указание трудностей и возможных факторов, влияющих на исследования будет плюсом.
Выполнение статистических расчетов по данным из отобранных работ переводит статью в раздел мета-анализа.
4 PRISMA flow diagram [Диаграмамма]
Блок-схема, в которой указывается весь путь отбора работ, а также исключения статей с указанием конкретных причин исключения и их количества. Ресурсы где можно нарисовать схему:
Rayyan добавил опцию создания диаграммы в последнем обновлении.